tl;dr check that the value of the first column is 1 to see if the checkpoint actually succeded. Bonuspoints if you feed the number of pages written back to the DB into the debug log ![]()
If that’s the case, than we’re fine ![]()
tl;dr check that the value of the first column is 1 to see if the checkpoint actually succeded. Bonuspoints if you feed the number of pages written back to the DB into the debug log ![]()
If that’s the case, than we’re fine ![]()
Yeah I realise I can see if it succeeded, but not what to do about it if it didn’t ![]()
Anyway there’s a build coming that disables auto checkpointing and runs just with the explicit checkpoints, and logs the result values (run with STTRACE=sqlite, it would be interesting to see). On my laptop this makes no functional difference, but it was fine before as well. If it does make a difference for @terry etc we can run with this, but as it is in this build it’s not “complete”… We only run the manual checkpoint after file update operations, but there are other operations as well that cause writes that would never get checkpointed in this case, so we’d need to rearchitect slightly. I just want to see if it matters/works first.
Here’s a Windows build, it’s unsigned, sorry, from my PR:
syncthing-windows-amd64-v2.0.0-beta.4.dev.2.g2d046930-noautocp.zip (11.2 MB)
I’d at least skip the point reset.
I will give dev2 a spin. As before, I delete the three index files and start the database from scratch
And please do add sqlite trace logging, either with env var or just check the box in the log viewer in the GUI. The result of the checkpointing calls is interesting, especially if it doesn’t help I guess.
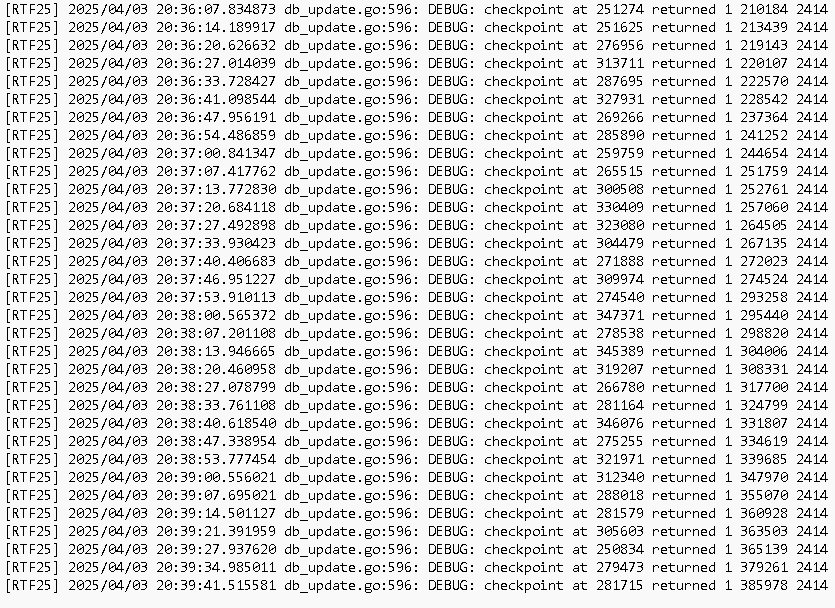
Treat me as a non programmer, this might be meaningless, if the checkpoint switched from returned 0 to returned 1, does it mean anything?
[RTF25] 2025/04/03 20:29:03.268932 db_update.go:596: DEBUG: checkpoint at 348124 returned 0 2733 2733
[RTF25] 2025/04/03 20:29:09.881655 db_update.go:596: DEBUG: checkpoint at 274273 returned 1 3171 2414
Only asking in case it’s something important. Might also be too early, but…
after 10 minutes running
It does, it means it could not complete the checkpoint, for some reason, so the WAL will grow more…
Interesting, looks like at this point checkpointing is not making any progress at all. I wonder if there is a long-running read transaction somewhere I’m not aware of. Could you possibly grab a support bundle? It will include profiling data and list of running goroutines which could shed some light
Just before I do, I restarted St, and it immediately said
[RTF25] 2025/04/03 20:44:21.797500 db_update.go:596: DEBUG: checkpoint at 296556 returned 1 587160 584712
Well, that’s a good sign I think, it should mean that part of the shutdown stopped whatever was blocking the checkpointing. The support bundle should be from when it’s been failing to checkpoint for a while though, ideally.
Interestingly, when it’s returning 0, it (the log entries) updates quite quickly, but soon as it goes to 1, the updates are slower, as if it’s waiting for something or does extra calculations
Just to add, I removed the databases prior to sending the bundle so it shows when it switches from 0 to 1
0 → checkpoint went through1 → something is blocking the checkpointOK yeah I got some good data from terry and may be getting some more, but I’m 95% certain the problem is that a pull has started on a folder, which becomes a long running select due to other database contention. I was thinking of optimising that into smaller batches anyway, but it has negative effects on things in the UI… (being able to see the full list of files that are queued for syncing, and being able to manually up-prioritise in that list)
Is it? This log would indicate that the checkpoint did not complete, even immediately after a restart.
I interpreted that as being during the shutdown rather than after the restart. E.g., we cancelled the pull during shutdown, and the checkpoint proceeded.
@terry See if this makes a difference, same scenario?
syncthing-windows-amd64-v2.0.0-beta.4.dev.3.gbeaaf05c-noautocp.zip (11.2 MB)
It’s not the most elegant solution but it might help pinpoint the problem.
Looking good, still ‘0’ after 5 minutes. It would have fell over after 2. Also looking like the wal is staying smaller

Would be normal to expect an occasional ‘1’ in the check point?

That should be fine. But it shouldn’t get stuck in this state.