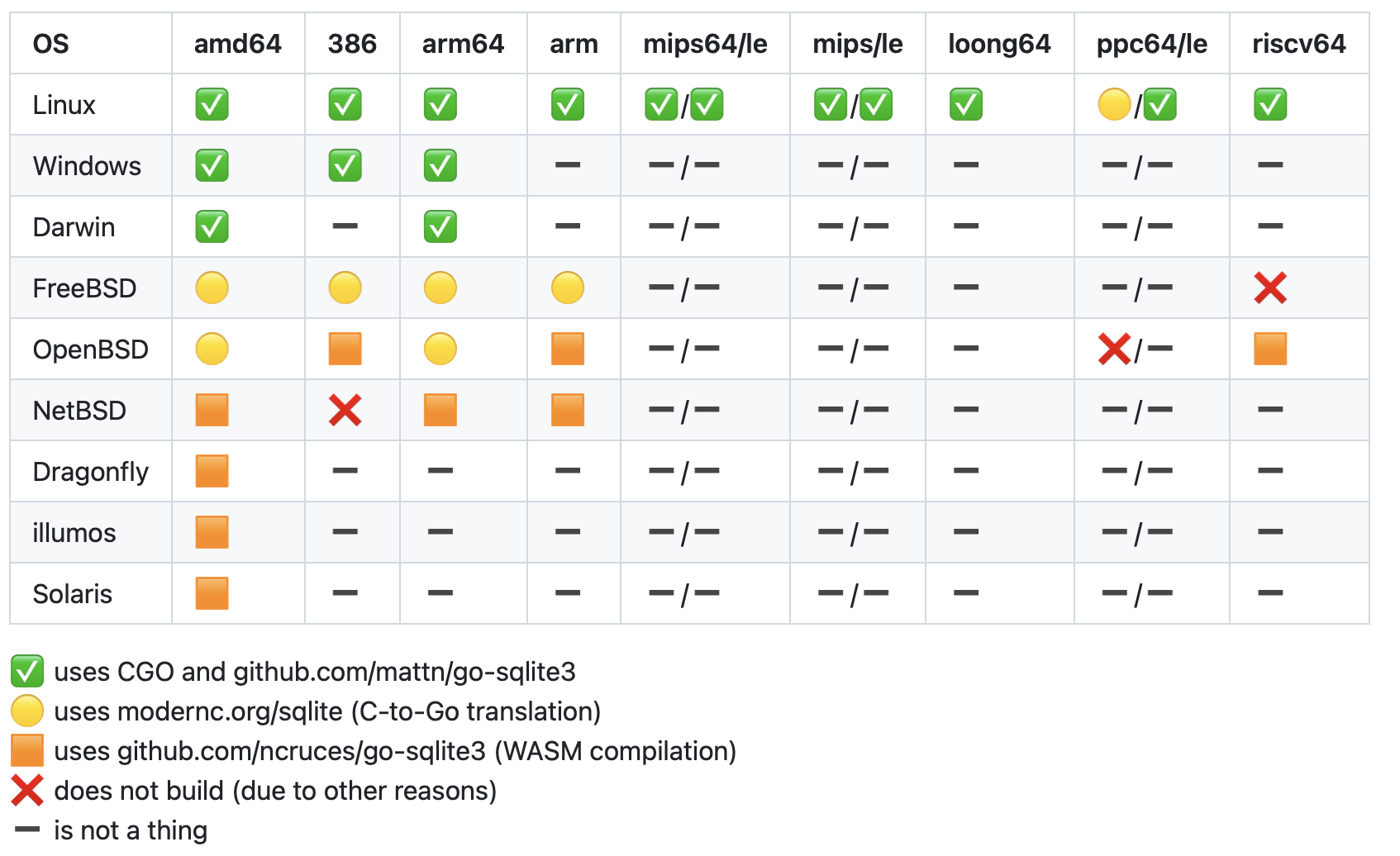
Zero testing on it from my side. You’re absolutely right of course, and I’ve put in some effort on building with zig, which unlocked a couple more native combinations. Probably we should not ship binaries with a driver we don’t do any testing on, and I’m half minded to even not ship binaries for the modernc combination either, instead leaving binary production for the respective os/distribution packagers…
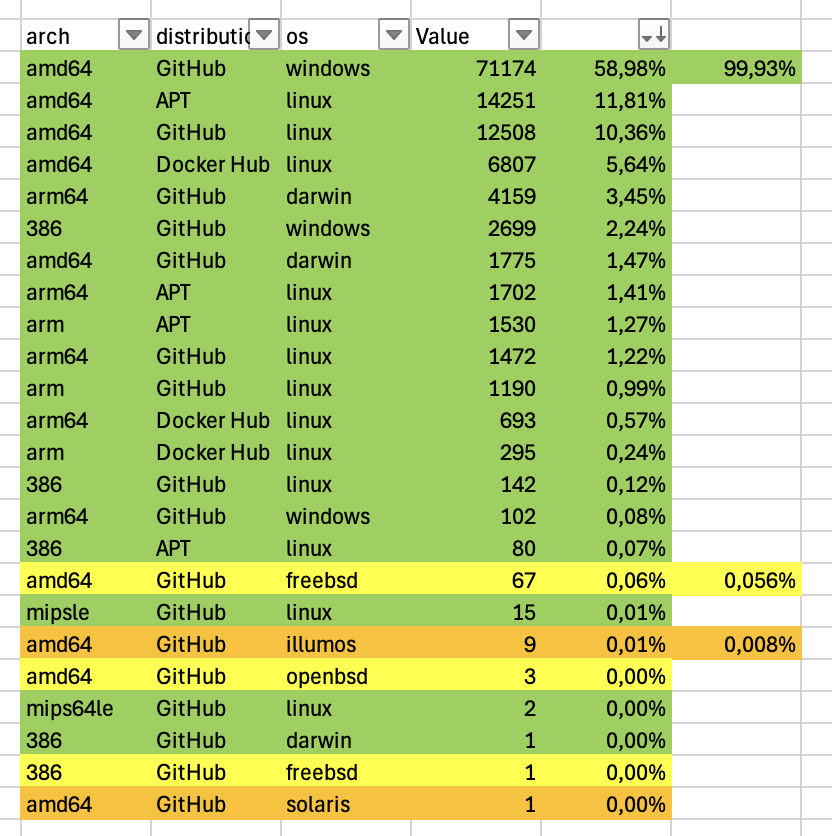
Looking at the usage reporting stats for users running our binaries currently, we’d have 0.056% on modernc and 0.008% wazero. I think the FreeBSD and OpenBSD users have native packaging, and illumos/Solaris folk are used to fend for themselves (speaking as a former one).
I guess we should at least have the modernc option in the code as it is probably a pain to build on Windows without it. Even if we don’t ship that combo, having it available to reduce friction for someone who just wants to contribute something non-database related and build locally seems reasonable.
That makes sense. I’m wondering whether it would make sense if Syncthing could display what database backend it uses then - just so one is aware of the limitation. This info might also help when users report bugs.
Note that thanks to MSYS2 is really isn’t a big deal (and definitely not a pain) to install a C/C++ compiler on Windows, though. You can then even get Go and many other packages for additional programming languages from MSYS2 and thus install/update your whole devel setup from one source - which is pretty neat.
Just one more observation about the new database. When a folder finishes scanning for the first time, the progress hangs at 100% for about a minute or so. Only after that, the scanning process actually completes. What is it doing during that time exactly? If there is still something to do, then maybe it would be better to have the progress stay something like 99% instead?
Cool, yeah, should be. That phase is typically limited by stat:ing each file in the folder. I think that may be a bit slower on Windows than other OSes, for reasons.
Just a comment, but if I use NTFS compression on the new database, it compresses by as much as 50% (e.g. from 120 MB to 60 MB). For the record, the old database barely compresses.
I think that’s an observation on the sqlite file format more than on anything we do with it, really. I don’t find it super surprising since the data is indexed multiple ways. I get about a 50% reduction when gzipping the entire database file, so it’s impressive to get about the same from fs compression. Possibly since your database is comparatively quite small there’s a lot of easily compressible metadata. My server database is 4.3 GB which gzips down to 2.6 GB.
That was what I feared. Fragmentation means that a lot of pages are mostly empty. As empty space is the easiest thing to compress, we can see a similar reduction in size for FS and the more advanced gzip compression.
The hard part is to automate this in our maintenance routine. As VACUUM is about the most expensive operation sqlite offers, we’d need to quickly evaluate the fragmentation level and only do this after hitting a certain threshold.