I tried using Syncthing in place of BTsync 1.4, but it fails!
I have two jobs for it and it failed at both:
Syncing content of several folders (between 2GB and 500GB) from my laptop to a backup server. Here, Syncthing might be working, but I will never know it because it occupies my C2D 2.5GHz processor to 100% to no end, and eats up 1GB+ of memory. Eventually, I have to kill it because normal usage of my laptop becomes obstructed.
Syncing content of Internal (6gb) an SD card (15gb) memory of my phone to a backup server and my laptop. Here, Syncthing fails miserably. It does absolutely nothing! Once shares are added and set up properly, all the android client does is get stuck at the rotating circle. For days.
I was hoping that if ST can’t deal with the job nr 2, it will at least replace BT in job nr 1. Alas, no such luck… So unless I am doing something really wrong (and I don’t see much of a chance for it), I am bound to go back to the BT sync 1.4
Nobody is forcing you to choose one or the other. They are different and work differently. Syncthing was never made a clone of BTSync, hence benchmarking Syncthing agaist it is meaningless.
For why it uses so much CPU: http://docs.syncthing.net/users/faq.html#why-does-it-use-so-much-cpu BTsync probably does not do all this hashing. For 500GB the first scan will need long, let that run over night Also memory usage will probably be better after the first scan. Also not connecting devices before the scan is done could help, syncing while scanning will not help for performance.
For the problem on android: tried killing the app and restarting? Your description sounds like you just left it open with whatever rotating circle you mean (not using it on android often, configured it once and not looking at the app very often, it just runs…).
Read this thread for an idea of what to expect running Syncthing on “underpowered” hardware like your phone or Core 2 Duo-based system.
The upshot is that the initial indexing of all the files is very computationally intensive on x86 systems without hardware crypto and on ARM systems because Syncthing cryptographically hashes all the files that you tell it to watch.
One of my Syncthing nodes is a dinky little ARM board (Allwinner A20) and the initial indexing of ~90 gigabytes took over 12 hours (I stopped counting). Since then, the performance has been reasonable considering the hardware.
When you make a change that needs to be synced, Syncthing will use as much CPU as you give it to hash the new data and encrypt with AES for transfer. I run Syncthing under nice and ionice to limit its effect on my workstation. Some have argued in these forums that Syncthing should “play nice” by default but I disagree. Any software should do its job as fast as possible. And cryptographic hashing and encryption takes a lot of CPU.
@Alex
Thanks for the suggestion. I left the Syncthing run (without other clients connected) on a quadcore server with 8GB ram and checked it today. After SEVEN days and nights, Syncthing was still running 70-80% of every core.
For the android problem - yes, I tried killing it. I reinstalled it now again, adding only internal memory to the sync. Now the Loading circle lasted only a minute. However, it is a moot point if it is so resource heavy.
@lfam
Are you saying a phone with quadcore 2.3 Ghz processor and 3GB RAM or C2D 2.5GHz is not powerful enough for Syncthing to work efficiently? I know comparing it to BTsync is getting old, but really - I have been using it for over a year and I have never even noticed it stressing the hardware at any point. Even a Raspberry Pi did just fine with tens of GB to sync.
How much data do you have there? Most peoples computers can hash around 120 to 200 MB per second per core, so that ought to be at least 400 MB/s on your quadcore. (I’m assuming you’re not limited by the disks here, as the CPU is loaded.) That’s around 33 TB per day, so I expect something else is going on here. Did you take a peek at the log output to see if there were any interesting errors?
Little bit Off-Topic: Im curious about how exactly BTSync handle the Hashing Problem?
Torrents also do have chunks, so i guess the mechanism is similiar to what ST is doing. Is this just an another/faster Hash algoritm?
I think because its centralized (the tracker bit) can potentially be the ultimate source of truth, hence they can do something simple as crc32 which is cheap.
I really must echo lockheed’s concerns. I too attempted to convert a shared folder between several devices from BTSync 1.4 to Syncthing v0.11.22 (23) and failed. I ran into two main issues:
At first, the initial indexing took forever. My share is around 300gb with 1750 files in just over 100 folders. I have thirty or so 5gb to 10gb files and it appeared as if Syncthing was attempting to “hash” four files at the same time causing massive hard disk thrashing as the heads had to seek back and forth between the four files. Changing the “hashers” value to “1” significantly increased the performance and lowered the hashing time (on multiple platforms/computers). I’m unsure how Syncthing determines the right number of “hashers” and the right number of files to hash at the same time, but is this expected behavior? One computer was sitting right next to me and I could plainly HEAR the hard drive noise (thrashing) practically disappear after changing the “hashers” value to “1”
Constructive suggestion 1: Perhaps Syncthing can be made to only “hash” one “large” file at a time (sequential read vs random read).
Once the initial scan/hash was complete, I ran into a second issue. Ram usage with Syncthing is, what I would consider to be, abnormally high. My share is around 300gb and after the initial scan (and a few application reboots due to configuration changes), Syncthing was reporting almost 800mb ram usage (both in the GUI and Task Manager). By comparison, BTSync 1.4 consumed less than 50mb on an x86-64 Windows platform with 8gb of ram. BTSync 1.4 consumed even less on an ARM Linux platform.
Speaking of the ARM architecture, I had deployed BTSync 1.4 on three of those little “Pogo Plug” Marvell Kirkwood ARM computers with only 256mb of ram. It ran very well, often consuming less than 50mb of ram and a measly 10 watts. Conversely, Syncthing on the same hardware sharing the same exact folder/files consumed close to 170mb of ram (almost all that was available) and then spilled over into the SWAP space. Once the initial sync was complete, it idled at over 400mb of ram according to the web GUI and HTOP.
Constructive suggestion 2: Ram usage needs to be brought down significantly to make this application practical for lower powered platforms such as NAS devices and other ARM powered computers.
To make a long story short, I really want to like Syncthing. I find the open source nature, the continuous development and constant stream of updates, the helpful community support and the great documentation all extremely appealing. Unfortunately, my application experience, so far, has been a little less than thrilling mainly due to the program’s massive resource usage.
The default is the number of CPU cores. This was decided a while back based on the (then updated) assumption that hashing is usually CPU bound. However if you have fast CPU and slow storage (say, a desktop computer with an i7 and a single 4TB disk or something) then the opposite applies. Also, while all current file/operating systems do some sort of file read ahead (or so I think), Windows seem to hate parallel I/O more than others… So perhaps the default should be revisited here.
Two things here; Syncthing is written in Go which is a memory safe and garbage collected language, while I think BTSync is written in C or C++ (I think). This means we will always have a disadvantage in terms of overhead - generally using about twice the memory we would otherwise need to. On the other hand we don’t have buffer overflows or memory leaks (not saying they do either, just that this is the language tradeoff) and a generally nicer environment for the developer.
Syncthing’s memory usage peaks at startup, when pulling changes, and when loading the GUI, due to how we currently need to walk the database to present the various folder summaries and so on. The database layer uses a sometimes unfortunate amount of RAM, which is something I’m working on. Go’s garbage collector releases unused memory back to the OS after about 5-10 minutes. So “idle” may mean something different to Syncthing than it does to you.
All that said, Syncthing should not use 800 MB when idling, and ideally not even at peak, for your workload so I can see how this would be a but surprising and off-putting to you.
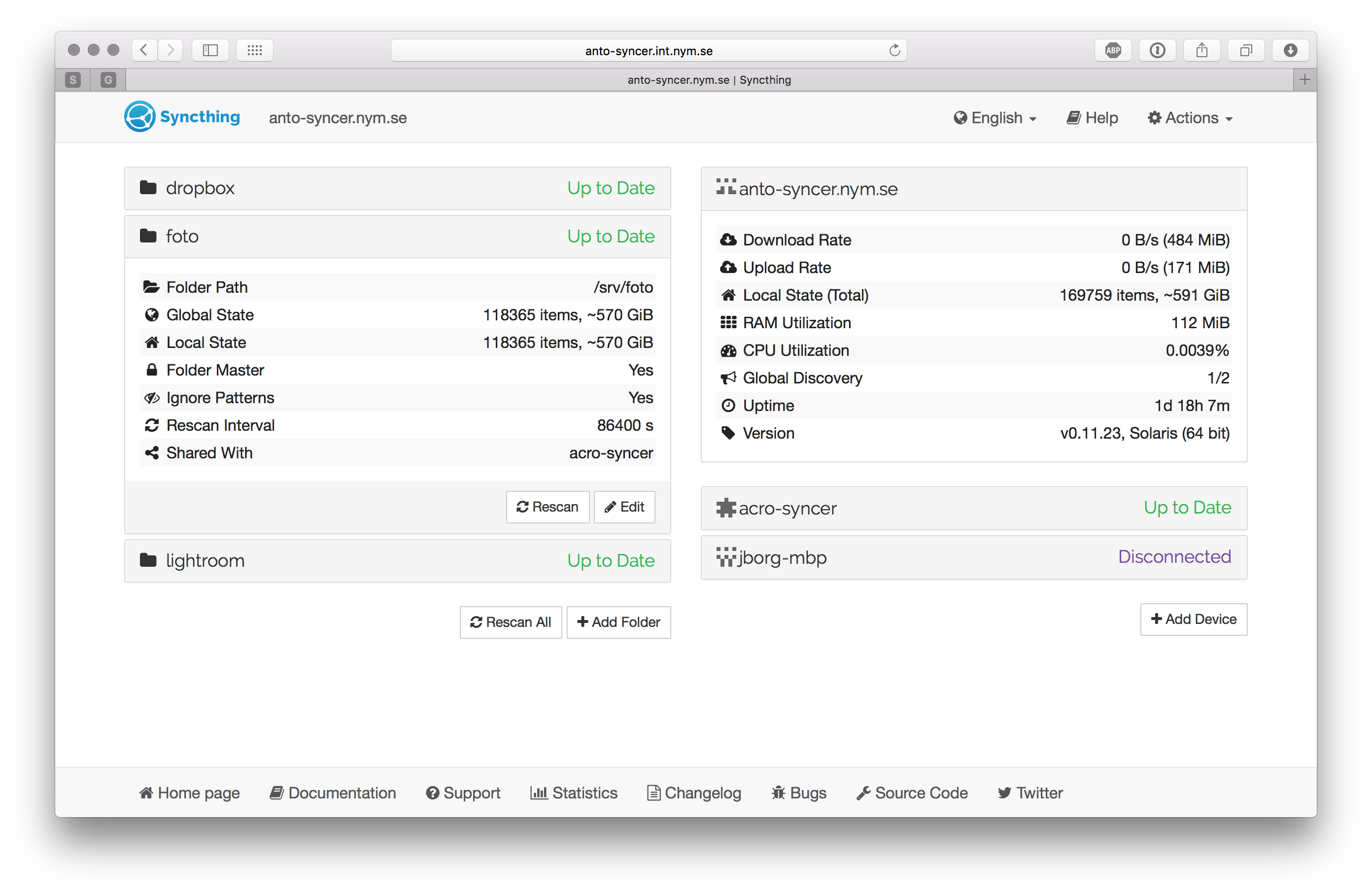
In addition to the amount of data, the number of files and number of (connected) peers may influence the usage, but my closest comparable setup looks like this right now:
“Idle” on that box is ~58 MB; loading the GUI pulls it up to the 112 MB visible above, leaving it open will see it shrink down again after 5-10 minutes. However note also that the large folder on that one has a very long rescan interval, making it idle more than it would with the default settings. In my case this data just changes very infrequently and I don’t mind the lag from the rescan, but using something like syncthing-inotify would have the same effect and still give you close to instantaneous sync of changes.
So in short, there are some things to tweak for sure. I’m not super happy with the memory consumption myself, and that’s something we’re working on, always.
Just out of curiosity: what’s the current status with sqlite and the go tool chain? You have mentioned here that it causes serious amounts of pain in the ass when cross compiling. Somewhere in the forum I have read that the situation has improved.
I think the cross compilation part isn’t really so bad. Both as you say it’s become better and it was anyway a solvable problem.
However I tried it out in a branch, and there were other issues. For one, for things like computing the number of bytes in a folder, doing it with a SELECT SUM(blah) FROM ... and so on was order of magnitudes slower than what we do currently (deserializing objects from the key-value store and doing the summing and so on in code). I may have fucked something up with the queries and indexes, but it wasn’t obvious to me why it was so much slower.
Second, a lot of our current code depends on concurrent access to the database; things like iterating over all items and changing some of them according to some criteria, or just being able to receive index updates from another device (changes the database) at the same time as doing a scan (reads the database). SQLite doesn’t support concurrent read+write access so this became really tricky and would require some major refactoring or things like buffering all things in memory or in a temporary database, then pushing them to the main db when there are no read transactions ongoing, etc. Also this wasn’t handled internally by the Go driver by blocking or so (which would make it somewhat easier to handle), instead some arbitrary database write would just get a ErrDatabaseLocked return at some random time.
All in all, SQLite was painful to work with.
The Bolt database shares some of the annoyances in terms of read+write transactions but not as bad so that’s where I’ve put my work lately.
I think you may be on to something here. SSDs are getting cheaper, but still the usual setup is: fast CPU, fast SSD for OS/programs and a big (slower) disk for storage. The shared data is calculated fast but is slow on concurrent reads/writes.
Suggestion: Add a slider with a few steps (slow computer - medium - fast - ultra environment) that sets the hashers/etc. in the background. This should show instant visible (and audible as @TDA1541 described) results.
Also the commit from @AudriusButkevicius that shows the scan progress will help.
Maybe you could use LIMIT, especially if you want to find a unique string in the DB with SELECT. Without the atrribute the DB scans the complete table looking for another row even if there is only one match which has been found already. This should also be used for UPDATE and DELETE if you know there is only one row with the ID you want to change.
Actually, the current default is the number of CPU cores divided by the number of configured folders. So, if you have four CPU cores and one folder, you get four parallel hashers for that folder. Two folders gets you two hashers per folder. Three or more folders get one hasher each.
The median user has three folders configured. We don’t know how many CPU cores they have, although I suspect four is a good guess for current consumer hardware and more than four is probably more unusual.
So in effect we’re usually running with a default of one hasher per folder.
The same median user has a CPU that can hash ~120 MB/s on a single core. That’s probably less than what a single modern SATA disk can deliver in sequential reads. But then the OS really needs to help out with readaheads if we’re going to be able to take advantage of more parallelization…
Perhaps we should adjust the defaults depending on the OS.
Windows and Mac => we assume a laptop/desktop class machine with an interactive user, so we don’t want to load things too heavily => default to one hasher.
Linux on ARM => as above, optimize for crap hardware.
What happens if the user sets copiers = hashers = pullers = 1 - does this force Syncthing to process each folder and each file sequentially or is this per folder? Because if it’s per folder and the average user has 3 folders this results in random and not sequential reads which is a lot slower on mechanical disks (~ 100 IOPS) than SSDs (> 1000(0) IOPS)

 Also memory usage will probably be better after the first scan. Also not connecting devices before the scan is done could help, syncing while scanning will not help for performance.
Also memory usage will probably be better after the first scan. Also not connecting devices before the scan is done could help, syncing while scanning will not help for performance.