Yeah, although just on a single device. It’s Intel Core i5-13500. The OS is Windows 10 though, and there are no issues regarding Syncthing’s performance there.
largest-file-syncthing-debug-database-counts.txt (2.5 KB)
All seems valid here. More and more hints that it was just initial index exchange, which lasted for many days for some reason (but maybe it is just normal?)
On Windows 10, it is like 10% of these P/E optimizations, and “Efficiency mode” is present but magnitudes less used by OS.
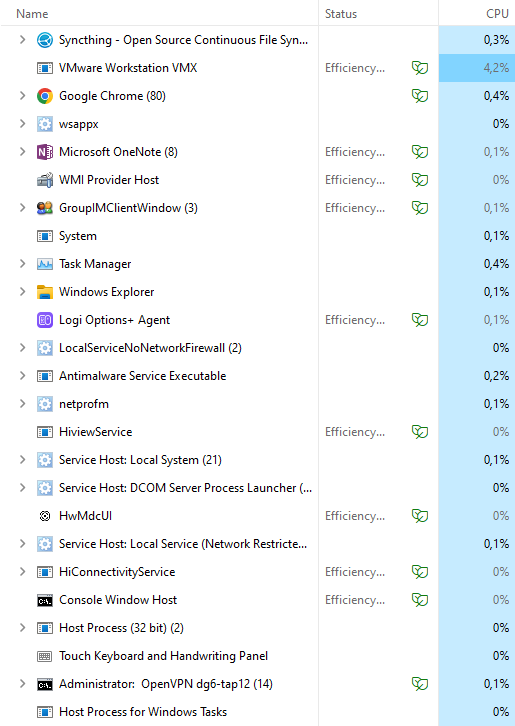
On Win 11 it can be like this with really half of the system migrated to background low priority high latency processing, including Syncthing when with low CPU priority.
UPD - I look forward to check if much less connections with larger single instance of cache will do better.
I’m not sure the memory is relevant here, as 1.3.0 was working great, of course it was kind of slow, but it was handling all this in the end (restart may took about 30 min to end all analysis, but after that it was okay).
On 2.x there’s so many concurrent processes that read/write the disks, that if you have HDD, it’s clearly a dead end. Having HDD is, by essence, the most common setup when you want large storage (multiple TB).
Here with only one active share:
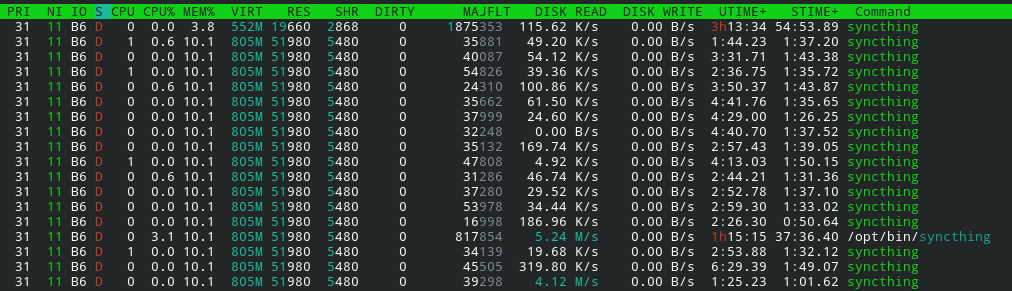
I understand that go will create as many processes as necessary for its tasks, but all those concurrent reads are clearly the bottleneck.
Again, I’m comparing 1.3 and 2.x, I know database was changed, but it’s not the culprit. There must be something else. And perhaps, we can’t do anything about it… Which would means that 1.3 should be kept alive for « bad » hardware.
Before using syncthing, I’ve used unison which is great, creates a hash for every file as does syncthing, but of course it’s not real time. Syncthing fixes this, along with great UI and simplicity. I hope we’ll find some options to limit Syncthing concurrency on disk reads.
Complaints with attached support bundle are sometimes resolved. Complaints without support bundle are mostly noise. Just sayin’
4 Likes
Just for clarification, you’re talking about Syncthing v1.30.0, right? Version v1.3.0 does exist too, but it is very, very old. Also, when it comes to v2, have you upgraded to v2.0.7? If not, then I’d suggest doing that first, as many performance improvements have been done in the meantime.
1 Like
Yvan,
-
When upgrading to 2.0.*, syncthing did the following change to config - maxConcurrentWrites in every folder was changed from 2 to 16. If you do have some concurrent writes task indeed, this may also change behavior, except all other upgrade complications.
-
Upgrade is 2-stage as it seems, a) DB convert on the first launch, b) then after, exchange indexes with all peers to create N-to-N database at each of the peers again. This second task is not well documented and in my situation it took several days as it seems. This is causing some load with not so obvious reason.
1 Like
everything is fine with that; it was initial index exchange indeed, just really took too long, maybe because of additional priority issue discovered
EDIT: FYI, my stats are x10 compared to v1 database. Fully vacuumed, >90% page usage. My details mentioned many times, main feature is that it is ~6 nodes for 2 folders of 500K files each, total size is 600G.
1 Like
Sorry, it was indeed 1.30.0. Latest one on 1.x branch.
And yes, I’m testing 2.0.7. As soon as there’s a release, I test it to see if it fixes it (for example the VACUUM memory issue may have been fixed, or I’ve removed the whole index-v2 to get rid of it).
Can I safely upload Support bundle here or somewhere else? When should it be exported? After a few hours, or right from the start? I know it was noise, but it may have helped in the provided information somehow. (edit: it seems to include personal information, such as folder’s id, devices’ id, and must be edited at some point).
[EDIT] as it turns out, Syncthing 1.30.0 has a lot of threads too, but not active on the disk. I’m testing other options from here.
[EDIT #2] pausing all remote devices seems to help a lot. I’ll see when it’s done.
Sure, I’ve set everything to the very least, maxConcurrentWrites to 1, maxFolderConcurrency to 1, hashers and copiers to 1. As in the low hardware settings.
For your second point, I’ve removed all database as it was crashing Syncthing with VACUUM command. But clearly the load goes nuts when there’s too many shares. I’ll try to pause all remote devices to see if it helps ![]()
Jacob, or the team,
to clarify the roadmap, I will greatly appreciate if you can tell the following,
-
How realistic do you see to start changing schema a lot, to take DB storage back to v1 days? Or you do believe that current one is well enough designed so it is only storage engine overhead itself? (indexes are 50% of it as it seems anyway, etc)
-
If one will want to continue key/value branch further supported, do you prefer it here, integrated into syncthing project as something considered still useful, or you will prefer it at more separated fork?
Thanks for replying, just idle thinking. I have some dependency on this great software and it helps a lot, however, in current state, it exploded way beyond any other solutions of this kind I know; at some installations, I feel it is OK, for example my personal one with 800M → 10GB is “I can live with it”, however I will not be upgrading half of devices, for sure. At some others, I I downgraded already, at one corporate place, I got like 5GB → ~200GB (just measured it yesterday for the first time) and it seems like I am not going this path. I would like to establish roadmap at least for myself.
EDIT & REPORT: despite of huge databases, migration at all of my instances was fine. I see lots of reports “taking forever” or like that - nothing seen on my side. This is really very very well done.
1 Like
That seems absurd, please post at least a syncthing debug database-statistics and syncthing debug database-counts so we can see what’s going on. Nothing private in that output.
That said, I don’t think it’s realistic to expect it to go back to v1 levels as that database doesn’t have any indexes, etc. My gut feeling says a <2x size increase for v2 compared to v1 is reasonable, and all my installations are within that.
If there are schema improvements to do, I don’t know what they are. Contributions welcome, etc.
There will be no further development on the v1 branch from my side. I suggest putting any effort for that into nailing down the problems with v2 instead, but if you want to maintain a v1 fork as an emergency measure that’s of course your prerogative.
1 Like
I need some legal steps for that, exploring the possibility already, no ETA. For now I can say that there are many peers (>30) for the same large dataset, with lots of files (10M+), but not so much data (<5TB). Maybe N-to-N storage scenario mainly exploded.
sure, (not me but I have some Go devs that may be assigned), but the question is, do you feel that it is of use to do it in this exactly repository, build platform, etc., or not.
Cool so very likely different profile than what we’re looking at so far. Maybe normalising the files table as suggested by @bt90 (I think it was) might help here.
No. If you do that, it’d be a separate thing.
If there is a clear diagnosis of what causes the performance issue for your use case in v2, I would suggest to invest that developer time in improving v2 ![]()
yeah, checked schema, not a complex thing indeed,
maybe it all was talked through already, just not sure if it is faster for me to read all the threads about design, or to just write what I see, but all I can see to improve is a short list so here,
- seems that files.name repeats all path, so maybe add files.parent_id, with reference to directory entry, and as a simple migration path,
for getting name of an item - a) if files.parent_id is NULL, then, use name, b) if files.parent_id present, concatenate and use the result. c) while indirections not done (tree walk),
for lookup of a file by name - a) lookup directly, b) if not found, split to directory names by separator and lookup from the tail (this type of lookup will be faster if no file of this basename present at all, no matter where, so you skip looking up directories which are present more likely).
(when migration finished, direct lookup can be skipped - EDIT - select count(*) from where parent_id is null == 0)
I am not sure as I have no feeling of the code, if these additional queries will slow down things considerably, but for large DBs, you are going to page misses with more data, so it can as well speedup things, no matter than *x more queries for a file-by-hash.
also, if you are in a directory walk, than you know the parent of all files in question anyway, so no need to do tree walk, just query for the parent you know already.
Absense of this may be my case as I have lots of long total directory+file names, too, at all of my installs. (not uncommon as it seems).
(wish I was Go dev, I am just not, C++/Java/.NET guy, will be unable to provide quality code in Go, sorry for that)
As it seems that as Jakob said it is fine already now, the “performance issue” could be just indexes, which were none in v1. If so then no real improvement in v2 is possible here. The only thing that escapes me why then v1 was fine with that 10M+ files instance, “without indexes”, whatever it means. There is a mix of large files, small files, large folders, small folders there - all was working just fine, with low CPU usage. If it was fine then, maybe it was fine design without indexes, but we cannot have v2 without indexes as it seems. So no any improvement in v2 will get it into v1 size back. That’s why I consider going on with fork of 1 for some of my installations.
1 Like
… well another db-size conserving space is as usual to assign an index to a smaller column; as the index contains the copy of the column, we can have a smaller (non-unique) index which is way smaller, but still speedups the query.
The possible implementation is the following: imagine files.name, you add column files.name4, with length of 4 bytes, and store first 4 bytes of md5 of a name there. And you do not add unique index on files.name.
When doing query, you do the following - WHERE name4=[4bytes] AND name=[full name], it is still 4million times better than without :), and often, single index query to name4 will resolve things uniquley, but even if not, you will have additional rare scan of a few records. Not a big deal. And the index will get smaller.
Drownback is that you are losing UNIQUE at all so it is up to you to ensure DB consistency. But not a big deal if app is properly designed.
Same on indexes for blobs of hashes, etc. (files_blocklist_hash_only)
4 byte hashing of the searches will be fine in syncthing and easy to implement
Sometimes this approach is a win, sometimes not. Not sure about here. I am not sure if you are encouraged enough to make DB smaller - these are niche cases after all. But the complains from NAS owners etc “now it just dont work” will not end without some progress here.
UPD:
All tables Percentage of total database… 55.3%
All indices Percentage of total database… 44.7%
ADDING:
.. then after, to make locality better, blob storage of hashes can be made a little more meaningful. Imagine id of a hash blob. Now it seems to be full entropy data. It leads to no locality in storage and indexing. Imagine you prepend 4 bytes hash of local parent_id (or 8 bytes of parent id for simplicity) for any of blobs. It will greatly increase lookup locality.
The problem is that you will be unable to compare and query for hash, but consider the following:
… WHERE hash4=[4 bytes of real hash] AND RIGHT(4,hash)=[full real hash], this will query just fine, that’s with the advice before to implement hash indexes instead of full uniqie indexes.
ALSO: I am not sure what “storage” key for SQLite is, but if it is the primary key, then always consider promoting something more meaningful to the primary key; with files table, something starting with folder_id maybe (not sure what locality is there), etc., also, sometimes, even better go without unique primary key - like, the “most primary” key is that 4 byte hash, and the rest of unique specification is going from the rest of AND sentences - but that’s DB dependent, not sure about SQLite.
(seems to be a huge offtopic here, should be in somewhere about schema, sorry…)
ALSO: if the app design is good, maybe remove all the foreign keys and just add the sync sentences? it pays off when the app is simple, like it is here.
UPD: I understand that will be no more DB migration for 2.0 as it seems so maybe all these are just for the future..
Trust me, we’ve been there, and nobody wants to go back to the v1 database design, which nobody could trust. The main reason we switched to SQLite was to eliminate that problem.
1 Like