I see this question is asked pretty often and is in FAQ, but I would like to make it a little bit more specific, so to understand whether I should use it for my use-case, or it’s not advisable to.
I have a huge directory which I would like to mirror (The Backup further in the text) to two or three remote servers, one of which I have on my LAN and others on the other locations I have access to. The backup process happens not very often, once a week. With data being just added up. Basically that’s some sort of archive for our team’s work projects, which are also synchronized either via git or Syncthing, or both (more on that later). Those projects contain such file-types as html, css, js, psd, sketch, images and other office type files. The weekly additions is expected to be within 10 GiB in size, and The Backup is cleaned up annually, moving about half of its size to a non-synchronized server with an SSH access (The Archive further in the text), so that we keep only this and last year projects.
The size of The Backup directory is expected to be less than 100 GB, but the number of files is unpredicted. With all that said, I have these questions:
Is this design encouraged with Syncthing’s architecture, or is it just a specific use-case I have to test on my own? There’s a Is Syncthing my ideal backup application? section in FAQ, but it barely answers this question. And it looks like a really useful scenario to me, since I want the directory to be synced as I change it, preferably automatically. That looks especially useful with remote hosts, which are less easier to manage.
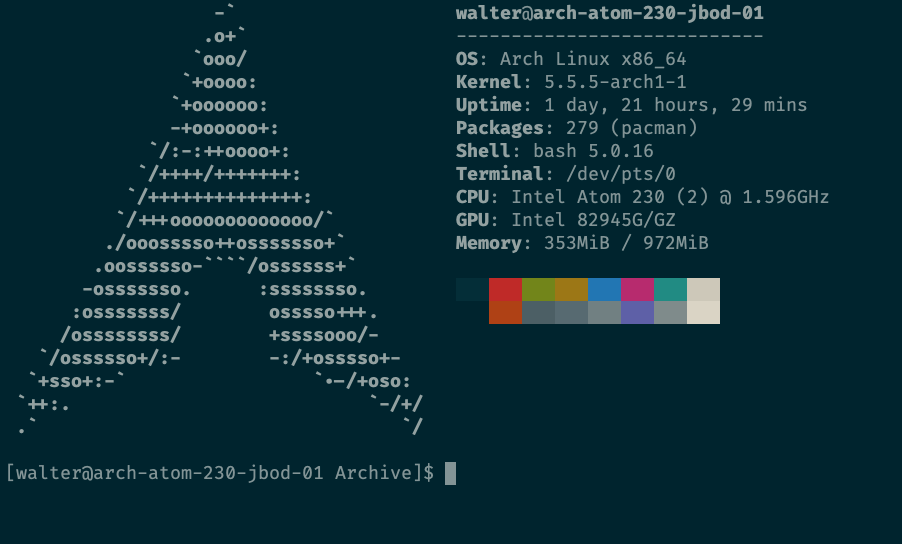
Does the frequency of files changes make any difference to the performance? I would like to use my old home-server (Pi-like performance, Arch Linux with Intel Atom 230 on the board 2 @ 1.6 GHz with 1 GB of RAM, just 150 MB is used right now). As I tested, 1 GB directory with frequent changes works very well. Will it work similarly well while being 100 GB in size and less frequent changes being made, with just 1 GB being added once in a while, in a root of the directory?
Will the number of writes to the disk be significant in that case? Having The Backup directory synced is very useful, but if the number of writes is significant (which I assume wears disks a bit quicker, am I correct?), then I should redesign the architecture to move directories from The Backup to The Archive more often, since the latter just lives on a remote server.
And for the syncing git thing is a bit of off-topic to my general question, but I put it here as well. I have some projects with git and some are not. If git is strongly discouraged to use with Syncthing, I have to redesign my directories architecture the way Syncthing will do the job only for sans-git projects, which would complicate my system significantly. I tested Syncthing and git with basic markdown notes and haven’t found any issues so far, but that’s not a proper test of this system. In case it’s only me who works with those git-directories, would it still be discouraged to use git? Will it be discouraged, if I work only from one machine and backup the directories with git the aforementioned way, with Folder Type setting set to Receive Only, and push changes from the original machine? If I understand the algorithm correctly, then there’s no difference for my original machine a remote Syncthing directory will mess my current working git directory. I found a thread with very similar question: Sync Large Directory with Raspberry Pi3 (Deadlock?), but it’s almost 3 years, so things could change a little.
I believe that should be of no difference, but for this use-case with The Backup we use macOS and Linux machines only, and Linux machine for The Archive, which may later be switched to FreeBSD.
Thanks.
P.S. The forum forced me to remove the links due to me being a new user, so I left just two, with no links to the documentation that I mentioned in the post.
It would synchronize successfully without issue, but any automatic synchronization is, as the FAQ states, not a backup in the commonly understood sense. If you’re looking for more than protection against disk failure, use an actual backup tool.
I can’t comment on use of Syncthing on low-power and low-memory devices. You may want to search the forum here.
When files are modified Syncthing writes to its database in addition to the files themselves. Whether this is significant is up to you.
You can synchronize a Git repository that’s only being modified in one locatiom. Problems occur during conflict resolution, because Syncthing deals with conflicts differently than Git does.
Thank you for your (quick!) reply, I would like to go into more details, if you don’t mind.
What do you mean by ‘more than protection against disk failure’? I thought that’s the main reason for backups. Do you mean the scenario when I would also like to keep versions (which Syncthing does, as far as I understand, but haven’t well tested yet). Or are there any other scenarios I don’t consider?
I’m going to test it anyway. May report it back here later.
If rephrased, my original question would be: is there a difference of syncing 100 GB folder with just one 1 GB directory being constantly changed and others being intact, but synced (so when another node is joined, it also gets the entire directory). Versus syncing just that 1 GB.
100GB of static files + 1 GB of dynamic files vs just 1 GB of dynamic files.
Or: 100 GB of static files + 1 GB of dynamic files vs just 15 GB of dynamic files (due to the directories’ logic difference and need to copy those extra files from The Archive).
I assume the answer would be it’s less resources with lesser directories (so 15 GB of dynamically changed directory is better than 100 GB constant + 1 GB dynamic option, but my assumption is based on nothing, hence I’m asking. (I hope I haven’t made that even more complicated.)
I’m not sure I understand what you mean here. Can you please confirm whether I understand it correctly:
Syncthing has a database, which grows (?) with number of files, but if the files aren’t modified that’s no difference to Syncthing (?).
Thank you, you answered my question here. But I have a new one, remotely related: I see Syncthing has an option for external version control system. I assume git can be here as well. Is it something completely different? It’s difficult for me to understand a use case for this external version control system.
The main difference between a backup solution (which Syncthing isn’t) and a synchronization solution (which Syncthing is) is that a backup represents a state in which the system was at a certain point in time, and using that backup you can (ideally) revert the system to the state it was back then.
Let’s say you’ve accidentally deleted a file. An hour later (or even a few seconds later) you slam yourself in the forehead and want to restore the file. With a backup solution, you can (if your backup is recent enough). With synchronization solution you can’t, because (if the solution works as expected) your delete is propagated to other nodes, and now no other node has the file you’ve deleted.
Or, say, you were hit by an encrypting malware that wants some bitcoin in exchange for encryption key, or some such thing. If you have a backup, you can restore your files from the time when they were not yet encrypted. Synchronization solution gives you no help, because (if it works properly) all your other nodes have replaced original files with the encrypted versions by the time you’ve noticed it.
So yes, as @JKing says, a disk failure is basically almost the only scenario where a synchronization solution such as Syncthing can help you restore your files. Other cases where Syncthing may be helpful when you’ve lost your files may include a fire, a flood, or an earthquake (provided that you have another node at some remote place that is out of the reach of the disaster), but Syncthing is not a backup solution, never aimed to be one, and will hardly ever be.
Thank you for such a great write-up on the difference! In my case I am looking to this kind of backup, but your comment made me realize I would also like to backup the files out of the Syncthing reach, which I think I can do on one (or even all) of the nodes periodically.
I thought a version control system can save me from removing a file or a directory. Am I wrong here? I came from Dropbox and Resilio Sync, both of which have this version control implemented. I thought this works similarly in Syncthing: when file gets deleted on another machine, it goes into the version control folder. The same may be with the malware encryption scenario you mentioned, if a remote node can keep different version of files, I assume I can restore them from there.
There is no version control in syncthing. It has versioning, which makes copies of files as they are modified but there is no optimisation or diffing or alike there, like in a real version control system. It’s a literal copy of the file every time it changes.
Also, syncthing’s database is forever growing (nothing is ever deleted), so changing 1gb of files and 1gb of files in a 100gb pile has a difference in size of the database. Also, if all files are always new (in terms of file path), the database will grow to infinity, and require more and more disk space and memory, which I suspect your weak device will not be able to support.
You can work around these things, but it will be manual maintenance you’ll have to do.
Also, the fact we use sha256 is clearly not weak device friendly, so you’ll probably have abysmal transfer rates.
What I do is have my home server running 24/7 as a Syncthing node that has almost all the folders I use Syncthing for, and then I have a backup solution on that sever, so that all the files it has (including the synced directories) get backed up properly.
BTW, my home server is a Raspberry Pi 3B with a RAID of several external HDDs attached, and it totally fits my needs speed-wise, for both Syncthing and other things I use it for. Now, granted, I only sync a couple Terabytes, and only between a dozen machines, so the load is very modest; you might find such a machine too slow for your needs (depending, naturally, on you actual needs and your actual machine).
That is the thing I have never heard of, and is terrifying! Is there a way of cleaning the database from time to time? E.g. removing the directory from Syncthing and adding it back again once in a while.
And what database size are we talking about? Is it GBs, or just MBs?
How many files are we talking about? What’s the size distribution, how much of them have the same content etc, etc? How many devices are you sharing it with? How long is a piece of string? These things are hard to calculate.
Yes, you can clean up the database, but the folder removal would have to be done on all devices at the same time, as removing and readding the folder on one device would just seed the database again from a remote device.
Ah, now I understand it’s difficult to calculate. But is there any estimate for a basic setup? (If such a setup exist.) Maybe any average stats available?
And does it mean any directory will be very large (uncomfortably large) over time? Should I expect all my sync directories to grow infinitely in a couple of years? In ten years? It looks like a design flaw from the first sight, if not getting into the deep complexity of the backend.
Maybe you have some more materials to read about this database thing?
I also have five Raspberry Pis, but mine are 2B. I believe they are not much slower than the 3B, without the Wi-Fi and Bluetooth I don’t need and are significantly cheaper (bought them used second-hand for one third of the price). I bought them to practice and learn DevOps things, like Docker, Kubernetes, etc. I thought of using them later for Syncthing as well, but it may or may not happen.
As for my personal Syncthing needs I use Intel Atom 230 based machine, it should use very little energy (more than a Pi, but it’s still quite a small number comparing to Desktop or even Server CPUs) and is more powerful (I read it’s 7 or 8 times faster than a RPi 3, but I haven’t measured that myself, I don’t know how). I haven’t metered the energy consumption yet, but I have plans to do that. Those boards I have are ITX size and they have from 2 to 4 SATA-2 ports, depending on the manufacturer. It’s quite useful for this sort of thing, since I don’t need to buy USB-HDDs and utilize those SATA disks I have right now. Though this solution isn’t future proof, since a SBC (Small Board Computer) is becoming better and cheaper, along the disks. In my case I just utilize the hardware I have easy access to, since the space is not an issue (currently I live in a huge house), but this is a small PC case size anyway, so I think when I move to live in an apartment which I have plans to, I may take one of the servers there, it can easily live in a lumber room.
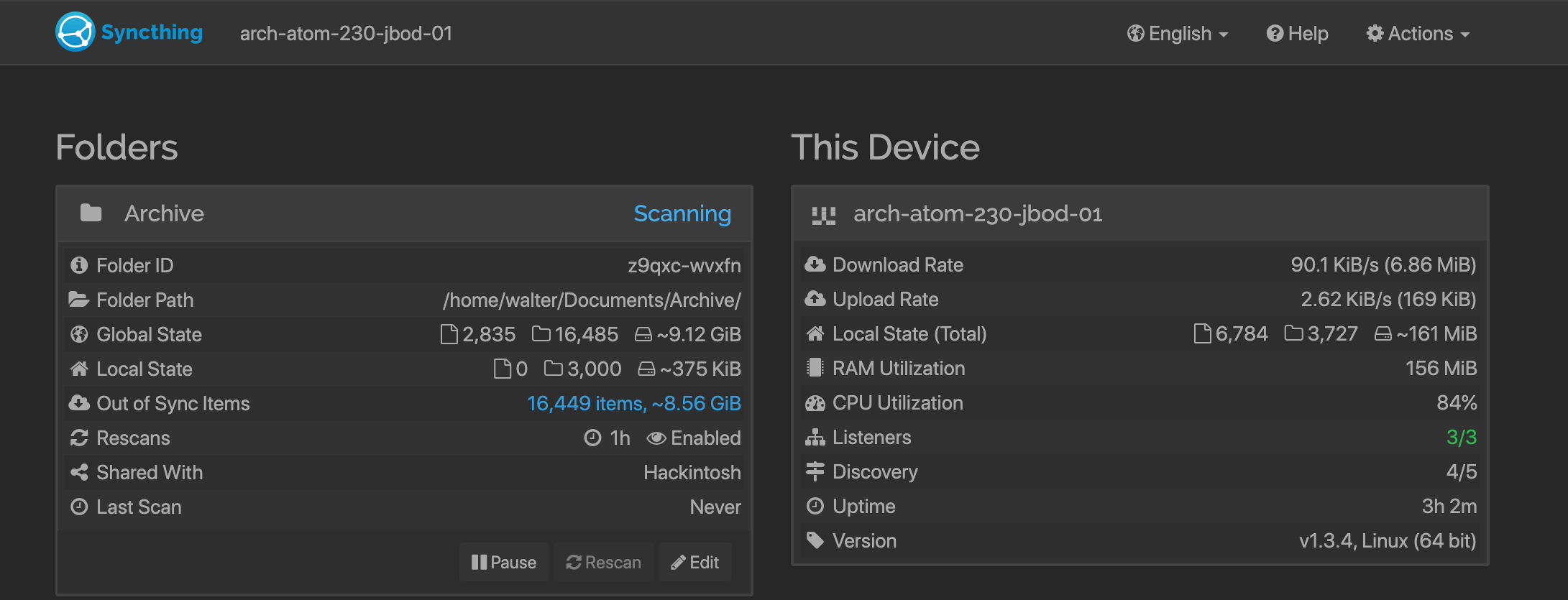
The aforementioned machine is currently syncing my 80 GB directory (finished scanning, to be correct, as I’ve transferred the directory over the LAN, via SSH), with the 156 MB RAM utilization and 84% CPU utilization.
When considering the CPU and I/O loads for changes to the data, it depends on the nature of the changes. If you add 1GB of new files then the “local” node will need to read all of the files (I/O), calculate the hashes (CPU) and some overhead saving to the database. Then the data will need to be transferred.
If the 1GB of added data is 10,000 new files, then the overhead for CPU, I/O and database will be higher, as will the data to send over the network.
If you have a 1GB file which is changed, the entire file has to be re-read and changed portions rehashed, then the changes sent over.
Seems you are mixing different things. Database will grow infinitely, if every time your filenames are different.
Worst case you have a manual way to clean it up as I’ve explained.
Versioning has nothing todo with a database, and is a policy decision. If you decide to keep every modification ever, then by definition you’ll have all the versions of all the data you ever. These things are configurable however. You need to decide how long you want to keep stuff for.
I am not going to do back of envelope calculations of database sizes of undefined datasets. If you want to know what database size looks for a basic setup, create whatevet you call a basic setup and look at the database directory size.
“Infinitely” is a strong word and theoretically correct when talking towards the limit of time. We’re talking bytes though here, per file. The name and a couple of fields of metadata, compressed.
There are setups where this overhead is undesired and we’re working on removing it. But it’s not commonly an issue.
Thank you everyone for your quick help, I couldn’t expect to have all my questions answered within half a day! What a wonderful forum software and people you have here!
Database
I had questions about the database you mentioned, but I decided to try to find it first, and seems like I succeeded, it’s located in the documentation: Syncthing Configuration.
My database is about 130 MB on both my macOS machine and my Linux server.
Resources Utilization
The directories I sync at this moment are:
133,809 Files, 16,490 Directories, ~77.9 GiB
352 Files, 86 Directories, ~13.1 MiB
6,435 Files, 640 Directories, ~24.5 MiB
I wasn’t sure about the 1st directory in this example, so I decided to ask about it here first. As a result after three days of testing, it works quite well. During the full scan it took about 85% of CPU (2 @ 1.6 GHz), and 156 MiB of RAM.
While idle:
RAM Utilization is 89.7 MiB
CPU Utilization is 0.29%
My i7-4770 PC consumes 55.4 MiB and 0.1% with the same set of directories. While CPU is obvious (8 @ 3.4 GHz), I wonder why does it take less RAM? It’s faster and more modern, but shouldn’t that affect its speed only?
With 3rd directory only (6,435 files) my MacBook Air with Arch Linux (2 @ 1.4 GHz) takes just 64 MiB and 0.1% while idle. And the database is 4 MiB.
So maybe this performance issue is a bit exaggerated, I thought this footprint is higher. Maybe it’ll accumulate over time, we’ll see.
Go is a garbage collected language, so when it does gc to reduce memory usage is somewhat out of our control. The fact one takes 50mb the other one 80 might just mean one ran garbage collection the other one has not.