Could we continue this discussion somewhere? I have a lot of large pdf that I don’t want to sync so I would really love this feature to be implemented.
thanks a lot
Could we continue this discussion somewhere? I have a lot of large pdf that I don’t want to sync so I would really love this feature to be implemented.
thanks a lot
Extremely unlikely to happen, for the reasons stated in that thread (but by all means, discuss away).
I have deleted my previous comment and try to post a similar new one. But the system tells me “An error occurred: Body is too similar to what you recently posted”. So I apologize for only pasting the images here
I don’t think it’s at all as straightforward as you think it is, especially with more devices involved and them not necessarily having the same ignore patterns.
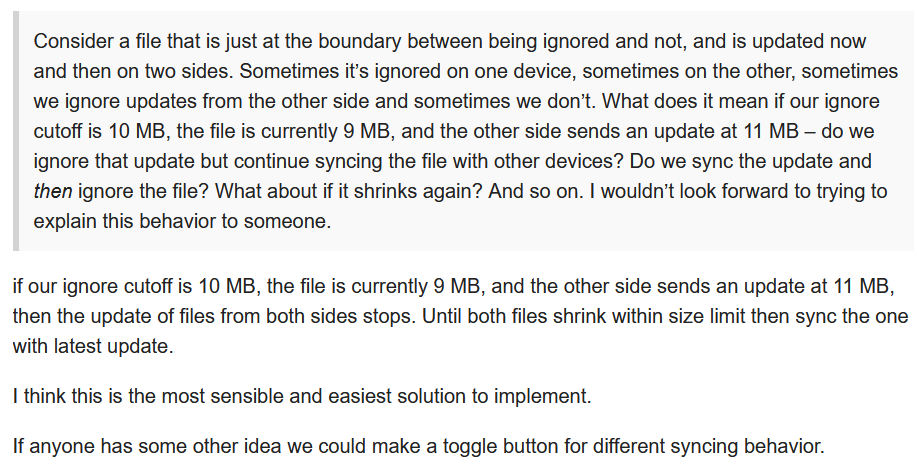
Even in your example, the file is suddenly ignored even though it’s just 9 MiB on disk. That’s not a state that can be explained by just looking at local data, and the scanner can’t know it when scanning for changes, etc, so it’s a significant sidestep from how ignores currently work in Syncthing. It posits that a local file is ignored based on a rumour of what another device thinks of it, which rapidly gets complicated with more devices and more updates.
really sorry if this is a dumb question. I admit that I don’t really understand the mechanism behind it.
I’m just wondering if it’s possible to implement a similar mechanism like how FreeFileSync handles ignoring large files. Even if it isn’t perfect across devices, it would still be super useful.
Thanks! @calmh
@calmh I thought of another approach to manage file with modified size. if a file is modified it should be considered as a new file. The old file on all device should be deleted and the new file should be synced across all device. If the modified file exceeds expectation. It should remain only on the device that performs the modification, and all other device should consider the old file is deleted and delete the old file in their own folder, and consider the new file is too large and ignore it.
That would be something, but I’m not sure it would be what I expect from Syncthing.
You can script a workaround for this:
filename.ext to filenameLRG.ext) and then deletes the original fileThanks a lot for providing this alternative! That could certainly work, but it would involve modifying or renaming most of my files in my 800GB vault. I’m concerned that such a disruptive process might introduce unforeseen bugs that could corrupt my files, and it feels a bit odd to see all of my files renamed. @chaos
I simply took this from other syncing alternatives. It doesn’t seem to conflict with any existing features (or maybe I am wrong). May I ask why this might not be what you are expecting from syncthing? @calmh
I won’t speak for anyone else, but for me, this sort of behavior would be confusing and difficult to predict. I expect Syncthing to sync files. The use case you describe would be very odd for — IMO — nearly all current users.
It seems like a very specific mechanism for your use case. In no other case does ignoring a file result in it being deleted anywhere.
I think you also have the complication that ignore patterns on different machines can be different and you can get into a situation based on which machines connect with which other machines and what are the ignore patterns where things can go wrong.
I personally can’t think of a better way for syncing with file size ignore. I reckon people having no trouble understanding the current ignore could understand this file size ignore, as it is very similar to the ignore pattern that already exits. And people always have the option to use syncthing without any ignore.
It doesn’t have to be deleted. If a ignore file within certain size range is set it could simply ignore all the file within that size range. If a modified file is within that size range, let’s say too large, it could be ignored on the device that modifies it. Since other device doesn’t see the modification on that device, they would consider the file removed, or if “In no other case does ignoring a file result in it being deleted anywhere.”, they could simply sync another copy of original file to that device, and people could delete the original file manually so it is deleted across all devices, deletion automatically just makes life easier. Then in this case, the only file remains is the modified file being left on the device modifies that file.
ignore patterns on different machines can be different? thank you I didn’t know that. Then I would say the ignore pattern would only apply on the corresponding device. So that specific device doesn’t send or receive large files. If people wants to keep the syncing consistent. They could copy and paste the ignore pattern across all their devices
Right. So that’s the problem. I have 3 machines. Machine A, B, and C.
Machine A has no ignore pattern. Machine B has a 5GB maximum ignore pattern. Machine C has a 10GB maximum ignore pattern.
This case is substantially different than other ignore patterns because it permits different files on different machines with the same filename to exist without the other machines knowing.
Here’s another case..
Anyway, there are a lot of “edge cases” which aren’t really hard to imagine where conflicts will arise with “undefined” resolutions.. and unexpected results…
So the question is
How does B manage the newly synced 3GB file.txt?
The answer from freefilesync
I reckon both solution could work pretty well
Anyway, there are a lot of “edge cases” which aren’t really hard to imagine where conflicts will arise with “undefined” resolutions.. and unexpected results…
Exactly, that is the reason we start this discussion, to find and resolve as much unseen conflicts as possible, so that if developers actually set their mind on this feature, it could be easier to start
If there are any other unseen issues please post it here so we can resolve them together!