Good afternoon! First, thanks to all the Syncthing devs for working on such an awesome project! In the past, I’ve used Unison as my file synchronization solution, but I’m finally switching to Syncthing because it looks better and more mature in just about every respect.
My primary use case is a large (but not massive) dataset of about 11 Tb (and growing) full of video data and associated project files/assets:
- I have two main nodes, each running on FreeBSD with ZFS. These machines are identical, and have 64GB of ECC RAM, 8x x86_64 cores, and 10gbps ethernet.
- Most of the time they will be running at separate sites, with a (slow) VPN connecting them, in which case we want to prioritize the real time synchronization of small files during the day (probably artificially throttling the pipe) while allowing large files to saturate the pipe overnight.
- Occasionally, at the beginning of a new project, one of these machines will be physically transported to the other and plugged into the same 10gbe switch in order to receive some very large changes which would be impractical to transfer over the VPN.
- In both cases, we want to be able to efficiently fill the available network bandwidth as necessary, unless the underlying storage is the bottleneck, in which case we want to saturate the disk throughput until the transfer is done.
What I’m observing:
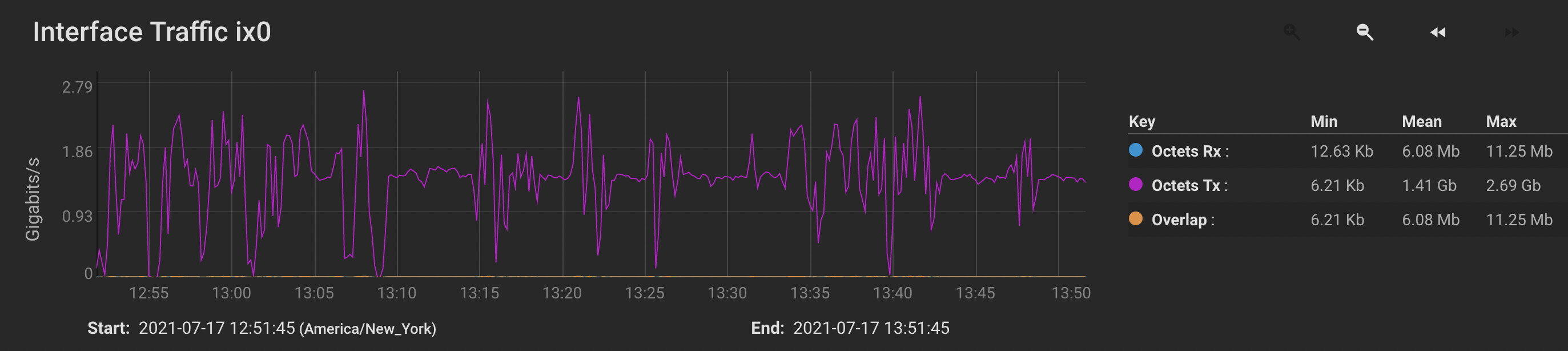
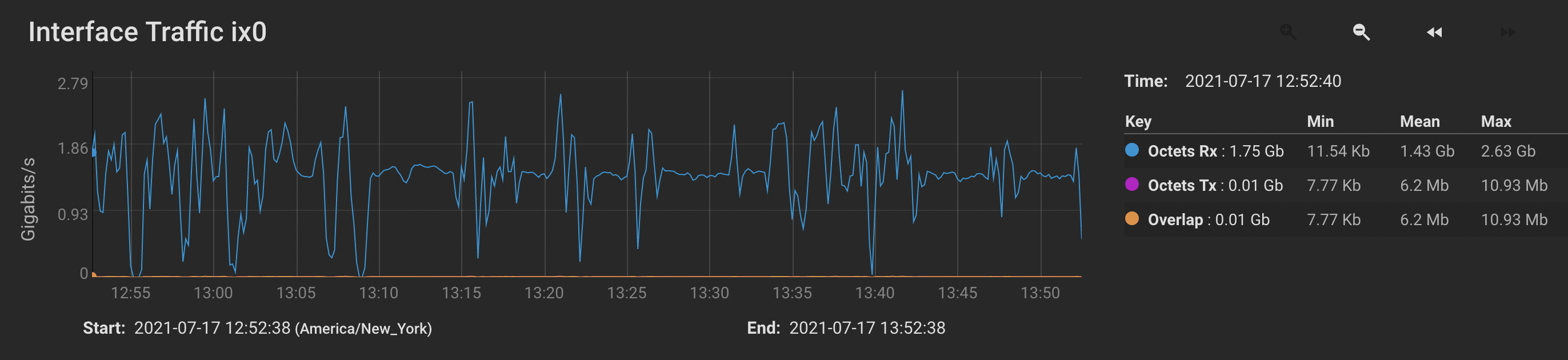
- Bandwidth between the two machines is very erratic and rarely peaks at what I think should be the maximum throughput.
- Transfers seem to pause for seconds at a time.
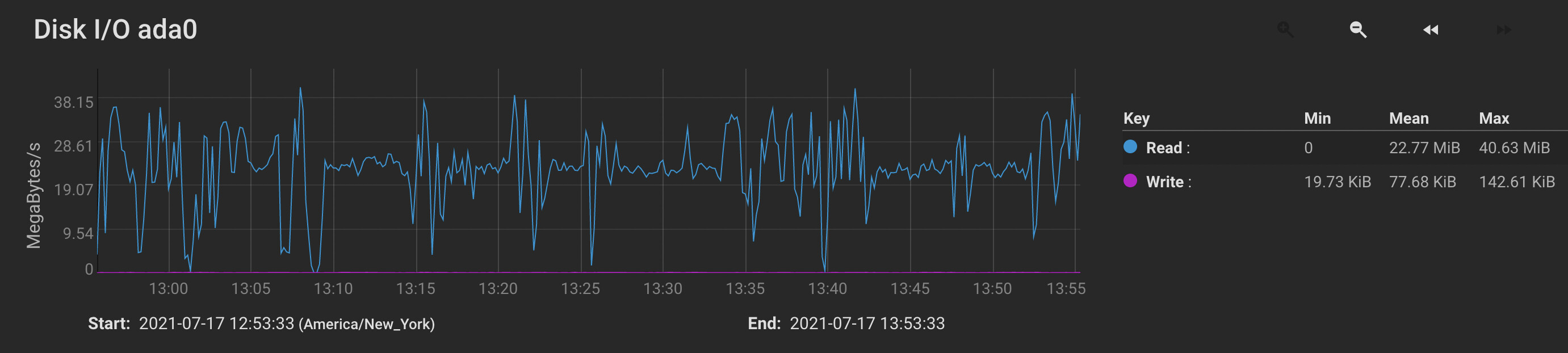
- I believe the receiver’s underlying storage write throughput should be the bottleneck at around 400 megabytes per second. However, in practice the receiver’s disks are underutilized.
Things I’ve already checked:
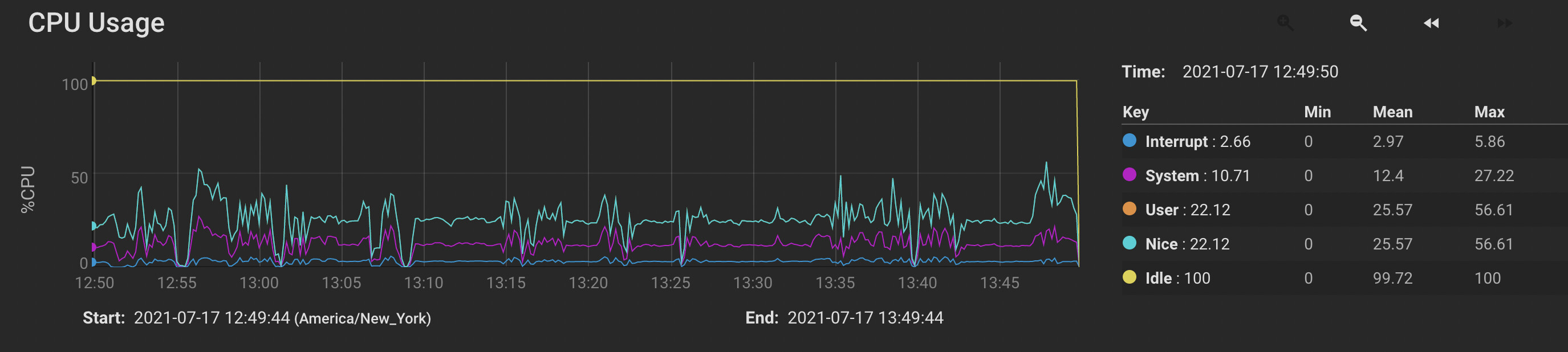
- CPU is underutilized. Max cpu percentage is 50%, system load average is less than 3.
- I’m running Syncthing inside of jails on both sides, with VNET bridged networking. It’s not great, but iperf3 shows me about 7gbps of practical throughput over the bridges between the jails, so the network should not be a bottleneck.
- I’ve tested the performance of the underlying zpool pretty extensively. (I really think it should be the primary bottleneck.) However as described above Syncthing is unable to saturate the disk throughput.
- For comparison, a simple remote tar/NFS job between the systems seems to be able to come much closer to hitting the maximum throughput of the disks.
Things I’ve attempted to optimize with Syncthing:
- Tried QUIC vs. TCP. (Should go without saying, but relaying is disabled and all connections are direct connections.)
- I changed setLowPriority to false.
- I have tried setting various “max” values higher. In some cases it was difficult to find clear documentation on what they meant, so I’m not sure if I’m helping or hurting myself.
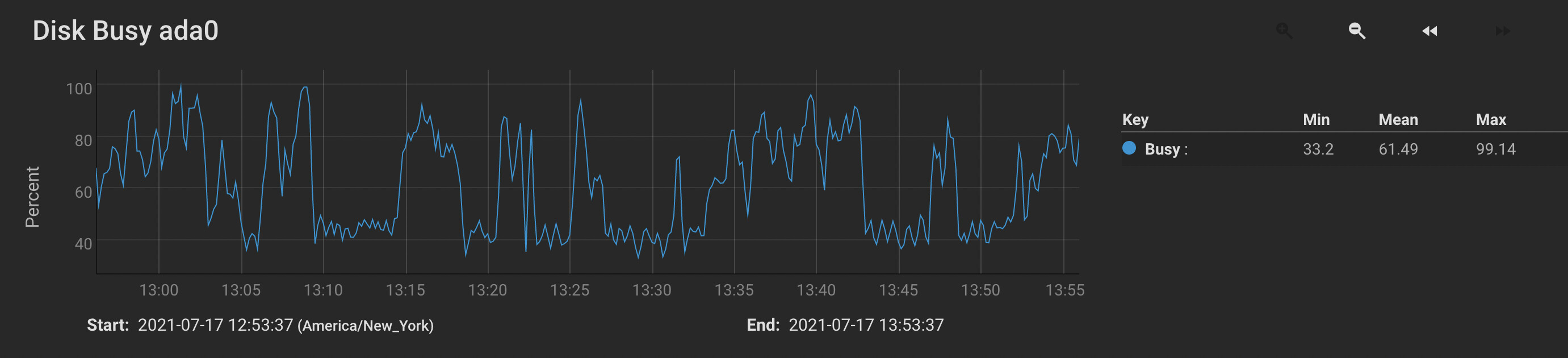
- I think I managed to improve the situation when I adjusted pullerMaxPendingKiB to 524288 and maxConcurrentIncomingRequestKiB to 524288 on both sides. (See just after 12:50 on the graph below.) However, while the receiver’s disk utilization is now peaking (occasionally) at 100%, it is hardly sustained, and still seems to quit writing altogether for multiple seconds at a time.
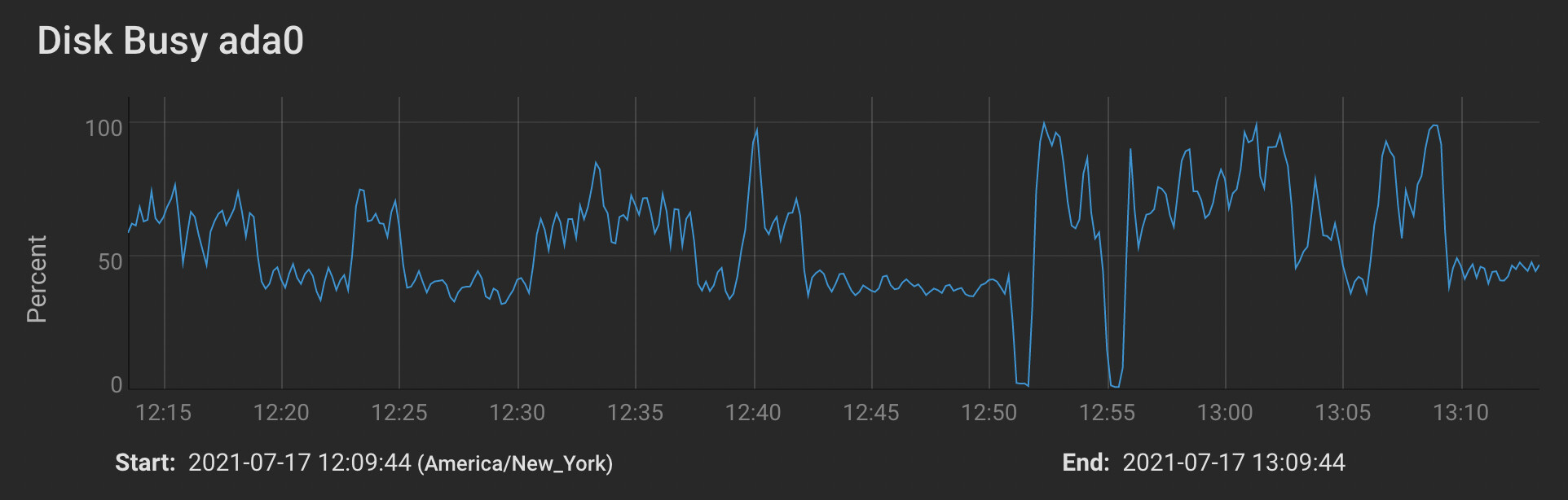
Given all of the above, could somebody who understands Syncthing’s internals give me some pointers on how to optimize this configuration? Where might there be bottlenecks I’m not considering?
Again, I’m really impressed by Syncthing in many respects, and I am excited to put it to some good use here.
Thanks very much for taking a look!
–Alex Markley