An opportunity arose at work to test out syncthing. Syncing 15.9 million directories holding 85 TB of data between two servers across the Internet. Would it be faster to attach a disk array to one and then ship it to the other? Yes. But what fun is that?!
The source server is 24 core, 128GB of ram, with 24x7200rpm SATA drives in a software raid 6. The target is 32 core, 256GB of ram, with 20x enterprise ssd drives in a software raid 6. Both servers are AMD EPYC cpus. Both servers are connected at 10 gbps and can sustain 5 gps between each other over direct ipv6/ipsec vpn connection. The servers are configured to connect directly, rather than through relays. We’re stuck with the hardware we have, and had a limited time window to optimize the hardware and operating system.
So far, it’s working. 32TB is successfully transferred in the past month.
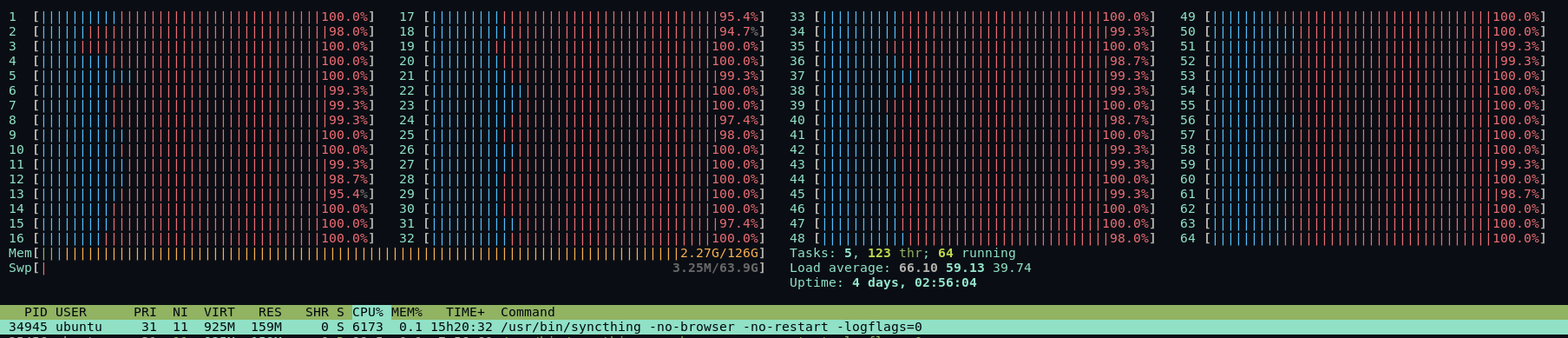
Syncthing, unison, and rsync all encounter the same problem: trying to enumerate the directories before syncing. Syncthing is consuming between 4-8 cpus at 100% all the time, between scanning the top level directory and actual data transfer. Scanning is set to 999999 seconds to avoid the scan penalty. The source server is constantly maxed out on disk i/o where the receiving server is real busy with write i/o. The receiving server has the added cost of writing the md array as well as the stream of data from syncthing.
Both servers are using ext4. We found the hardware is the limiting factor more than filesystem. We also found tuning the linux kernel to handle the i/o worked the best. The other limiting factor is likely the SATA bus on the sending server. We found swraid is faster than hardware raid so far.
I’m not sure how to make syncthing use more cores or if that would even help. There’s been suggestions that Go is just not fast enough, but unless we’re going to rewrite syncthing into something else, it’s a moot point. I think the hardware and Internet are the biggest bottlenecks, not the software at this point.
Anyway, this is the largest data we’ve tried to transfer between two servers. Syncthing is cranking away without complaint.
The company donated to syncthing last year as thanks for the awesome software.