I have 3 nodes at three locations which are always on and do nothing else than run syncthing (300 GB of files).
at each location are a few (1…4) fixed devices which run syncthing to sync parts of the files on the server nodes.
additionally there are about half a dozen mobile devices which are moving between these locations (or other locations connected to the web).
what is the optimal connection between these syncthing servers?
-
connect all with all (grid - lots of connection)
-
connect the three nodes to each other and fixed local servers only to the local node (and the moving to all fixed nodes) (more star like, fewer connections)
or does it not matter?
thank you for advice!
Each device you connect to essentially doubles the database size, and potentially increases memory usage and network bandwidth, so it all depends on you and wether you are willing to let these things grow. Having star et al topology means change propagation speed is slower.
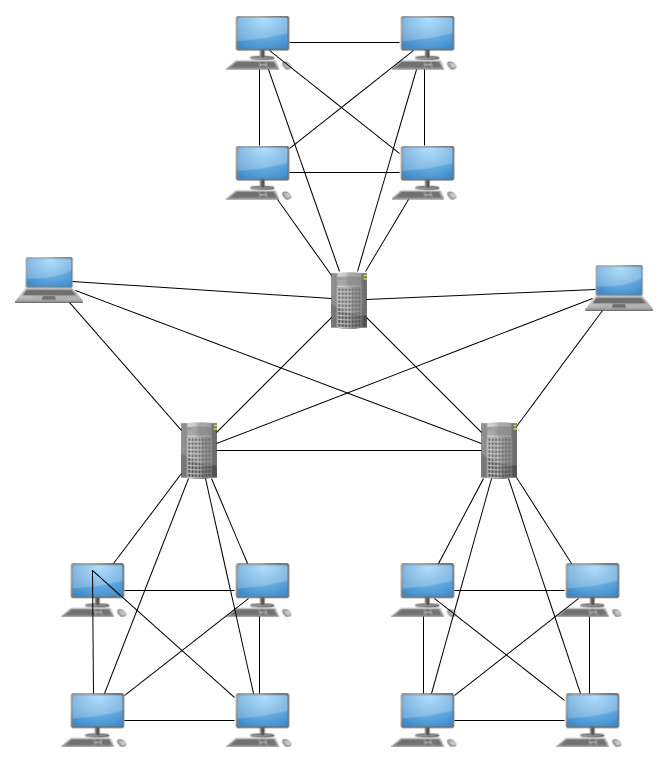
I personally would try something like this:
- Connect each “server” with each other
- In each location connect every fixed device with each other and the “server”
- Connect each mobile device to each “server”
Something like this (only 2 mobile devices for simplicity):
wonderful picture - exactly what my system looks like!
thank you for the technical explanation which is very helpful.
is my understanding correct that when i add a connectino from, say 4 nodes connected to 5 nodes connected, the index doubles in size?
when a node starts, it transfers its index to all connected nodes? this would mean that the total transfer for a node at startup would go up with the fourth power of connected nodes? (size of nodes times number of nodes)?
i only try to make sure i understand your answer before i start changing the current topology (which is between star and grid).
No, if you are connected to 4 nodes, the database and network transfer would be 4 times as much of what it would be if you were connected to one node.
thank you for the clarification.
i have nodes which have only a small number of folders (1…2) and others which sync all (20+); does adding a node with a small number of folders add proportional to the number of folders?
is the index to exchange between nodes always the same size or is it dependent on how much the two nodes share (independent of other nodes?).
to understand the effects of the number of connected nodes (as shown in the figure) on network load, delays in sync and resiliance in case of loss of a node is important. I appreciate your information very much!
The nodes exchange (and hold) only the index for the data they share with each other.
So for the example topology I pictured above (while ignoring the mobile nodes), each of the 3 servers will have:
- the index for the local 300 GB
- 2x the index for the 300GB shared with the other two servers
- the index for the data shared with desktop 1
- the index for the data shared with desktop 2
- the index for the data shared with desktop 3
- the index for the data shared with desktop 4
If you share only 10 GB of data with each desktop, the services will each have to hold the index for 940 GB of data (300 + 2x300 + 4x10).
The size of the index depends on overall size and number of items (“overhead” per item).
In this exsample the desktops will have to exchange and hold much less index data than the server, with much less db size and memory usage.