As for now github issue is closed by Audrius Butkevicius and suggested to post here as a support matter.
It seems, that syncthing is commiting way too much memory on Windows 7. When trying to sync file in range of 50GB hang up the system.
I consider trying to use Syncthing in server-server scenario, but the mentioned whole system hung means, that the software is not reliable for such uses.
You could try enabling debug logging and then upload the files for inspection. I’m not sure which exact logging needs to be enabled to diagnose memory issues though, so perhaps someone else could chime in and provide more information on this.
Also, does this happen all the time, or was it just a single event? Have you tweaked any settings or is this with the defaults? You could also try running Syncthing directly without SyncTrayzor and see if there’s any difference then.
hmm I would need guidance which available debug logging facilities should be enabled - there’s so many.
Memory consumption starts, when I resume sync of one folder - which happens to be a whole drive with backup data (1800000 files, 128 gb of data). The memory is raising steady to about 1.6 gb, then drops to about 900 mb, then eventually in a few hours it consumes 4gb.
No global settings were tweaked. Folder sync is in alphabetical mode, without versions.
It happens every time the sync for this folder is resumed. It is repeatable event. I can see in logs many potentially interesting informations but which are relevant to this problem - don’t know.
Normally, I’ve always been told to enable db and model debugging, so you may as well trying doing the same . I’d suggest to make sure to delete the old logfiles first, then start Syncthing, possibly enabling debug logging through the command line switches, or right after starting the program in the GUI, and then proceed with reproducing the issue until the system hangs. Once this happens, kill Syncthing and upload the logfiles here.
Thanks. Checked db and model, cleared logs, restarted syncthing and resumed synchronization. In a few hours I will be back here and see the results, post the logs.
I have also gathered logs with enabled option model and db, as suggested. I could send them to somebody (7.5 MB 7zipped files). I would rather not post them here as there are not only public data.
I will run sync this night and send heap results tomorrow. Cheers!
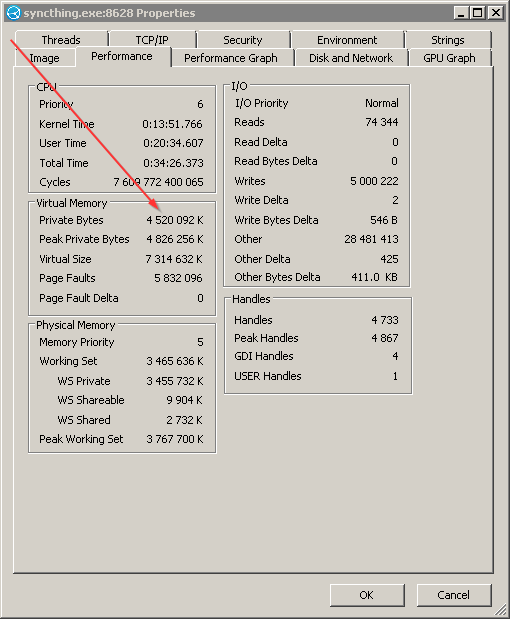
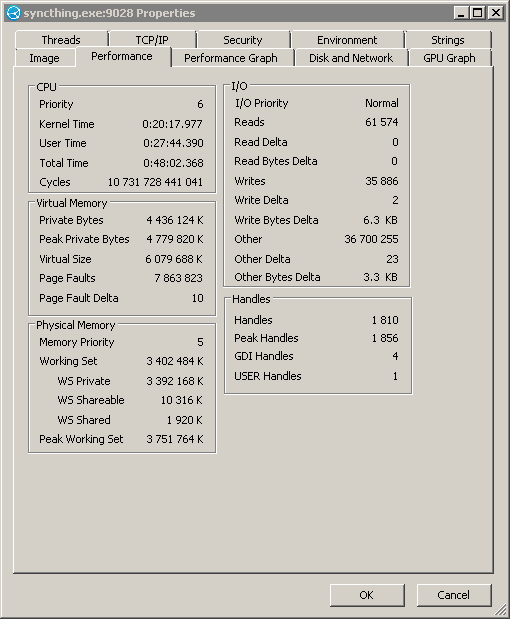
So your arrow keeps pointing at the wrong number, you can have processes that have more virtual memory than the machine has, because virtual memory is … virtual.
Working set is what you care about.
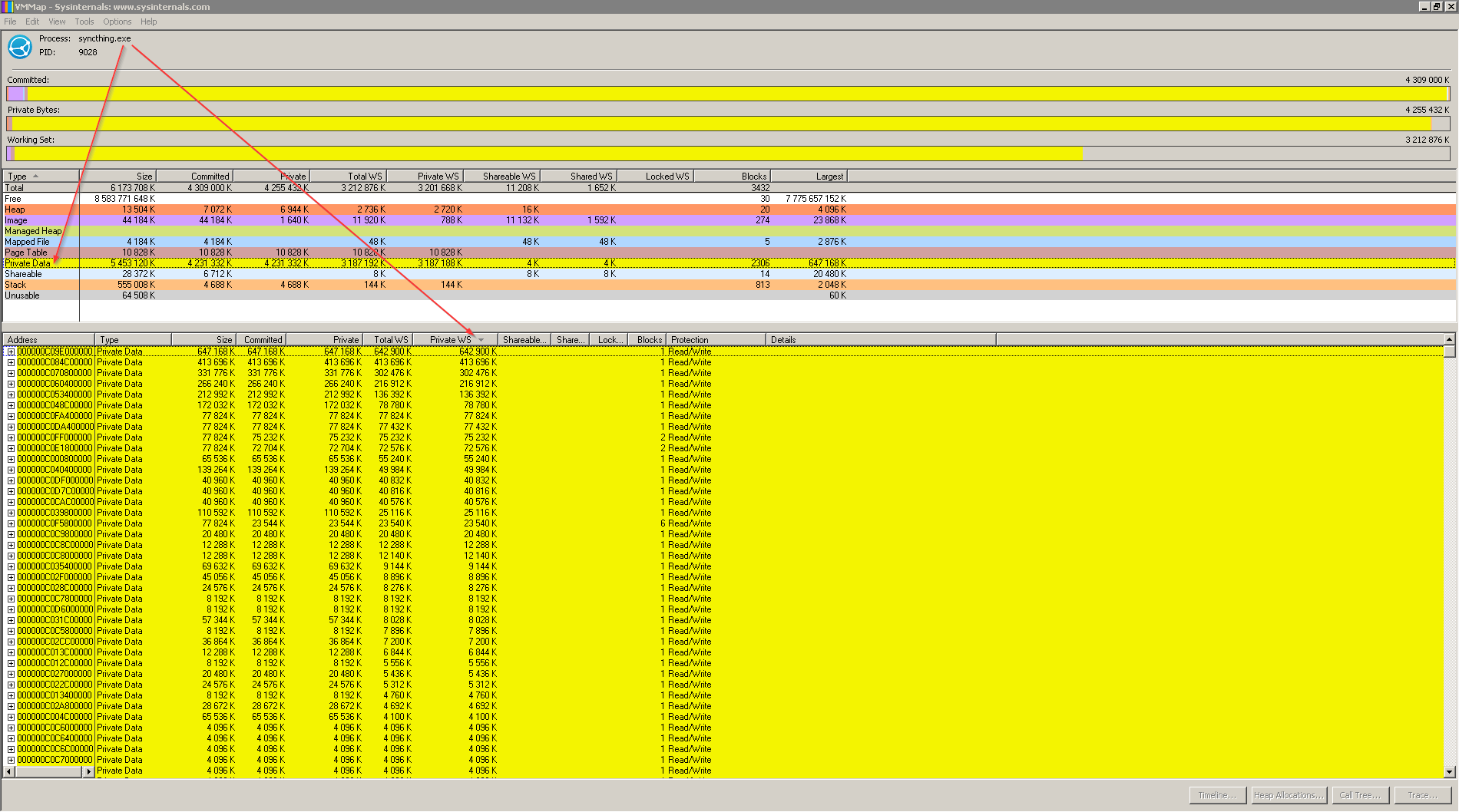
I don’t think the logs will be of much use, the memory profile should have enough details. We need the exact same binaries that you used to produce the profile, but I assume synctrayzor just gets them from github.
Sorry, should also put arrow on the private memory also. On the pictures posted to github there are both arrows. I’m sure you know whats what.
Anyway, both metrics are important, I’m totally NOT convinced that ALLOCATING 4.5 GB memory is a right thing to do. WORKING on 3.7 GB memory (peak) is also SUSPICIOUS - can’t think of a proper algorithm which would need so much working space (in sync application). That’s why I’m posting here.
The system hang up as I can tell from windows event system logs, was caused by too much memory consumed by syncthing.exe, so this seems as a main problem. We’ll see tomorrow, what the heap report will tell.
Well the problem with exceeding and fast consumption of memory in Windows is that it could potentially overflow the pagefile quota which results in system hang (another story). Anyway, thats what happened in my case.
My understanding is that syncthing works as a helper or auxiliary program. It should be a good citizen in systems with installed other servers, so situation when it just tooks all the available memory, without control, is not welcomed. Besides of course, that the intention of file synchronization shouldn’t use so much working memory - that seems as an easy problem to just review the workings of the scan/sync/store algorithms.
Most of the memory is state keeping for progress updates (“Scanning, 12%, done in one month” type of things). More or less this is a list of things yet to scan, and you have a lot of things to scan. Set the advanced folder option Scan Progress Interval (seconds) to -1 to disable and save some RAM.
(Most of the rest is cache for file system case sensitivity lookups, which could perhaps be tuned in the code but is best left alone config wise in your setup.)
I intentionally set “alphabetic order” assuming that this will prevent high water marks and need for scanning the whole system in order to determine which file is the “oldest” in the scenario “oldest first”. It seems, that regardless of this setting, syncthing scans the whole file set and THEN sorts them in alphabetic order. This is unnecessary obviously, because you can determine alphabetic order just by traversing the directory tree, so scanning, checking for changes and sending to other clients could be done in parallel and not sequentially (as in “oldest” scenario).
As for keeping state, I also assumed that syncthing will use some kind of persistent cache like sqlite, or even memory mapped file. This would prevent the need for memory allocations for a whole file set. Using sqlite or mmf allows for block access and of course cleaner architecture (and possibility of external analytic tools for cache/scan progress checking).
Thanks for suggestion with scan interval -1, I’ll check this later, because syncthing is also a processor hog, and I need some of my processing power for other tasks
As it seems I encountered “algorithmic” and “implementation” problems with state management. The other problem I reported was a situation where syncthing couldn’t sync a large file > than 50GB. This probably resulted in memory overflow and pagefile quota alert which hanged OS.
Is there any way for me to help you test or something? I’m developer, but sorry, the Go language and its tooling is not my area.
That setting is about pulling, not scanning. Jakob explained above why state is kept in memory for scanning, and how to disable that.
There’s indeed no such mechanism, which would be nice also for large sync operations. I once did an attempt at that, which didn’t turn out profitable in the maintenance complexity vs benefit. For must use-cases the memory usage is adequate and/or tunable.
OK, I cloned the repository and checked the code. Please bear in mind that I’m not Go programmer and Syncthing is a HUGE project with years of development, so my following observation could be totally not in sync with this project. Anyway, if you use even a bit of this I would be happy.
Scanning
I found several places where directory walking takes places, but this file seems relevant: lib/scanner/walk.go. I wonder why there is a full recursive descend into all subdirs? In MOST filesystems there is information when directory has changed meaning ANY file or subdirectory or any sub-file in any subdirectory. You do not need to walk all the tree in such filesystems IF you have stored information about your last visit to this directory in persistent way.
I found this declaration func CreateFileInfo(fi fs.FileInfo, name string, filesystem fs.Filesystem) and I guess this is the informationa about files which is accumulated in memory during scans (every time the scan is needed), exchanged between channels and kept during hash and probably this struct is hard to gc. If this information is kept in memory then it is impossible to store and check this with former scans, possibly interrupted even (so it needs to be done again), to keep the life cycle of this scan for individual file (started, before hash, hashed, need check, need delete, need sync etc.). I would ask, if this info should be kept in SQlite table and queried/updated every time info about specific file/dir/link is processed. Keeping file data as record in sqlite table solves so many problems with volatile data structs.
The implemented scanning routines IMHO are quite dangerous because the “high water mark” for pumping files is not regulated with “low water mark” for hashing those files. Currently it looks as a sequential solution (I understand the channel for pumping has no means of synchronization with the channel for hashing - hence the memory hogging). I would rather like to have a queue of those files in sqlite table, with statuses as “new”, “need hash”, “during hash”, “hash ok” or similar. Current solution, as observed in this thread is prone to a large memory working set. Using those file data in sqlite table would reduce file context data to the constant value.
IMPORTANT: there is no need for you to implement your own scanning routines, hash routines and universal file system monitoring! This is HARD and using naive tools offered by language platform (scan dir, check file attributes, get next file/dir data) is less than optimal. Every modern file system allows for journaling! You do not need to “scan” the dirs and check everything. Of course there are filesystems (FAT for example) where this is not possible (or could be manually disabled on NTFS) but it is easily recognizable and the default behaviour should be to just use journalin built into filesystem!
integration with this project seems natural. Access to filesystem journaling data in compatible way (linux, windows, mac) could bring Syncthing on another level.
Keeping the history of changes
keeping all the file/directory data in sqlite database would solve problems with memory, would allow to check ONLY changed dirs, would allow to not only “walking” with recursive descend but just iterating over groups of files retrieved by querying specific SQlite table.
the concept of “history of changes” allows to not rely on full scans just on diffs between changes of specific attributes of file/der - for example last modification, size etc. Hashes are useful but not necessary.
using “history” and not scans: as for now, I understand, that if you have more than one synchronized folder, they are processed sequentially. If you have one sqlite table for synchronize files/dirs, then synchronization could be done simultaneously between all the folders and devices.
access to history allows making of analytics, third party tools or external APIs. I could imagine a system where my program just “pumps” file data into your Syncthing with files needed synchronization. Or building of some kind of FTW “foreign table wrapper” where all the files from Syncthing are transferred into a cluster of some kind maybe even SQL.
Necessity of hashes
there are MANY places where SHA256 hashes are calculated in codebase. The question is WHY those hashes are necessary? The more specific question is, are they ALWAYS necessary in the moment when they are calculated? Maybe if we could maintain the history of our files in sqlite table, then we could just mark those records as “hash needed” and let the background process deal with some of those files which REALLY need hashing? We do not need probably to always hash whole file when we walk the directory. Only in situations when we could not determine if this specific file should be synced considering its size for example.
the process of hashing - in my situation, processing of single 50GB file hung the system. I would ask for testing the codebase if there is a code where it is possible, that syncthing tried to load a whole file into memory for some reason!
I saw that hashes are calculated in blocks, but couldn’t determine from the codebase if it allows to exchange between devices only parts of the file. I think that Dropbox in its protocol allows such optimization because many files are changed mostly by appending or only in specific places. If we have 50GB file and only 100KB is appended, obviously we do not need to transmit the whole file.
Determining the “need” to exchange information between devices
there is a lot of advanced code for that in codebase, but keeping this in the context of scanning and hashing I ask the question, why do we need all those hashes? The set of (device_id, path, modtime, size, attrs) is in MOST situations just right to determine if some files should be exchanged. Of course this means that both devices should keep the HISTORY of file data. I could live with the assumption, that clocks on both devices are synchronized (this could be a parameter).
ONLY if both devices could not determine if the file should be exchanged, only then they should agree on calculating hashes. Again, if we would maintain a list of files in SQlite table, then after setting status of this file to “needs rehashing” only then such files should be processed for hashing. That means, that network protocol between devices should be more “talkative”, in the meaning that they could “speculate” or “negotiate” on specific files, and defer actual transfer till they decide if they should copy files, but it isn’t a problem.
Ignoring hash mode
there are functions similar to func (f FileInfo) IsEquivalentOptional(other FileInfo, modTimeWindow time.Duration, ignorePerms bool, ignoreBlocks bool, ignoreFlags uint32) and there is a parameter ignoreBlocks. This parameter is sadly not allowed to ignore by general syncthing configuration. I would GLADLY totally (as for now) ignore comparing/calculating block hashes and only used timestamps and file sizes and eventually file attributes for synchronization between my devices.
It feels to me that you should implement your own application reusing the same protocol and using sqlite and journaling as suggested, which will work for your case.
Sadly our case is slightly harder.
We’ve got to run on all sorts of bastard hardware/os combos which don’t even implement stat syscalls properly, not even talking about mtime propagation up the directory tree after a file is modified, or journaling.
Things are the way they are because they are portable, safe, and known to work, not because we are idiots and don’t know better.
The remedy for the memory usage has been suggested, hence I suggest you try that, instead of, having spent 20mins looking at the code trying to teach us how we should be doing things we’ve been doing for the past 10 years, without context of why things are the way they are.
 . I’d suggest to make sure to delete the old logfiles first, then start Syncthing, possibly enabling debug logging through the command line switches, or right after starting the program in the GUI, and then proceed with reproducing the issue until the system hangs. Once this happens, kill Syncthing and upload the logfiles here.
. I’d suggest to make sure to delete the old logfiles first, then start Syncthing, possibly enabling debug logging through the command line switches, or right after starting the program in the GUI, and then proceed with reproducing the issue until the system hangs. Once this happens, kill Syncthing and upload the logfiles here.