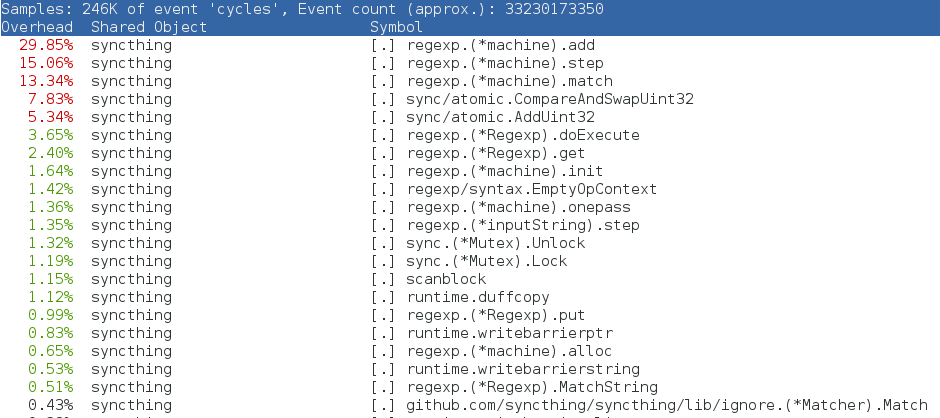
However, I’ve realized that even while ignoring plenty of files, my folders still took ages to scan and sync. I couldn’t figure out why, until perf top shed light onto the issue:
With 15k ignore patterns, Syncthing spends all its time figuring out whether or not to ignore a file… It seems that other users have observed this, too.
Are there any ideas for speeding this up? In the meantime, I guess I’ll hand-optimize my stignore files…
This has been sort of solved ages ago, as we compile the patterns only once, and match files only once every few hours. After matching we keep a cache, so that we wouldn’t need to match again.
we compile the patterns only once, and match files only once.
This is good. The initial matching takes time, though. Apparently, it takes about a second to match a file against 15’000 regular expressions on my machine. Which limits the scan speed to 80’000 files per day…
Which Syncthing version are you using?
v0.11.26, Linux (64 bit)
In the meantime, I’ve removed many of the items in the ignore file, and the initial scan completed within few hours.
As for how to solve this, I’d have a few suggestions:
Leave the code as is, and just emit a warning when the .stignore file contains more than a given number of entries.
Accept stignore files that are distributed over the entire folder tree (like .gitignore files are). This means that entries that belong to certain subdirectories need only be matched against files in these subdirectories.
Don’t change the stignore format, but build a smarter matcher. For example,
recognize expressions starting with a slash (need only be matched against files in the particular subdirectory)
recognize *.suffix, which I think is fairly common and could use a cheaper matching mechanism than regexes.
use some existing library for this. Some suggestions are on StackOverflow.
Edit: one not mentioned on that StackOverflow page, but otherwise seemingly popular, is Regexp::Assemble for Perl. Unfortunately, I don’t know whether there are Go libraries for this.
So the long term goal is to scrap ignores, and use selective sync, where you select a directory in the tree you want to sync, and leave ignores for full file or suffix matching, which should make it easier.