I’m brand new to SyncThing and wondering about its limitations.
Is there an individual file size limitation that SyncThing can handle? Can it handle/transfer files that may be 20GB~100GB in size?
Also, can it handle sparse/dynamic files - eg: virtual machine disk files like ~.vdi, ~.vdmk, ~.vhd, etc.? Files that have a maximum size but actually much smaller on disk. I.E. if a sparse file is spec’d to be dynamically grow to a maximum 2TB in size but only contains 2GB, what will it instantiate on remote devices?
Syncthing just sees files. If the OS reports the file as 8GB that is what syncthing will see and that is how much data will be read from the HDD for hashing and transfer.
ST is not suited to sharing active virtual machine images… Each time it changes ST will re-hash the entire file. This means it has normally changed again before the hashing has completed so the file is not available for upload and the cycle starts again.
There are hard limits on the size of files, this was increased in the last year I think. Try searching the forum, I can’t remember what they were increased to.
The 128 GB limit is no more. Files are by default sparse after syncing, so sparse files remain sparse. But the scanning pass is expansive on large files, so lowering the rescan interval is reasonable if they change often.
With FreeFileSync I have no problem copying these type files even though it gives an initial warning that there isn’t enough room in destination/target to store the file. The copy nevertheless succeeds successfully and usable. However most copy utilities (including Windows copy) fail.
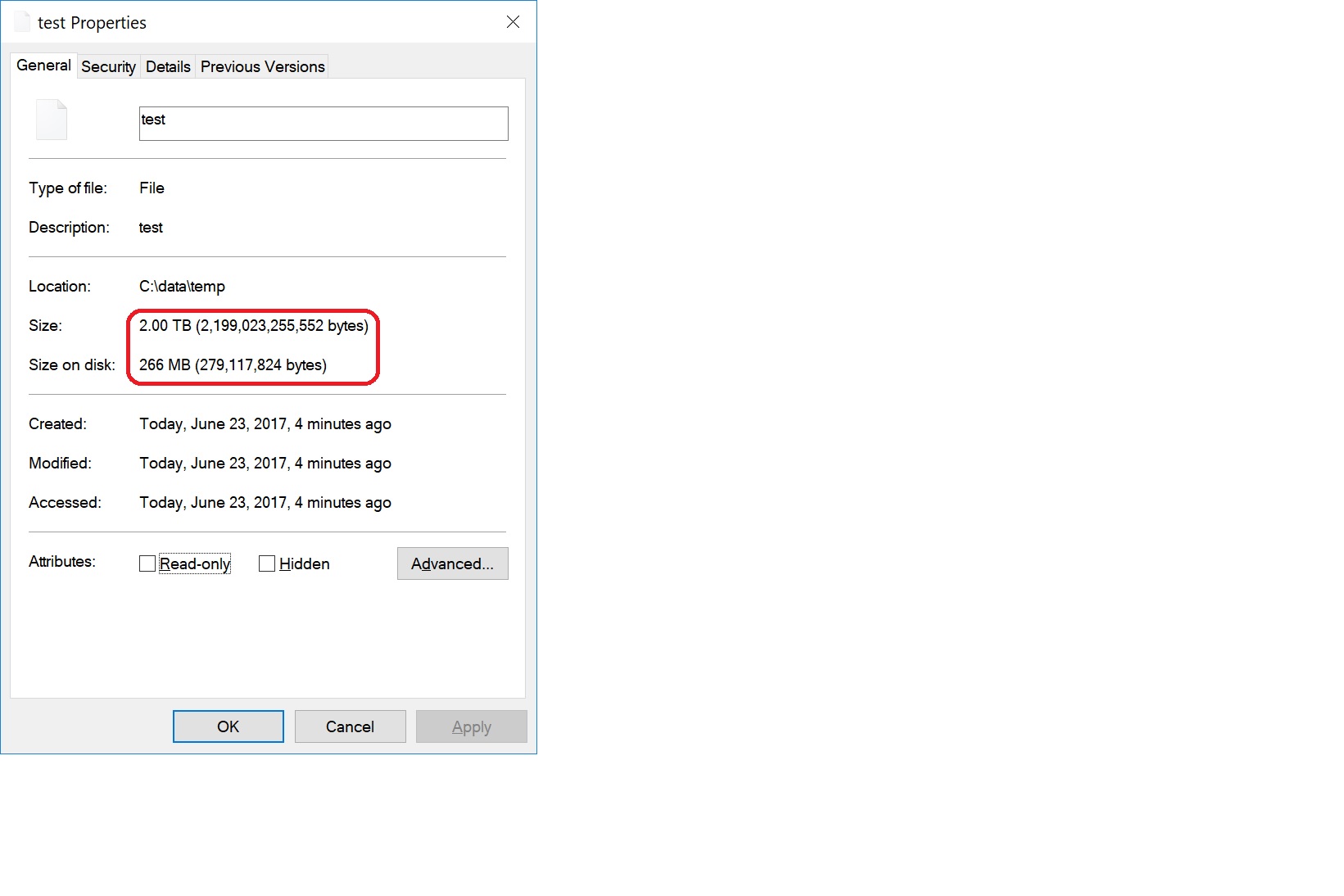
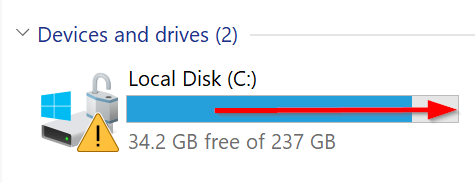
SyncThing fails too, not identically, but similarly. It does not give a warning that the destination/target device cannot store the file but rather on the original/source device I physically run out of disk space. This test virtual drive created by VeraCrypt contains only a few megabytes of data even though it was instantiated w/ a maximum capacity of 2TB. The ‘C’ drive, where my default sync folder resides, eventually gets filled to capacity until I stop and exit SyncThing:
Having the ability to sync with these type of files w/ SyncThing is most important.
Syncthing has an index where it stores infos about all the pieces
https://docs.syncthing.net/users/config.html
Indexing 2TB might result in a large index which fills your C: drive
You are running into the max protocol message size limit. A single protocol “message” cannot exceed 500 MB in size. But the block list for a 2 TiB file becomes roughly 800 megs (2 TiB / 128 KiB * 48 bytes ~= 800 MB) which exceeds this max. In practice this means Syncthing currently can’t handle files larger than about 1.25 TiB. Sorry. We would need to implement variable block size for this to work reasonably.
Also in practice I think it would be very unpleasant to sync such a large file anyway as any change to it will cause a full rehash of 2 TiB of data, which probably takes several hours.
You can recompile Syncthing with this constant changed but I strongly recommend not doing that and using a smaller container or some sort of sharding instead (I don’t know what veracrypt supports).
SO I agree Jakob - perhaps something for you/team to consider sometime in the future. I simply wanted to know some of SyncThing’s limitations as well as whether it could (or not) handle sparse files. Interestingly, VirtualBox and Vercrypt instantitate sparse/dynamic files differently and I don’t know/understand what that difference is. In Virtualbox a dynamic VD’s ‘size’ and ‘size on disk’ are identical as it grows w/ data. Veracrypt’s is different as the screenshot shows.
I want to continue using SyncThing because I think it addresses all my needs. My workaround Veracrypt’s issue w/ dynamic disk is to instantiate fixed size disk which should solve the matter. Uok’s suggestion would also work except this file contains personal data - not something I want left open all the time.
Not the initial exchange though. So you’d need to segment it at that point anyway, and then you don’t need the micro deltas any more (for this specific reason anyway). But I think the better solution is to not track tens of millions of tiny blocks for a single file to begin with.
That’s perfectly fine. I have folders that are over a terabyte and sync perfectly fine using less than a hundred megs of ram - the issue is with files that exceed 1.25 TB or so.
Hm, that makes me wonder. I’ve initiated yesterday a sync with many (3 Mio.) files at a total size of about 2 TB. Syncthing has bugged me almost since the start of the sync. It uses up a huge amount of memory and causes even swap space to be filled (Linux Manjaro up-to-date). If I see it correctly, I have the current version (0.14.31) of Syncthing on both systems which should be synced.
The sync is still going on and has rendered LibreOffice useless, in fact, it is stalled. Other apps still work ok.
Are there any settings whoich could help speed things up and reduce the memory footprint?
Yes, set progressUpdateIntervalS to -1 to disable progress updates. These are normally not an issue, but when there is a huge queue of things to scan (such as initial scan of millions of files) they become costly.
I did that, and it had catastrophic results. Performance went down drastically. Did I do something wrong? I returned it to 5, as seems to be the default, and it’s more or less ok now.
BTW, it’s about 5.5 mio files in roughly 2 TB. Syncthing works a few days now, and it is very hard to figure out its progress, because I can’t often reach the web GUI on the remote client’s end and at the local end it seems to start all over when the IP-address is changed as is usually the case every 24 hours. The hard to connect is due to the constant uploads on the remote machine which I usually use. It’s only some 50 to 80 kB/s, and doing the math this would mean it takes some years to finish the job. Are there ways to speed it up without completely losing Internet access for other apps?
However, the number of synced files seems to increase steadily, but slowly (but this doesn’t tell me how much data actually has been transferred).
Also, I notice if I look only at one GUI, both local machine and remote machine show the same amount of download or upload, but shouldn’t that be vice-versa on the other machine? So lets say: 100 MB upload on the local machine should be 100 MB download on the remote machine. But it says on both 100 MB uploaded.