Just my two cents, but I doubt that this so much of a concern that we should add more clutter to our UI.
3 Likes
What about a DB for each remote device rather than by folder? St then considers that device and it’s folders as a single entity. The device’s ID isn’t likely to change, so maybe take the first group of characters from the ID as the DBs name.
Sometimes when I think St is playing up or needs a clean out, I will often delete the v1 index folder or detach a folder from a remote device to let the indexing clear out the DB, either way is time consuming. If the v2 DB was against each remote device, this would allow me to delete that DB and it can reindex just it’s folders. Thus saving time.
1 Like
Folder state is global across all devices (i.e., list of blocks is shared).
Another thing that came up to my mind, if someone nukes main.db but leaves the folder dbs around, you might have a bad time with indices all mixed up.
We probably want to have a random ascii slug attached to each folder, and then name the dbs after the slug, in case someone nukes not the whole thing.
2 Likes
Isn’t the same true for the old database though? I mean, if someone goes into index-v0.14.0.db and starts deleting single LDB files willy-nilly, this is also going to wreck havoc, isn’t it?
+1 for a little bit of tamper proofing
I’m not saying it doesn’t work, but the time @calmh is putting into this is mostly to get rid of the flaky corner cases we’re seeing with the old database. So there’s hope that no one will need to regularly nuke their DB after v2 goes live.
2 Likes
I ran a couple of performance tests to get a feel for the actual difference against the v1 database. One of them is similar to the worst case setup tried here, I have four devices with four folders, identical contents and scanned but never talked to each other (this is with fakefs). Start them all and observe what happens until they are all in sync with each other.
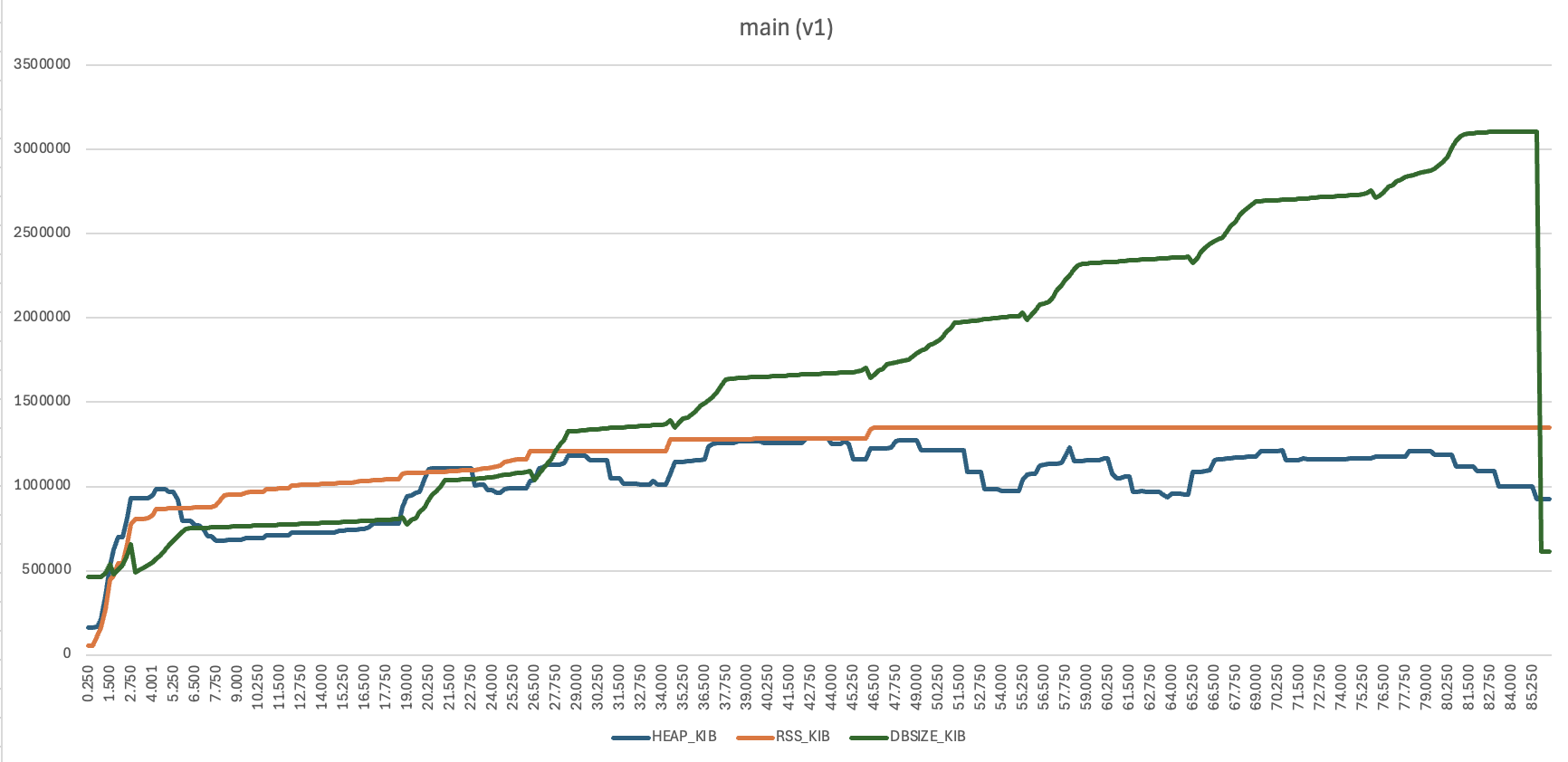
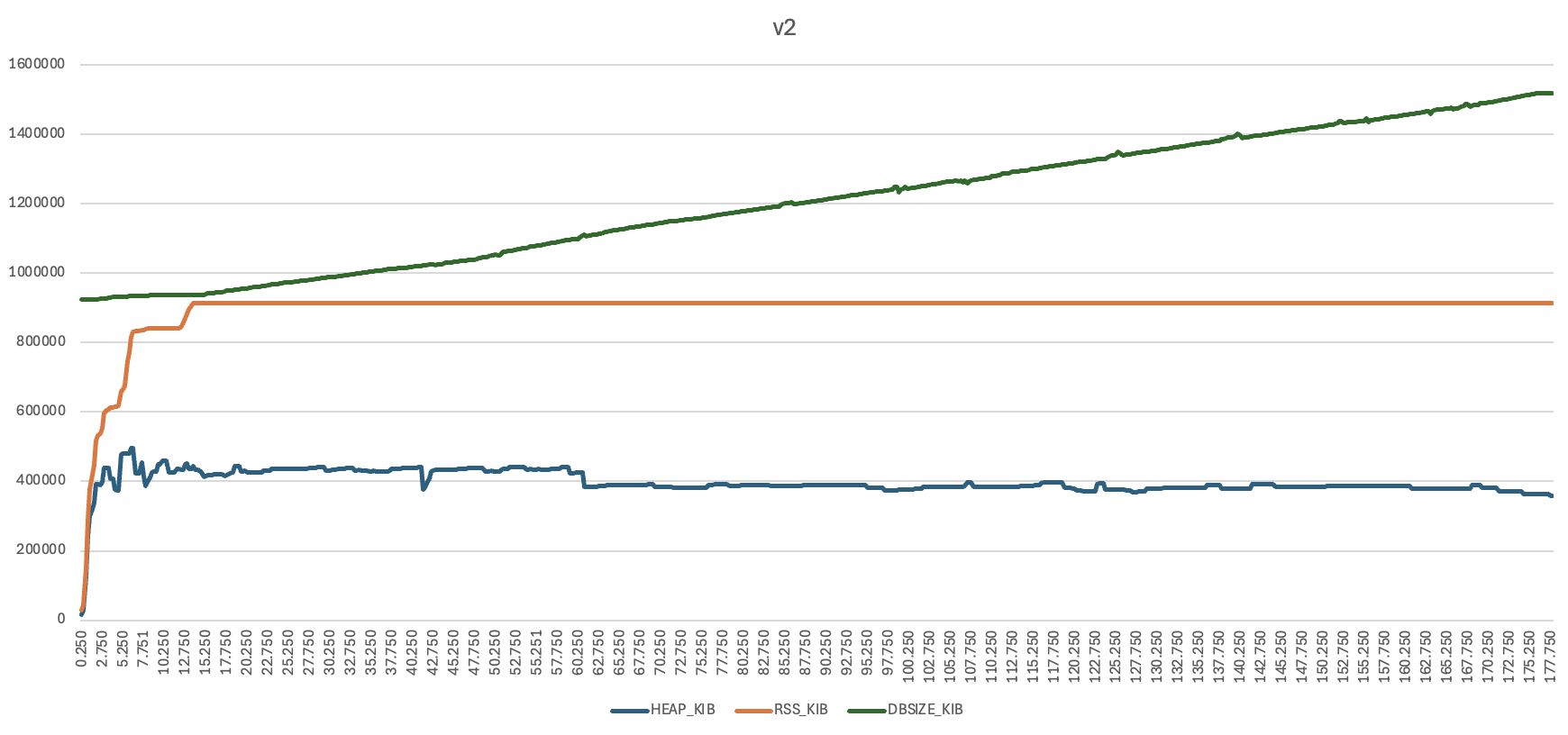
Blue line is Go heap size, orange line is peak RSS (there is no instant RSS I could access in the performance counters), green is database size on disk.
Memory usage here is a bit inflated in both cases as the filesystems are fakefs – all file metadata in memory. However, some takeaways:
- v2 (sqlite) takes about twice as long to get initially in sync as v1. This is mostly because the calculateGlobal function for each file takes longer, something that could potentially be optimised.
- the v2 database is a bit over twice as large in steady state (1520 MiB vs 615 MiB)
- however, peak database size is twice as large in v1 compared to v2, is 3106 MiB vs 1520 MiB
- peak RSS is 35% higher in v1 vs v2, 1350 MiB vs 994 MiB
So, apart from the actual desired improvements with SQLite (clarity and correctness) it’s also better on peak disk space and peak memory usage in this test.
2 Likes
Here’s my latest shot at greatness. ![]() There’s no between-betas migration for this one, if you’re coming from a previous beta this is a full reset and rescan.
There’s no between-betas migration for this one, if you’re coming from a previous beta this is a full reset and rescan. ![]()
2 Likes
Could we use triggers for calculating global stuff on insert instead?
The logic is a bit too involved to do in pure SQL, we need to parse the version for vector ordering and apply conflict resolution and stuff. So it kinda by necessity becomes a select-all-items-with-that-name, do some amount of processing, update-items-with-appropriate-flags
what am I looking for?
Got a link to the location in the code?
I’m on mobile but search for recalcGlobal
Zombies ![]() I noticed that when 5WDSW renames the file, the operation succeeds on both sides but the new name is not even mentioned in its log (look for “renamed-by” and “zombie”).
I probably should stop testing multiple instances on one host, as it seems similar problems do not occur otherwise.
I noticed that when 5WDSW renames the file, the operation succeeds on both sides but the new name is not even mentioned in its log (look for “renamed-by” and “zombie”).
I probably should stop testing multiple instances on one host, as it seems similar problems do not occur otherwise.
new shorter logs: 3-5WDSW.log (17.4 KB) 3-WTXPS.log (17.9 KB)
Been watching the beta 6 thrash the drives all night, even the C drive / SSD has been at 100% most of the time. It got me thinking about performance again. Given the increased number of database files and the overall improvement of IO, it seems to now be creating bottlenecks. I realise concurrency is an option, but I really don’t want to enable it as I prefer everything to sync when it needs to sync, not when it’s the folders turn.
So thinking out loud, is it possible for St (maybe as a user option) to scan folders in the way concurrency does now on loading St, but not be in the ‘waiting to scan’ phase after scanning / indexing.
Essentially, folders are scanned incrementally rather than in bulk ‘on load’, but the folder is then either up to date or carries on syncing when the scan / indexing on that folder is complete. When all the folders are scanned, it becomes a normal St
How about if I fix #5353 instead?
1 Like
That would help, but I was think more along the first time indexing. I’ve come to the PC this morning and it’s still working hard doing the first pass through
recalcGlobalForFolder:
Maybe I’m missing my first coffee, but the very first query could be written without the EXISTS clause as you’re allowing self joins.
recalcGlobalForFile:
A lot of flag wrestling. Partial indexes or dedicated columns might help?
You’re going to have to be more specific. ![]()
Wrapped my head around the query and it’s fine as is ![]()
SELECT f.name FROM files f
WHERE NOT EXISTS (
SELECT 1 FROM files g
WHERE g.name = f.name AND g.local_flags & ? != 0
)
GROUP BY name
My point about flag magic still stands, though. All these local_flags & ? predicates are not able to use an index.