We use Syncthing some while now to synchronize a file-based encrypted overlay FS (“Cryptomator”).
It used to work very well and some of as also know Syncthing quite well and use it for several years now (e.g. myself…).
Before explaining the issue, let me first describe our setup briefly:
There are 9 people who are using this virtual FS stored in a shared folder.
In order to achieve proper synchronization between our stations, we have set up an always-on Debian server as “central sync node”. Because our admins had security concerns, we use the Untrusted Devices feature of Syncthing for yet another layer of encryption.
The issue:
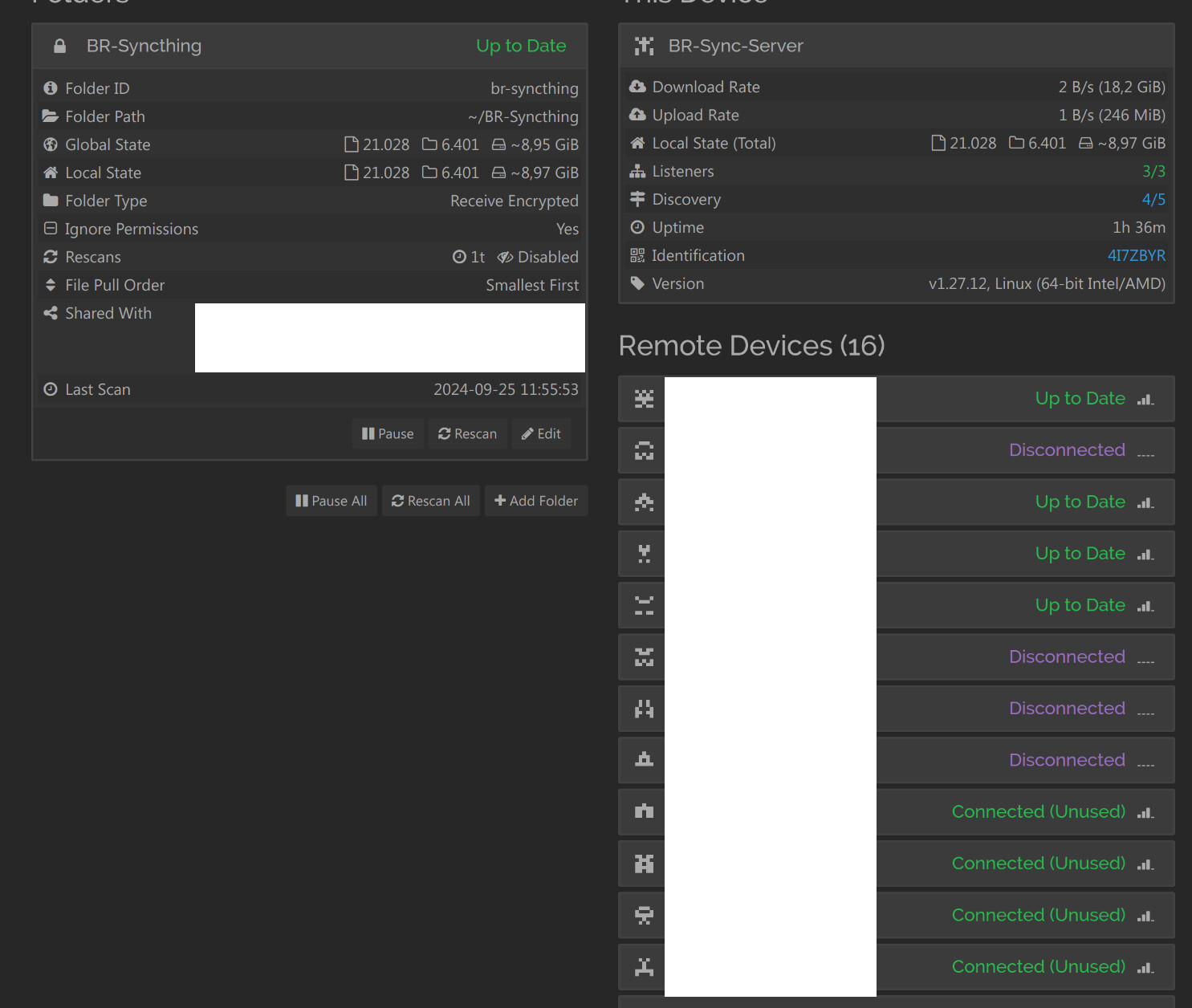
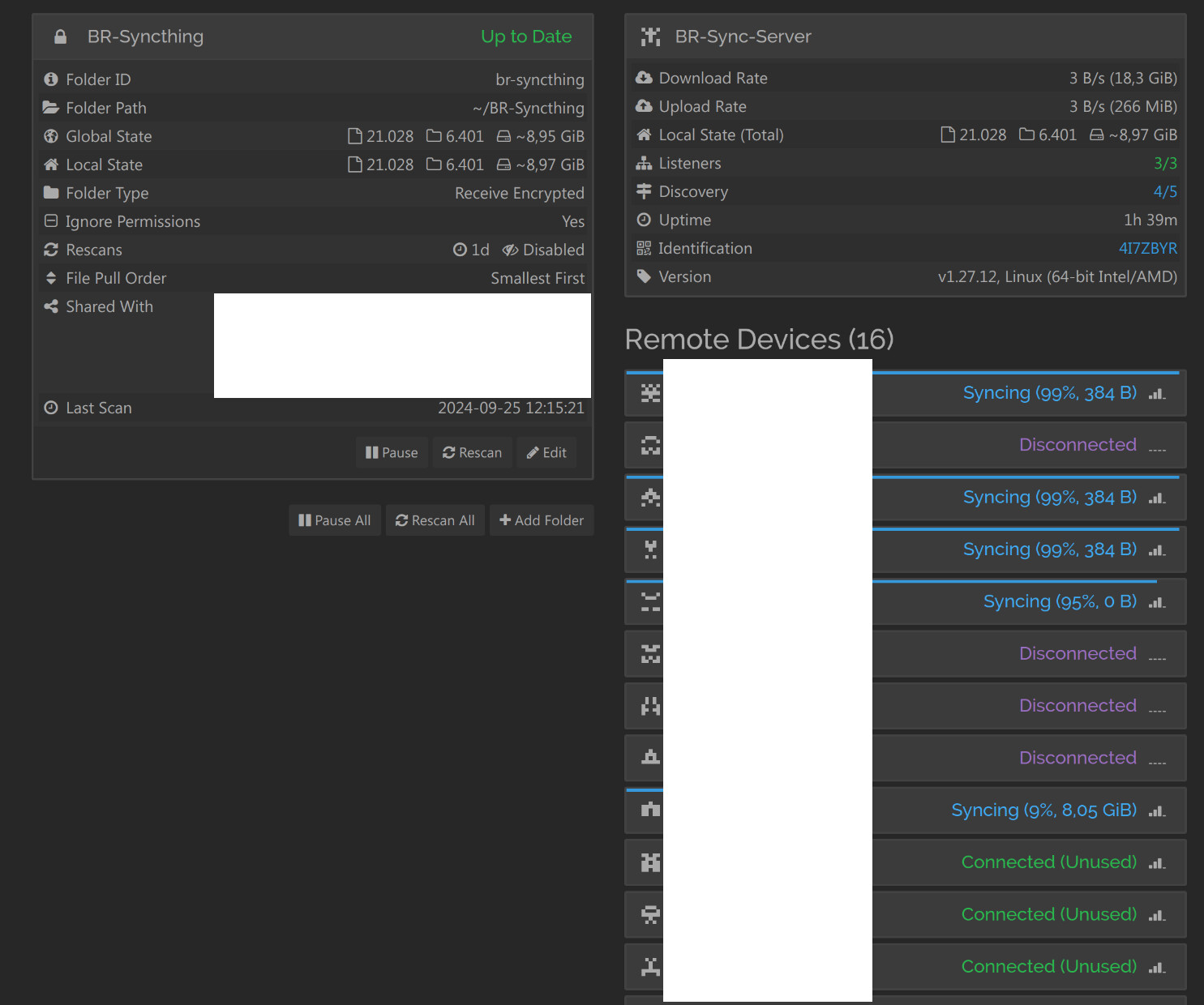
Since about 2 weeks, some of us seemed to get out of sync with our central node. However, the sync status between any two of us, who are directly connected, still showed 100 % synchronicity.
Also, the interface on the central node shows the very same thing: A number of items (the same for all active nodes) are “out of sync”, but neither on the central node with its encrypted contents, nor on any of our machines we see anything which points to the reason for this.
What I’ve tried to fix this:
Run touch on affected directories mentioned by Syncthing, hoping they would get bumped to the central node then - no effect.
Issued numerous full rescans on my node and the central one - no effect.
Deleted my local index (stopped SC before and restarted afterwards) - no effect.
Deleted the index of the central node. This indeed had some effect, as all files seem to got re-synchronized. However, it did not resolve the issue. Some items seemed to disappear, but for at least one node, the “situation” got even worse!
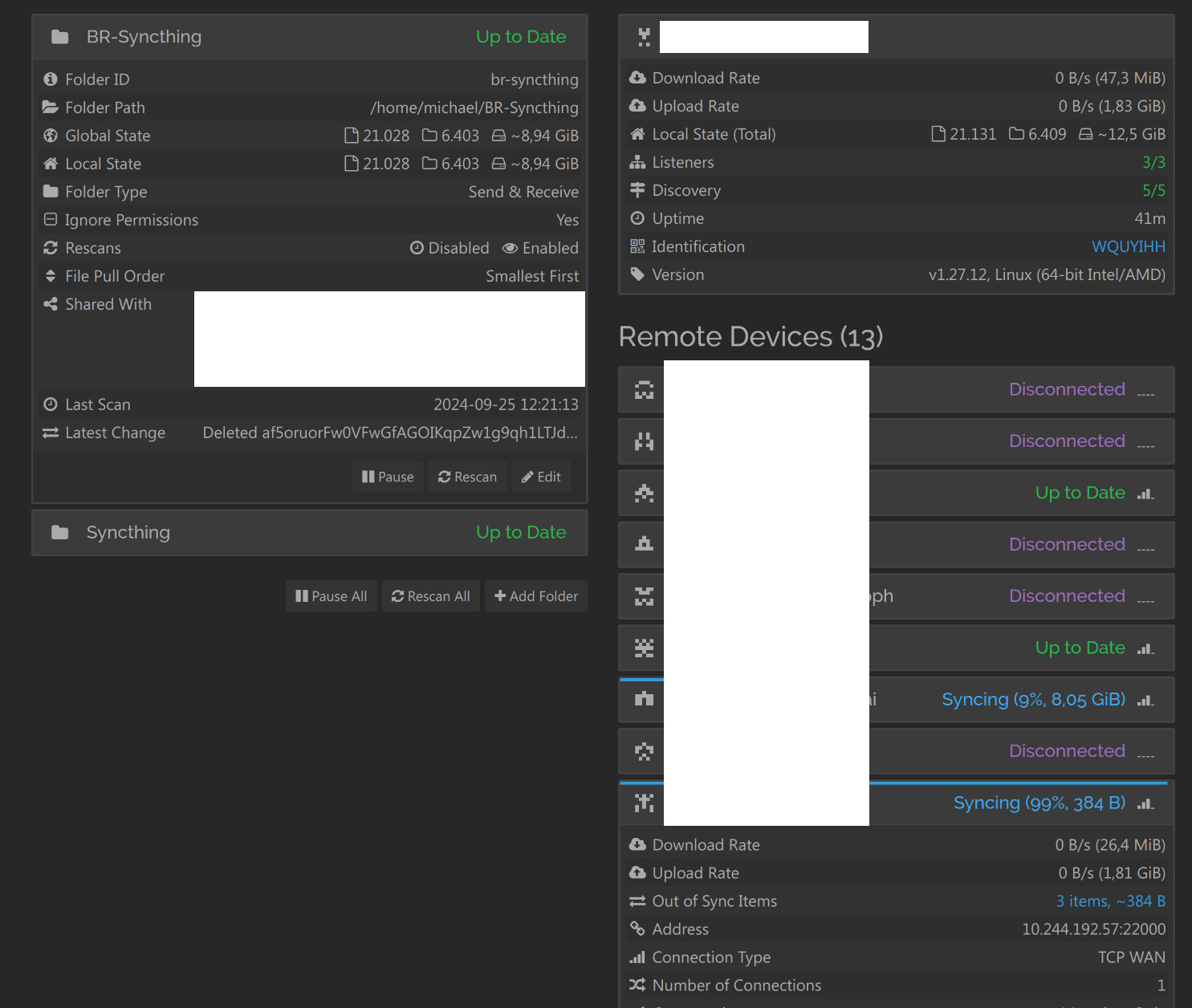
Finally, completely deleted the whole share on the central node and recreated and synchronized a fresh copy from my machine. This almost solved the issue, but there are STILL 3 directories that are not synchronized. My local SC tells me each directory is 128 B (???) while SC on the central node talks about 3 items, 0 B each.
I also tried to run SC with STTRACE=model syncthing on both my local machine and central, hoping that might bring up any reason for this unsynchronized elements, but no, nothing useful there as well.
Can anyone here make sense out of this or could give me a hint how to debug this strange behavior?
Can you share screenshots of the Syncthing Web GUI from the affected devices with the errors present? You can obfuscate file paths and such, but please leave all other information visible.
Syncthing counts each directory as taking 128 B, so this is normal, and zero-byte items usually mean deleted files.
Thanks for your reply.
Meanwhile, I have found out that this issue happens when I enable synchronization between one specific node running Windows 10 and the central node.
Enabling synchronization between me and that machine is not a problem, but as soon as I try to sync our central node to that machine, everything goes nuts.
This is how it looks on the central node when the “bad machine” is not selected for sync:
Maybe good to know:
After that machine has “poisoned” the state of the central node, I must delete the entire share and resync it from the other nodes. I have not yet found any other way to revert to proper behavior.
I don’t see how this would benefit anybody. Doesn’t that create the exact same situation?
I told that colleague he should try this, but he’s on vacation first. He told me to exclude him from the share for now, which is what I did anyway, so the situation is currently under control.
Still, I would really like to understand how and why such a thing can happen. I would expect that at least one machine would try to sync that items or at least tell me what is wrong and provide a red overwrite button.
But nothing? Simply stopping synchronization without any notice and being stuck forever? That’s the second worst thing a sync software could do, right after rolling a dice and shredding some data.
Besides: Does anybody have a clue how and why this affects especially Untrusted Devices?
This issue seems quite obviously related to encrypted storage, because, as I said, when I share directly with said problematic node, it is still stuck, but doesn’t screw my share. However, if I allow it to sync to the untrusted central node - boom.
For one thing, it might have helped as an interim troubleshooting step. For another thing, I don’t understand your use case well enough to know if this would be viable as a workaround while figuring out the issue. That’s why I asked.
Thank you, didn’t want to be ungrateful for your help.
Workarounds are not a problem, we could even use alternative data channels while debugging that issue and shut down the things.
However, what we really need is to understand the root cause of that issue so we can implement a final fix for it and get back to a reliable setup that doesn’t do strange things.
Question: I forgot to mention that, but it came to my mind that I saw extremely old timestamps on some, maybe even all files that didn’t get synchronized, mostly from 2009. (We weren’t even aware of SC back then, so definitely an error.)
Could some “time travel” issue on the untrusted device (central node) or on the problematic Windows node cause such issues?