Sounds like an issue, please feel free to file it on GitHub. My expectation would be that after at most one scan interval the deleted files should be announced to the other side and deleted on A as well.
Yes, please open an issue. The problem is that when detecting deletions respectively checking db entries, we do not handle the case where the file is already deleted both on disk and in db, but the local flag changed.
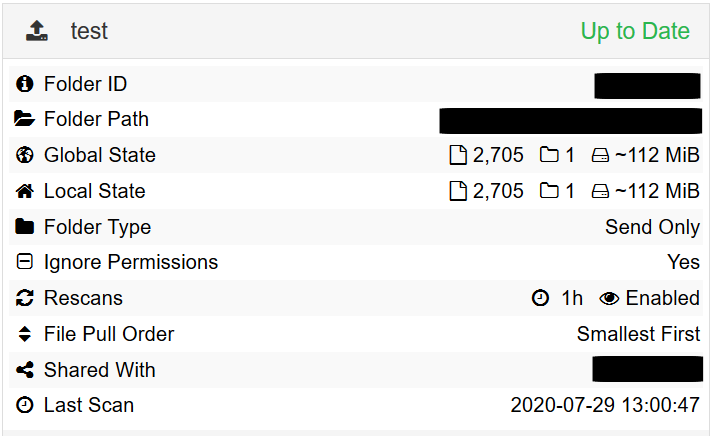
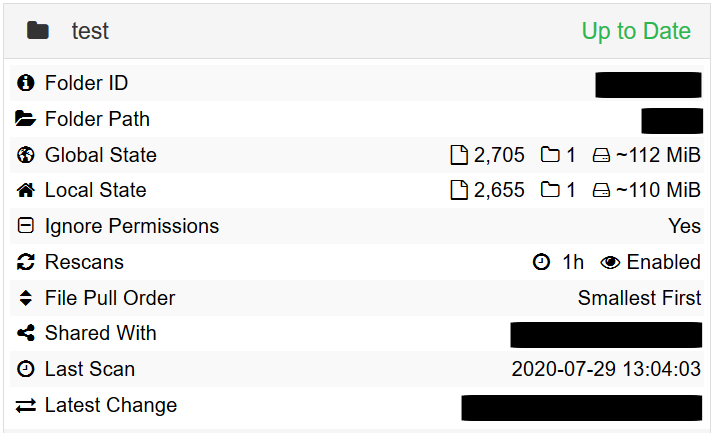
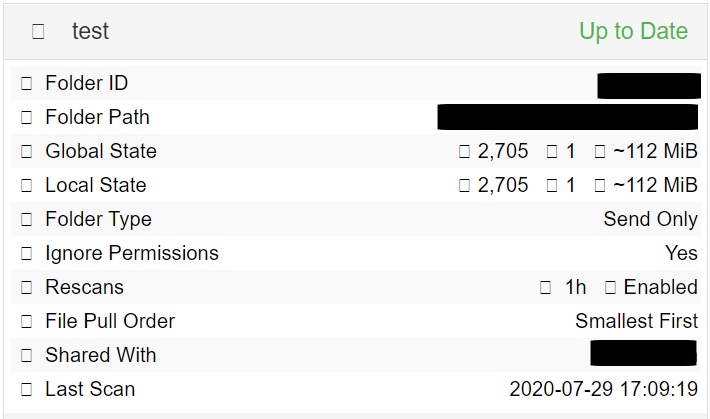
Syncthing now knows about the deleted files, but the synchronisation is stuck. Also, changing the folder type on Device A from “Send Only” to “Send & Receive” has no effect either.
The situation on Device B does not change regardless of scanning or restarting Syncthing, i.e. the global and local states differ, but the folder is still marked “Up to Date”.
Thanks for the followup, that’s still consistent with the bug I found.
However another thing needs clarification:
FlagLocalReceiveOnly is part of LocalConflictFiles, i.e. the behaviour is that unless only the device changing from RO to SR ever modified a file, this situation will be considered a conflict. I believe the rationale is that given we don’t announce the RO-changed file to the world and this interrupts syncing, we might be out-of-sync for a long time and don’t want to override the global state with that. However that shouldn’t be a problem: On detection of the change on RO, we bump the old version. Now if anyone else does the change, we indeed don’t sync that, but that also means that when switching to SR, we are already in conflict. For file no-one else touched, I don’t see the harm in just announcing the updated version without causing “synthetic” conflicts.
Right, so since the delete happened on the SO side, it will be in conflict with the rest of the world, and the delete will lose the conflict resolution. So the files get resurrected on change to SR?
Yes. However it doesn’t apply to deletions only. If SO (or SR, doesn’t matter) creates a file F, which gets synced to RO, then RO changes it and later switches to SR, right now we drop other version counters, meaning the old and new version will conflict. I’d say it would be ok for the new version on RO which is now SR to win without a conflict.
Right… I remembered it as dropping the entire version vector, thus losing the counters, but that only happens on index sending. So I guess we could mostly just clear the receive-only bit and let the rest play out as it would normally.
For deletions it’s dropping the entire version vector, for scanned changes (respectively no change but going from RO flag to no flag) it’s dropping everyone else’s counters.
I have tested the scenario using a compiled build of the main branch, and I can confirm that the problem is no more. Thank you very much for the quick fix!