I’ve had this a while so may be a bug / just the way it is.
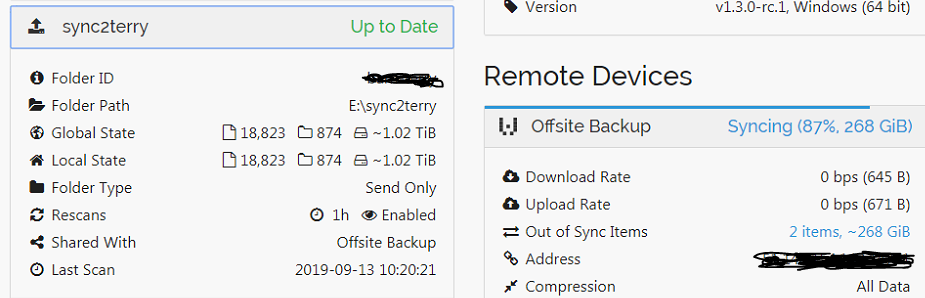
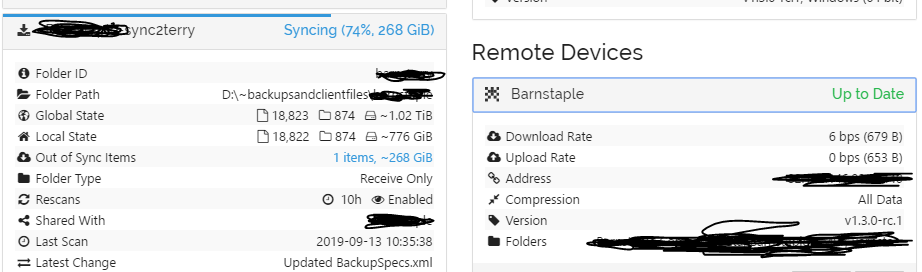
So i’m pulling down a 268Gb file off a server as part of a 1Tb backup. All the rest were fine, averaging 18Mbps from the moment I started the fresh sync and had been going like the clappers all week. However this morning the sending PC had been restarted and it’s doing nothing. I have done a rescan on both ends. Sending saying it’s up to date, receiving says 74% of 268GiB but the transfer is now between 0 ~ 6bps
I can see from the resource monitor that the file is no longer being scanned and it’s not restarted syncing, however it is complaining that there is not enough disk space, insufficient space in basic D:\~backupsandclientfiles\########## which would be true if I were syncing the file from fresh, but it’s already on the drive and has allocated the space so it’s not realising it’s already got the file partially downloaded.
Seems i’m going to have to delete the tmp file and start it again.
That may be, but it sounds like a bug. Report it on github? Some similar thing was fixed recently but I don’t think it was this. You can probably also disable the check by setting the threshold to zero, rather than dropping the file.
@calmh, I think you told me once that before a transfer some index data is exchanged so it might look like Syncthing is not doing anything.
I only notice this on large files, eg. 25GB, that after scan there is a long pause where only a couple of KB/MB is exchanged in the first 5 or more minutes (note: I have a medium range device with spinning hdd, so this might also amplify this). Once this is done uploaded speed is maxed out as expected.
I think time for index transfer is really only a factor when there’s lots of index data to send, like initial sync with many thousands of files.
In this case it’s more likely that it’s the phase for creating the temp file and copying local blocks that takes time before it gets into requesting blocks from the network. Probably, if you look closely, it’s quite busy doing disk I/O during the time when it’s not visibly “doing” anything. Even if you don’t have any of the required data already there is an index lookup for each block hash to look for it, so there may be a lot of database I/O for a spinning disk.
All of this is probably a little better nowadays with larger (hence fewer) blocks.
So in essence my (slow) device A is waiting for the other device B to do its homework. Although the file is new and I’m sure device B does not have it (or any parts), device B will look up 25000 x 1 MB blocks (just an example), until it is clear that they all need to be fetched. I will check next time on device B for more logging.
Setting the free space check to 0 has solved my issue as the remote device was shutdown overnight and once back up and running this morning, the sync kicked in quite quickly and resumed.