Hi everyone, I was wondering if somebody can give me some advice if I should switch over from using git to Syncthing.
A little bit of background: I wrote a dental EHR system that uses the filesystem as the database. I did this for a multitude of reasons including:
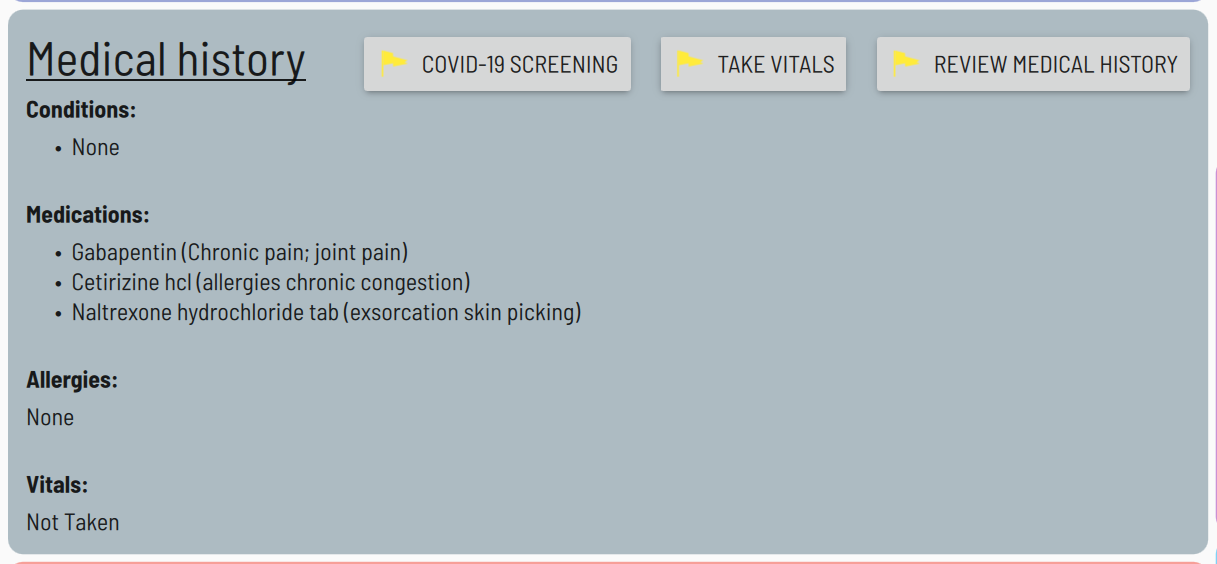
All regular text data is stored in either .ini files or .json files. Not only is it easy for software to read these formats, but it’s also very easy for me to teach a doctor how to read and even edit these kind of files. I recently showed a doctor who knows nothing about computers a patient’s “allergies.json” file and he was able to read it with zero training. My personal philosophy is that doctors should be able to read the patient’s raw data without having to learn the difference between a SQL left join vs. right join.
It uses a simple naming convention in order for any software to be able to look any data up. Need to read the patient’s medications? Just read “patData//medical/medications.json”. You can add other files without having to worry about destroying the 1st order-ness of the tables.
When you have a folder for each patient, you can drag and drop anything and now it’s “assigned” to the patient without having to rethink the whole database. Got a .pdf from a referring doctor? Just drag / drop that .pdf to the patient’s folder and now it’s part of the patient’s chart. Got a .stl file from a scan? Just drag it over to the patient’s folder.
Keeping a local copy is also fundamental to this idea. Is AWS down? You can still see patients. Is the router down? You can still see patients. The idea of a doctor having to decide between sending all their patients away versus treating them without their chart is a terrible decision to make.
You can pretty easily distribute the “computation” to other servers. I can have one server that just holds the master/origin data, one server that does nothing but do patient insurance lookups, one server that just deals with messaging, etc.
After working with this system for nearly 5 years, I think I made the right call. It would be hard to persuade me to go to something relational or even a some of the no-SQL databases out there.
However, what is much more up in the air is how to manage syncing with other computers. My original solution was to go with git. Essentially, each computer (which has full disk encryption) has a full clone of the patient repo. There is a local “server” that acts like the main origin. Each PC would do a git pull every minute (via a chron job). Each major change via the GUI would be made as a commit and pushed to the repo. All conflicts would be managed by using “theirs” always. In my own practice, I have one local (as in, on site) git server, and then one cloud server that acts more like a backup. Please note that the actual dental software itself is written using C++, Javascript and QML (via a toolkit called Qt). As of right now, it only supports Linux desktops but I want to add in support to Android, macOS, iOS and maybe Windows.
What I liked about git:
Pretty easy to set up and get started via the command line
The git server would deliver only the commits since the last pull. If there are none, git can very quickly tell the other PCs “you are up to date”; so pinging the server every minute isn’t that costly. Doing something like incremental backups is rather trivial.
Very easy to check out the log. You can see who made what changes and when. Then is pretty useful to see who added in a specific patient’s appointment at which time.
Nothing is ever “lost”. You can do something crazy like see what previous insurance the patient had 3 years ago.
By default, the merge is pretty good. For something like an .ini file, you can have two people make two different changes to different parts of the same file and git will handle that just fine.
git can do a pretty good job with symbolic links which I tend to use for some loading optimizations.
Once you set up the encryption keys and ssh, it can work rather transparently. Although you can use ssl/tls certificates, you don’t have to. Therefore, you can still do encryption when connecting to an IP address rather than a domain.
What I don’t like about git:
By default, git really wants you to manage the conflict. You have to do some level of trickery (via configurations) to force it to resolve all conflicts transparently.
Lot of the cool features of git is easy to use via the command line; something that most doctors will not be able to do easily.
People in “Dental IT” don’t know anything about git, ssh, or even about RSA / ed25519 keys. Many of them can’t even use the command line.
Right now, my software directly uses the git binary executable to do everything. The “right way” to do things is via libgit2 which is actually far more complicated than most people expect. There are a lot of things the git executable does behind the scenes.
Android is a mess. There is no openssl by default so you have to compile / include it yourself. There are existing binaries out there but now you need to compile openssl, openssh and libgit2 via the Android NDK which often gives strange linking errors that most people don’t know how to fix. Android really doesn’t like it if you try to launch binary executables within your Android app. The only other alternative for Android would be to use jgit which I wouldn’t like to do because then I have to write a fair amount of code to connect the C++ with the Java (which Qt does have tools for).
Because it it’s nature, you will always have at least two “copies” of the patient data, one that you are working with (via checkout) and indirectly the one stored in the .git folder. As of right now, my patient database is only 12.9 GiB by itself and then 26.2 GiB including the .git folder. Not the end of the world but once I add in things like CBCT, it can easily become 80+ GiB.
My software, which is in a “1.0” state, right now uses git. I am making a ton of underlying changes to the GUI for my 2.0 release and felt this is a good time to revisit why I am using git and wanted to make sure I made the right call. So I am right now looking in to alternatives like Syncthing.
What I like about Syncthing:
Open Source (which is a requirement for me)
Pretty easy to setup on Linux and Windows
Conflicts are handled transparently
Creating a “tray icon” for the current status is not too difficult
Is able to handle encryption via ssh if needed
Adding another device is easier for non-tech savvy people compared to ssh/git.
What I don’t like about Syncthing:
There is no real REST api for grabbing the data, just checking up and configuring the server. In theory, one could be added, but transferring files over JSON isn’t that efficient.
It is written in go which I assume is difficult integrate with C++. Please correct me if I am wrong about this.
There are Android and iOS apps out there, but it appears they were able to get it done by integrating the go code with their native Java or Objective-C code (at least that what it seems to be, I could be wrong about this)
So I only have some cursory knowledge of Syncthing so I don’t know if testing out Syncthing is even a good idea or not. Any feedback on this would be great or if you have better ideas. Resilio would be awesome but it is not open source. Using rsync would lose a lot of the advantages git gives me. I don’t know if IPFS has security in mind in terms of limiting data to only those who are approved to see it. But I am open to other alternatives. Thanks for reading this wall of text ;-).
Data transfer is encrypted, no need to fuss with ssh.
Why do you want a REST api for grabbing the data? Or want to integrate Syncthing code with C++? It sounds like your application manages files in the local filesystem. Let Syncthing keep the files synced.
Its in the filesystem. If its not in the local filesystem, (a) it hasn’t been transferred or (b) it doesn’t exist on the remote system.
Syncthing works well with many-to-many. I imagine that making git work without a central server is more difficult.
You mention the size of the filesystem data. Syncthing would expect that every instance has a complete local copy of the data set. For me, this is ideal. If you’re worried about limited local storage Syncthing would not be the right solution.
The one part I would want to consider is watching Syncthing conflict files and figure out what to do (or at least raise a flag, like SyncTrayzor does in Windows).
That’s the parts I can understand and speak to, others may have better insights into your questions.
Edit to Add: Before you go further, install Syncthing on a couple of local machines. This is not hard at all. Play with Syncthing and see how it handles transferring and syncing a copy of your data (not your working set!) so that you can “test to destruction” and verify the resiliency and failure modes. Once you’ve worked with it – and this can be mostly done in an hour or two – you will have a better idea of whether this works for your application.
Thanks for the reply. Just to clarify, the C++ portion of my code will edit the actual file and then call git to make the commit, and then push the changes. Right now it is doing this via literally calling the git executable. The “right way” would be to use libgit2 but that’s a whole other story….
For Syncthing, I would assume it would be running in the background anyway. So when the C++ edits a file, Syncthing would automagically figure out what got edited and will “commit” the changes to the other nodes. Otherwise, my C++ code would have to call something for Syncthing to make a deliberate change.
Only reason why I would like an REST API for grabbing files is just so I don’t have to integrate go code (along with libssh) for Android; that is it. Otherwise, I have to integrate my C++ code with go code.
After a (configurable) delay (assuming the filesystem allows/works with watchers, most all platforms do), Syncthing sends the changed file (blocks) to all the remote devices. No need to push/pull etc.
This works pretty well transparently on all platforms that Syncthing is available on.
Your application can drop an entire layer of file management – simply make the required changes on the local filesystem, Syncthing handles the synchronizing.
For large files with changed blocks in the middle, Syncthing only copies the changed blocks. (The block size is managed by Syncthing, no need to manipulate or worry about it.)
I think the biggest thing you will lose is the revision history. You can setup staggered file versioning but it’s not the same thing and going back to an earlier point in time is not possible in the same way it is via git.
Syncthing also won’t merge two changes in a single file like git can.
I think if you don’t need that syncthing could be a good option.
Hmm… You can do both Syncthing and git. I actually recommend using both! On a server, use git to check if there are any changes every now and then. If there are changes, commit. This retains your ability to do proper rollback in case of “badness” happening.
Have to be careful not to sync the repository DB. There are a couple of other gotchas too. If you need to maintain git for the precision revision history, then I would suggest leaving it as is as it’s been working for years. There should be no need to use two tools to cover this when you can use one or the other.
if you want to simplify and don’t need the precise history, and within file merging then you can ditch git altogether and simplify.
Not really. if files are changed on two devices, Syncthing will pick one and rename the other and all devices will get both files. I don’t consider this automatic. In my mind, for text files as you say, git is better in that it will merge changes from different parts of a text file automatically. In my mind, git is more automatic than syncthing in this regard.
Are you occasionally calling git gc or git gc –aggressive? I’ve found git is pretty efficient at storing data in its repository assuming the data is compressible. If you’re tracking images and PDF’s then yeah, git keeps an extra copy.
I don’t think there’s a “right way” and a “wrong way”. It works. it’s not a hack. There’s nothing wrong with using the executable. Your post is interesting to me though in the sense that you’ve written some software to integrate git, but you also seem to have some expectation that doctors or administrators will have some practical knowledge about how it works. This seems odd to me. I wouldn’t expect any doctor to understand what a git commit is. I use git at work for tracking, and the code manages git completely behind the scenes. The user doesn’t know how it works. doesn’t need to know commands. Doesn’t even need to install it. That’s on me as the developer.
I think the fundamental thing you need to answer for yourself is what major challenge are you solving by switching. If you want to be able to VIEW records on a mobile device, then I could potentially see the benefit combining git with syncthing and using syncthing on a master server as a send only device to sync the current state with the mobile devices. but if you’re talking about a true cross platform solution where devices of any number of types can make changes and those changes have to be fed back to all other devices, then you really need to consider how this is going to work and things like conflict resolution. Can you host some kind of secure web server for the mobile devices to interact with?
Anyway, lots of ways to do this kind of thing. No “right” answer. Tradeoffs all around.
Yeah, so the text, due it it’s nature, takes up a small percentage of the space. The images (radiographs which are stored as .png files) takes up the vast majority of the space. Doing the gc even with –aggressive didn’t make much of a difference.
Yeah, almost no doctors who what git is, but even fewer know what SQL is. My overall design philosophy is that doctors should at least have a right to know how to access their data rather than have it hidden via a proprietary database. If doctors don’t care they hopefully don’t have to learn git, json or even .ini files. But if they choose to learn how the data is kept, it is easier to learn git than to learn SQL. So I mean, data-wise, a patient can have this as their medications.json file:
If they want to see the .json file, they can; if they don’t, they don’t have to.
Yeah, I might have to deal with conflict resolution a little better I guess. Right now it defaults to always using “theirs” but I might be wrong in just blindly doing that each time. Something for me to think about.
I thought about trying to make everything web based; but sadly it’s not exactly trivial to have a browser to allow 20+ GiB of space to be stored on the device. One other feature I really want is to be able to access the data on a tablet / phone even when you have no WiFi and no cellular service.
Thank you. You have given me a lot to think about.
So basically you are using git as a distributed database. You need to be aware that in general it is impossible to do merges / conflicts automatically and always have the system do the right thing in such circumstances. That is why git defaults to the user if it can’t merge automatically. (And even git’s automatic merge routines can do the wrong thing in certain cases, but one is not so likely to run into them in practice.)
So unless your application follows some strict set of assumptions any automatic merge strategy runs the risk of corrupting your database. Having users edit the database by hand means you probably do not.
That said, I think I would use git over syncthing for this. Git at least merges stuff. Syncthing doesn’t, it just leaves both versions of a file in there and leaves the rest up to the user. And with git you are always working with consistent snapshots of the full database (commits). Syncthing doesn’t have such a concept, it only handles individual files. So you may run into trouble attempting to roll back to a consistent version of your database if you have conflicts. Also note that SC doesn’t have a commit log or anything like it.
Regarding Android, I don’t think the situation with syncthing is substantially better than what you describe with git. Both android apps are just wrappers around the standard syncthing binary compiled for Android. If Android decides to kill the app at just the wrong time there is a risk of the syncthing database being corrupted. I thing someone is trying to reimplement the core syncthing protocol in java to make it run on android natively, but that’s still work in progress, AFAIK. I don’t know the details of the iOS app.
About the repository size, have you considered git-LFS? That’s meant for your problem of large binaries. With LFS, you would only need to store everything on a server, while lighter clients will have the full history of the text files locally but only the current checkout of the binary files. That should limit your data usage doubling.
Another direction for light mobile (or web) apps might be not to store the repository on them, but serve the files with some kind of network file transfer protocol from a bigger server. E.g. ftp, or just regular http. That way they don’t have a local copy but they also don’t eat GBs of storage.
And w.r.t. C++ / go integration: calling C functions from Go is supported. If your C++ code runs as a library you can export C compatible functions and call them from Go.