We have a shared folder for rehearsals recordings with several friends.
Some days ago one of them began to have issues because of its (windows laptop) disk was nearly full. Fortunately I remembered I installed for him the Duplicate File Finder true freeware and told him to roll up his sleeves to clean his disk from multiple duplicates of unsorted manual backups of smartphones pictures and spouse & children files. Some hours later I realized he would sweat like a pig with this tool that can only manually delete dups inside one single group, so I proposed him to setup 3 temporary shared folders will break in the end from his computer to mine (Documents, Pictures and Music only to a mirror in mine, Sync/Friend/Docs, Pics & Mus, and move anything but links from his Desktop directory to a new dedicated empty dir in his Documents), where I have a more powerful tool (fslint or equivalent)… and no time/courage to learn and tame the power of find command line.
Lets run ST several days for ~150Gb through his ~1Mb/s UL DSL… …
In the hurry to reclaim some free storage on his disk I couldn’t wait for the full sync to finish so I had the idea to begin with smallest files as they are the culprits and fortunately ST shared folders advanced settings allows (thanks devs ) to sync the “Smallest first”, so I can begin to run my fslint against my side, slowly cleaning my friend’s one and recovering free room.
Yet another cool experience with Syncthing.
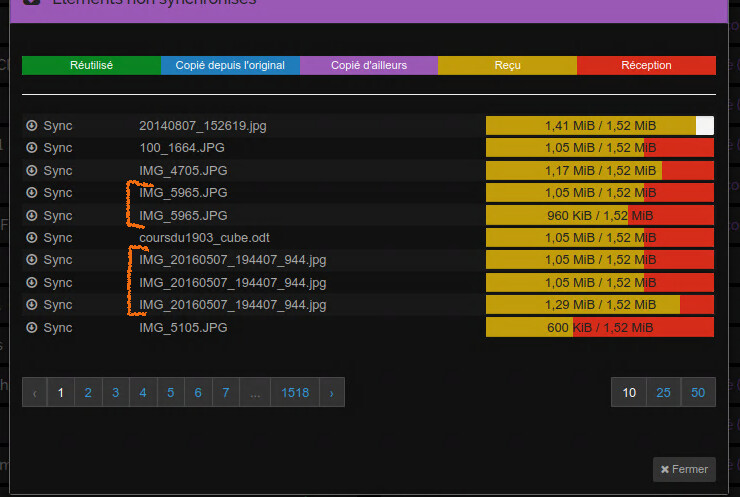
Just a caveat, I know ST is able to quickly sync files (and/or chunks?) without having them transferred by performing local copies of yet available local chunks, but is seems this does not occur when several candidate files are being transferred at the same time (remember, smallest first, i.e. same size roughly at the same time): in the picture below I know the marked files are true dups, not only size/name. This would have saved a lot of time, mainly when dups are many, sometimes 40, and/or big (in this use case 500kB is big yet). I have no idea if it’s worth the effort to implement such a behaviour or tweak the yet embedded one.
I don’t know exactly whether sharing blocks from partially downloaded files is possible. But probably not I suppose.
In this case, the problem could be avoided by actually going back to random pull order. This way, the chances of a duplicate already having downloaded completely are much higher than if each duplicate is sorted by size to sit closely in the queue.
Not that sure : setting all 3 shared folders back to random download, it seems there is a background job that searches potential same file or block as soon as a [block?] download completes, that nearly immediately makes any duplicate file written to disk even if it was deep in the download queue of this very shared folder or another one.
Thank you Jakob. This answer definitively induced the “Random” File Pull Order is the faster when duplicate files exist, preventing duplicate blocks amongst files to be downloaded several times before one file from a duplicate group is full available… Good to remember. Reading yesterday the BEP documentation led me to guess something like this behaviour at block level, but I couldn’t guess this happens only once a full file is dl’d.
@cosas Another cool feature of Syncthing worth mentioning in this context is the built-in deduplication - it comes with quite a few conditions though.
It basically means, that if you run a filesystem that supports it (none of the mainstream ones like NTFS and Ext4 as far as I know, even though it says “Tested on EXT4”; I suppose that just means “Tested to not cause harm”), not only will Syncthing skip the download, it will also save disk space by having identical files/blocks reference the same space on your disk.
Not default behavior, and certainly does not guarantee that duplicate files won’t be duplicated even if you DO indeed check all the boxes for this to work, as you discovered a corner case yourself.