(I feel I should prefix this by saying I love you all and I’m not trying to be argumentative, I’ve just accidentally nerd-sniped myself because the more I look at this the more interesting the puzzle becomes  )
)
I wonder if we can get some stats on how many clients use relays, rather than speculating based on anecdotes? data.syncthing.net lists how many clients have relaying /enabled/ (94% of them, no surprise since that’s the default), but no stats on how many are /using/ it…
“maxed out” is relative to two points
I’m thinking of the relay service as a whole rather than any individual connection - like my 100mbps server is currently pushing 20mbps of relay traffic, which I think contradicts our assumption of “traffic will grow to swallow all available bandwidth no matter how much is added”. Even if one client is limited to 1mbps due to their home ADSL connection, if there are thousands of clients queueing up to use relays, my server should be pushing 100mbps.
My current feeling is:
- relaying is very rarely used as a percentage of all connections [1]
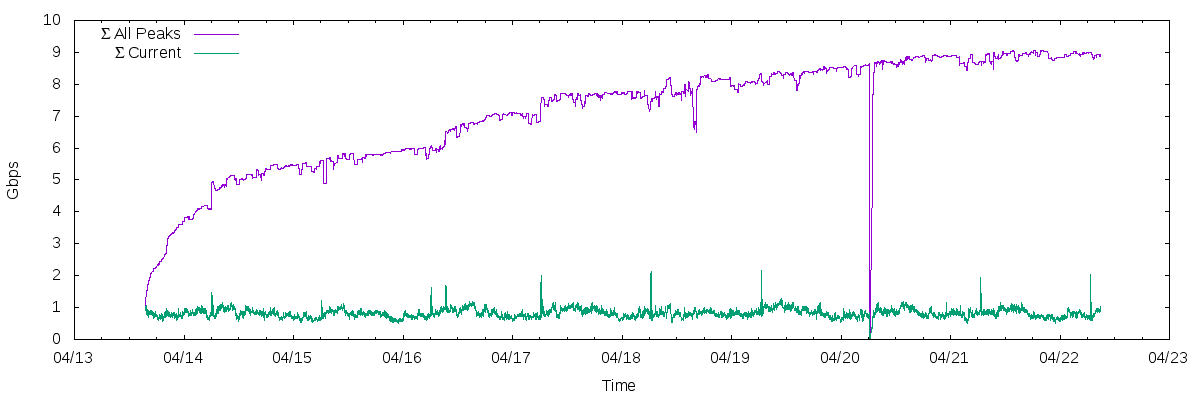
- currently the relays have a combined capacity of 10Gbps [2]
- currently the relays have a combined usage of 900Mbps [3]
[1] because UPnP is the standard for all home internet connections that I’ve personally experienced
[2] assuming that all 112 relays are on 100mbps connections, minus ~10% on the assumption that most people who run relays do so on servers which have minimal but non-zero traffic of their own to deal with
[3] curl https://relays.syncthing.net/endpoint | jq '.relays[].stats.kbps10s1m5m15m30m60m[0]' | grep -v null | awk '{ sum+=$1} END {print sum/1024}'
Although since I listed that first point, I wondered if I could do any better than “based on personal experience, my feeling is a small percentage”, so let’s see what I can figure out on the back of an envelope…
curl https://relays.syncthing.net/endpoint | jq '.relays[].stats.numActiveSessions' | grep -v null | awk '{ sum+=$1} END {print sum}'
23,000 active relay sessions right now; compared to 30,000 active users per day. I assume I must be wrong about something here, because >2/3 of daily users being connected to a relay right now seems off…
netstat -tpn | grep strelay | grep EST | sed 's/.*46.105.126.214:22067 \(.*\) ESTABLISHED.*/\1/' | cut -d ":" -f 1 | sort | uniq | wc -l
^ Lists 2000 unique IPs currently connected to my one relay.
Is it the case that every client keeps an open connection to at least one (or more?) relays, even if it isn’t using it? That would explain why “number of clients” and “number of clients connected to a relay” appear roughly equal…
Looking at my own syncthing instance running on a server with a public IP, which should never need to connect to a relay:
netstat -tpn | grep syncthing
^ Based on that output, it is connected to two clients and one relay, which seems to support “every client connects to one relay even if it doesn’t need to”.
So let’s try looking at “how many connections are actively transferring data” rather than “how many connections exist”:
cat tmux-scrollback.log | grep -v accept | grep -oE 'to .*?:' | sort | uniq -c | wc -l
^ For my one relay, I see 500 unique IPs actively receiving data in the previous 2 minutes (which is as far back as logs go, since I’m running it in tmux with 50k lines of scrollback  ), which seems reasonable for 2000 IPs connected, which makes it seem like maybe a large percentage of clients (>50% ?!) are actively transferring data via the relays?
), which seems reasonable for 2000 IPs connected, which makes it seem like maybe a large percentage of clients (>50% ?!) are actively transferring data via the relays?

 As Audrius says, it’s likely there are lots of bottlenecks involved, so if you have a fast relay it’s likely the limits are on the client or in other places.
As Audrius says, it’s likely there are lots of bottlenecks involved, so if you have a fast relay it’s likely the limits are on the client or in other places.