I’m seeing Syncthing getting killed by the kernel on one of my NAS systems because it’s using too much RAM. This wasn’t a major issue prior to 1.2.0 - I can see 3 such instances in my kernel log for May/June, but 25 in July/August so far. I haven’t knowingly done anything to dramatically increase my usage, and this NAS isn’t massively out of sync with the cluster.
Please let me know if I can provide any further information to help pinpoint if there’s anything generally amiss. If needs be, I’m happy to run through the RAM-trimming suggestions that have been provided previously.
No increase is expected. Your profile shows some things that surprise me, but for literally millions of files I suspect it might not be unexpected, really.
The things that surprise me are the filesystem watcher keeping lots of state apparently:
Thanks for looking in - much appreciated. I’ll try to fill in some context:
Hmmm - definitely wasn’t seeing this level of being stamped on prior to 1.2.0. Is it safe to downgrade back to 1.1.4 for testing? (From an internal consistency perspective that is - I understand QUIC won’t work of course.)
I have 16 Remote Devices defined on this machine - some rarely come online, but some are constantly on.
There’s a lot of data churn in some of the shared folders, and I’ve currently got 365 days of staggered versioning defined on all the shared folders (of which there are 17).
I know - and I know I’m asking a lot for quite a niche case. Unfortunately the NAS units are limited to 6GB RAM maximum (according to the manufacturer; anecdotally they appear to support 16GB - but I’m wary of going beyond manufacturer’s recommendation on this).
You’re very kind; I find this tool so useful, and I’m so grateful for the hours of work you, Audrius, Simon and the rest of the team put in, I just wish I could contribute more to the project!
Yes, you can downgrade to 1.1.4. The database format is unchanged, but the config format changed slightly for QUIC and crash reporting – you can just set the config version back to 28 on the first line of the config and Syncthing 1.1.4 will be happy.
One thing though. Upgrades (and downgrades, so any version change) will mean a full index transfer instead of the usual delta-since-last-connect thing. This by itself will cause a lot more database churn and memory usage directly after upgrade, and after downgrade. This could be part of what you’re seeing, perhaps.
Ok - I’ve got 1.1.4 installed on this unit, and will see what happens.
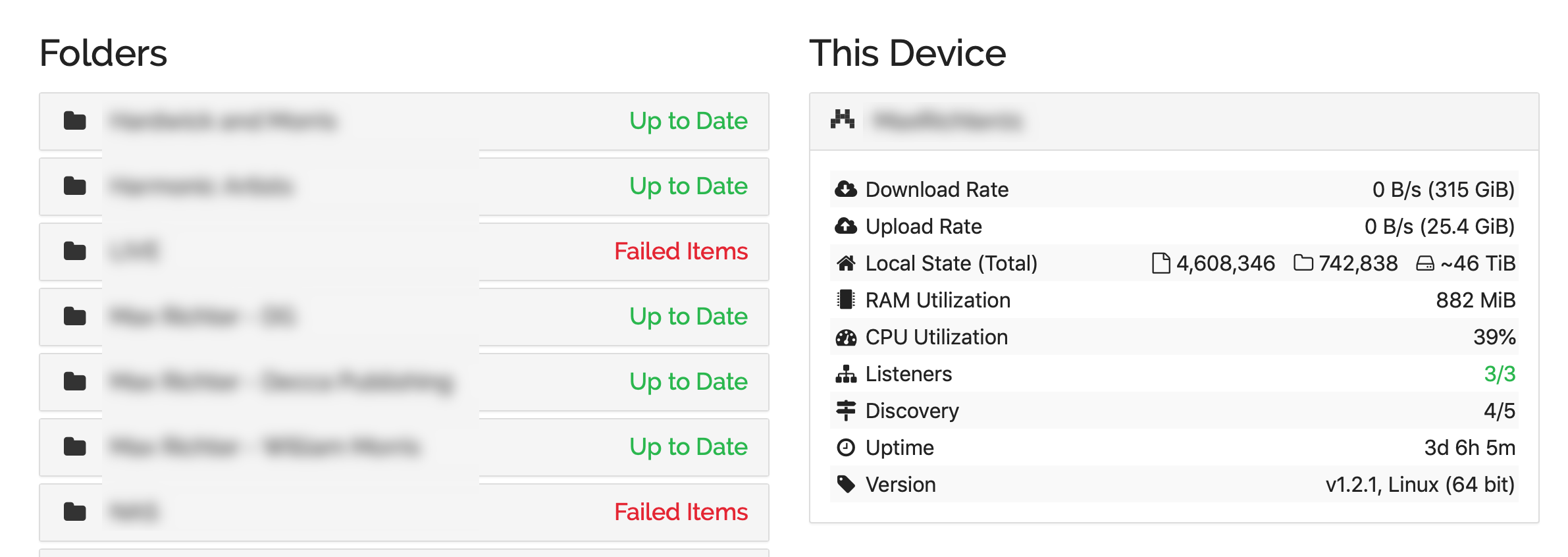
In the meantime - and incase it’s of use to see a comparison, just looking at another NAS (same model) that I look after, I’m seeing much lower memory usage (even with v1.2.1):
Sorry - this might be useless information here. Some context:
Although this Syncthing instance initially appeared to be running smoothly, I found one of it’s partners had stalled (as per Web based Syncthing not showing info - #33 by AudriusButkevicius ). Unfortunately I wasn’t able to grab a heap profile - but I was able to see the UI was reporting 6GB of RAM usage;
I restarted this instance - it came back up as normal;
However, at this point the NAS profiled just above here seemed to stall.
Unfortunately I haven’t got any logging running on these units so I can’t provide anything concrete at present.
I suspect you’re seeing the effect of the initial index transfer. I also know for a fact that the database parameters (very low level tuning stuff) are crap for large setups. There is a better set of parameters to plug in, but it’s not configurable in 1.1.4/1.2.1. There’ll be debug options to set it in 1.2.2 and something more sensible in the future.
This is however a solution to blocking & bad performance, rather than too high memory usage.
It does indeed for linux and any other systems with a underlying watcher that does not support recursive watches. This is due to supporting multiple watches in the same tree and having to know about existing watches on watch setup (and also event dispatch).
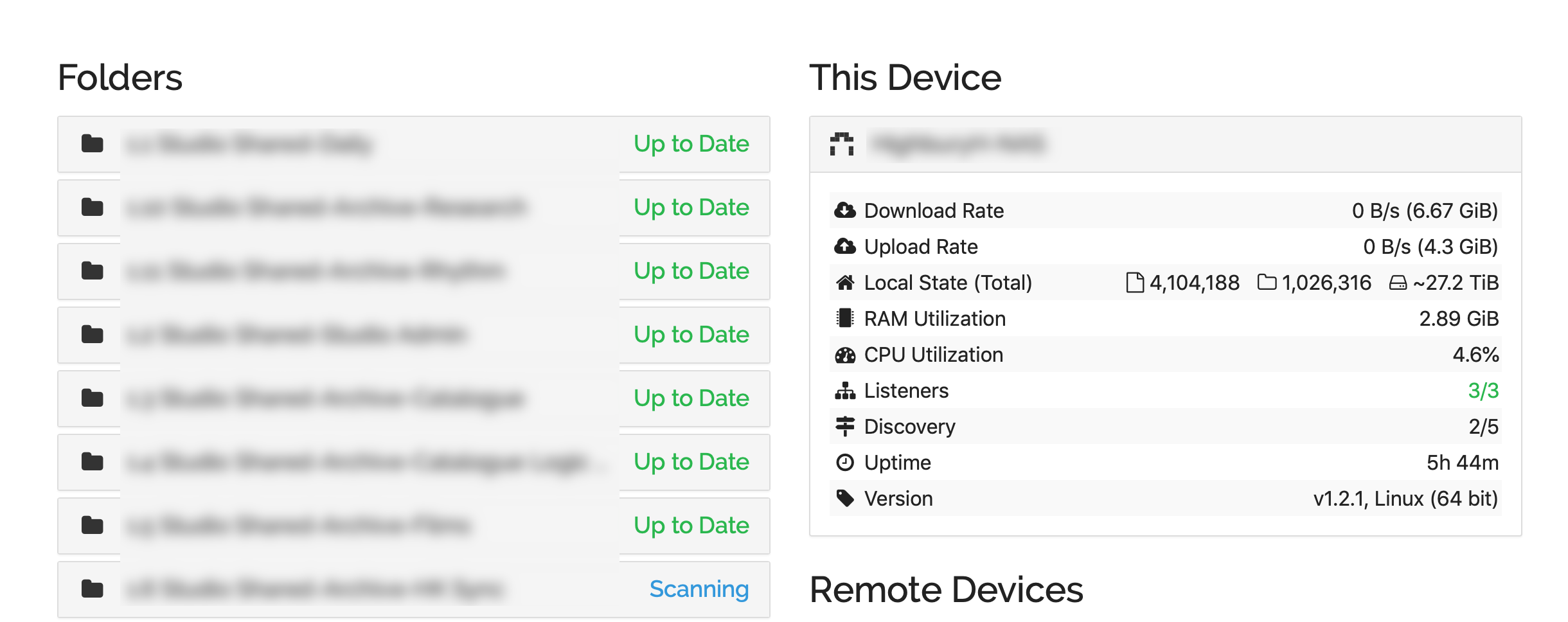
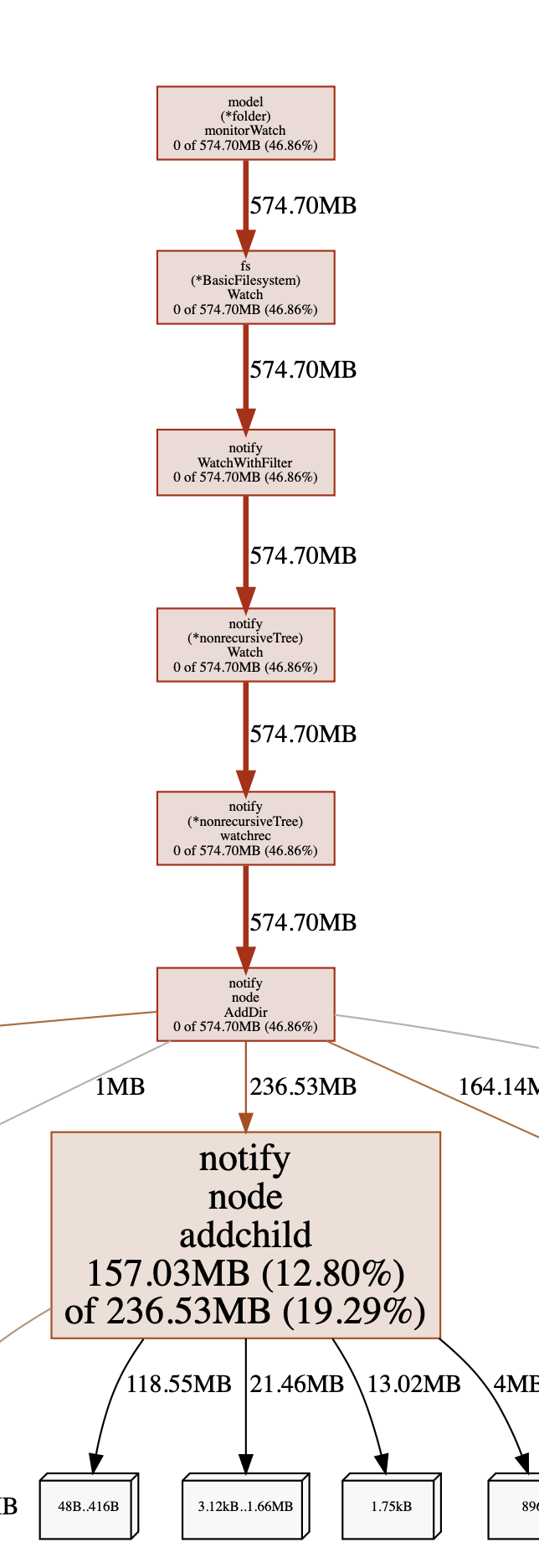
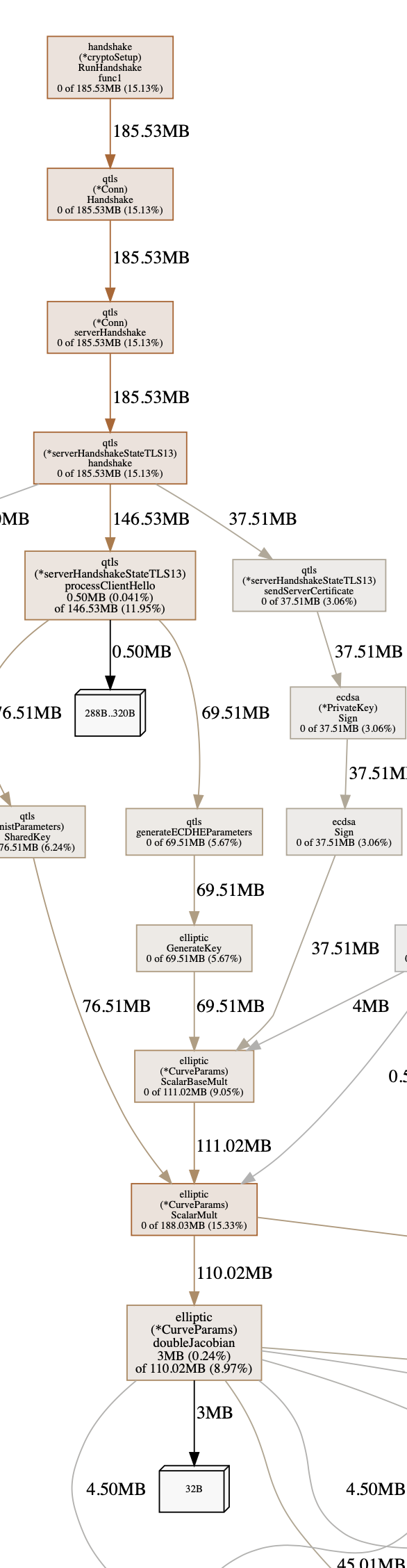
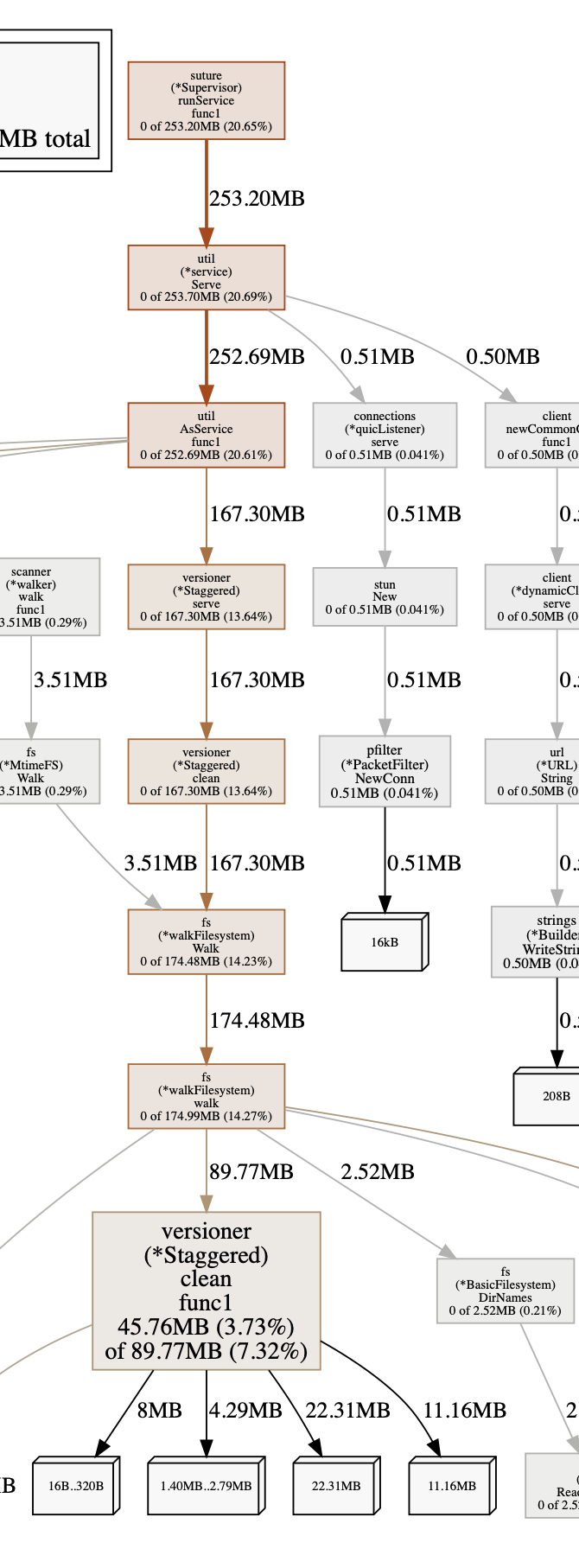
 kudos for taking a profile and showing a screenshot. Being able to talk about something concrete is nice.
kudos for taking a profile and showing a screenshot. Being able to talk about something concrete is nice.