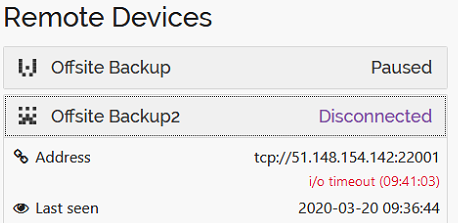
as I have a lot of folders, I split St in to 2 separate installations / 2 PCs. The original St is running fine no errors, however the 2nd installation started falling over after rc2 was installed.
All sending nodes are set to static IP, not dynamic, I use 22000 for the original St, 22001 for the 2nd one.
on one of the failed syncs the logs shows
Connection to KUF3DN7 at 192.168.16.205:22000-81.140.89.112:45725/tcp-server/TLS1.3-TLS_AES_128_GCM_SHA256 closed: protocol error: index update:
which I have not seen before.
NAT is enabled, I turned off local discovery and restarted. The #1 St is only syncing at 7Mbps, I have an 80 connection so I don’t believe it’s bandwidth related.
I might blow away the 2nd St and merge everything back into the single St as it was mentioned before it can get messy and maybe be the reason for the errors, maybe the relays are trying to connect to St #1? But will hold off until you guys have had a look.
There should be something after the last : . Could please post the full log. Sorry, missed the zip you attached at the top. It is
[DA4WN] 00:15:55 INFO: Connection to KUF3DN7 at 192.168.16.205:62089-81.140.89.112:1212/tcp-client/TLS1.3-TLS_AES_128_GCM_SHA256 closed: protocol error: index update: “long/path/to.dll”: file with empty block list
That should be just fine and I don’t see any way it could have an influence on the type of error you’ve shown above.
Oh for fucks sake … Yeah, there’s a bug. We’ll fix that, but the file entry mentioned is toast, you’ll need to touch it somehow on the sending side (KUF3DN7).
On the sending affected PCs I have renamed the files, restarted but they are still not reconnecting, but if I click on rescan it instantly says it’s up to date. I can’t seem to force a full rescan.
On the receiving end, I restarted as it was giving an EOF message on the sending node, now it’s checking the database " Checking db due to upgrade - this may take a while…" despite it being already on rc3
Does that happen on every start or just from rc2 to 3? the latter is expected
the panics “fortunately” are an effect of the rc2 defect. if you stay with all devices paused you shouldn’t get panics. if we can identify the files you can then just touch/move them to fix the problem. alternatively you need to move (and this rehash) the entries folder. from a look at stindex i don’t think it detects this defect (on phone right now). ah no, enable debug model logging, then you see which file it is before the panic
pausing got me in, I know what the affected files are and have renamed them on the sending end and deleted on the receiving end, but it’s showing as disconnected. should I just rename the index folder and start again?
edit, the files came back on the send end, so deleted them again, hopefully it will reconnect
I initially renamed the file that was mentioned in the log on the send end, then after nothing changed I cleared all the files first on the receive end, then as the error remained I cleared all the files within that folder on both ends as it was just a backup on the sending end, so neither end have anything in the above folder.
It will connect for a few seconds, then drops the connection.
I’ve renamed the index folder both ends to see if things move along. Interestingly, the sending end which showed the error, when I renamed the index folder still brought up the “file with empty block list” message which suggests it was the receiving end that may have had the issue, so I then renamed the receiving end index folder.