I’m trying to use syncthing for backing up several large folders (28 TiB overall). Is it performant enough for my needs?
It seems that it breaks down. I was also monitoring the status of my folders via rest api /rest/db/status?folder=… where one call takes up to 15 minutes until i get the response.
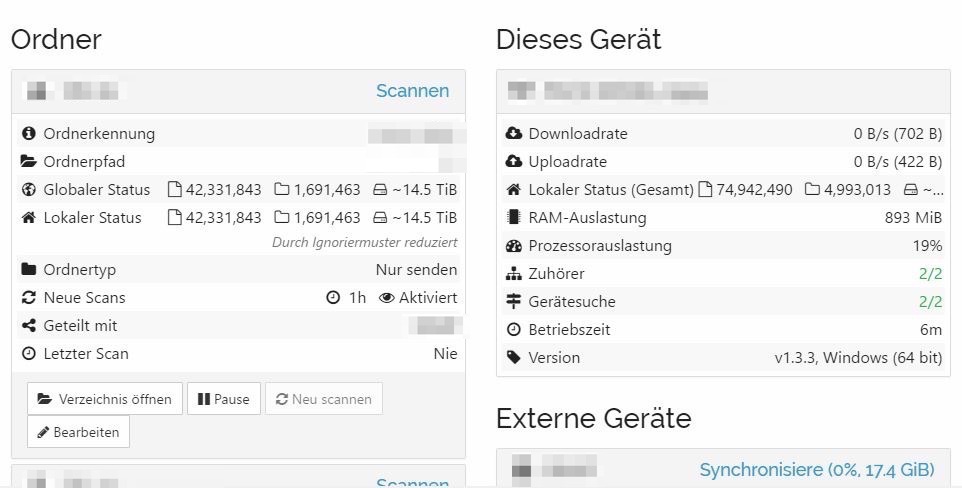
Here is an image of my status page:
Not having dealt with such huge stuff, I don’t have experience – but I would expect that the issue has more to do with the sheer number of files than the amount of data as such.
Yes, the biggest overhead in syncthing is management of database stuff per file, so large number of small files will be the killer of performance. You might want to make sure the database is on an ssd and so on.
It looks like it’s a fresh setup (0% on the remote): The first scan (hash everything) and then first sync will take a lot of time. The latter regardless of whether data is already in sync or not, as even determining that indeed everything is in sync takes time.
If you run on spinning disk, you probably want to limit concurrent scans to 1 (advanced settings). And it might also make sense to not do full scans once an hour, but less, given the huge file tree. And maybe disable scan progress indication if memory usage skyrockets on large changes (set scanProgressIntervalS to negative). If you search for performance related issues you’ll find quite a bit more information. And obviously all of this depends a lot on your exact setup, i.e. what systems, what kind of data, how does it change, how many peers, …
Both of the systems are on Hdds so no SSD option. The folders on one side are on seperate disks on the other side is a single folder on a nas with raid 5. I set the concurrent scans to 1 on the nas side.
Memory is no problem but I set the scanProgressIntervalS to negative anyway. The scan interval is increased to 10h too.
And it is not a fresh setup. The system runs for 2 weeks now but is not finished at all. In that time synching was restarted sometimes(on both sides). Some of the folders are in sync already but first folder shown in the picture is still in initial scan.
I’ve search for performance topics here in the forum and in the GitHub issues but can’t find any more tweaks I can do. Are there more screws that I can turn?
Also the OS? With a system this size it seems to me like a really small investment to get an SSD for that, including the Syncthing db. If you have really memory to spare, you could even move the db there.
I have about 600,000 files in Syncthing, which is much fewer than in your case, but I always also set fsWatcherDelayS="60" for all my folders, just to delay syncing a little bit. This may help if you have many files changing constantly.
I also set progressUpdateIntervalS to -1, although I do not think that this has any impact on the IO performance, or does it?
Ok then I’ve to deal with that.
But is there a better way of monitoring if the sync is working or has errors?
Atm. I’m querying /rest/db/status?folder=… and looking for “errors” : 0
Is it a performance difference if I would check /rest/db/completion? Or is it the same because of the DB access?
Btw. the docs under docs.syncthing.net aren’t up to date. /rest/db/status has now also an error property.
@imsodin The OS is Windows with the seperate disks and Linux with the raid. And sadly no I’ve no option to do that.
@tomasz86 thy for the advice but the files didn’t change regulary.
Coming back to that: The first folder on the left shows “Letzer Scan: Nie”, i.e. it never completed any scan. That’s what I meant by “fresh”, together with the 0% remote device. Given the amount of data and everything on spinners, this will take a while. I’d expect large speedups from the concurrent scan limit. I’d also pause all external devices until the first scan is through (with db on spinners you want as few db interactions as possible). And then just be patient.
What is it you want to know? If you want scan/sync errors, it must be db/status. Same for any completion metrics for local devices. db/completion is for remote devices (might work for locals too, but there’s no point).