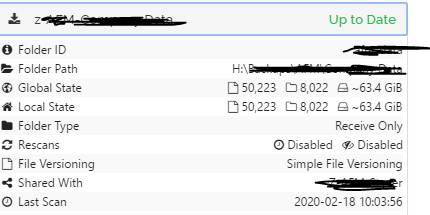
Another thing i’ve started to see, and don’t know if this is related or is a bug in itself, is the jobs say that are up to date, yet the local state differs to the global state. If I try a rescan on that job it comes straight back to being up to date.
it’s not all the jobs,
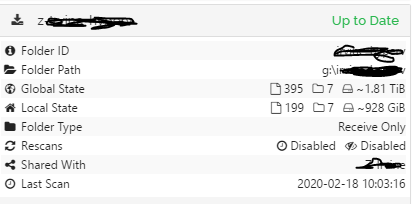
and not related to large jobs…
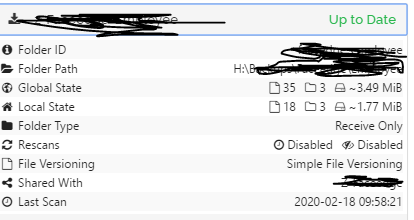
it’s just some folders, the majority are correct…