I’m syncing a folder containing large images of 20 GiB, 40GiB some images are even 900 GiB.
After updating to 0.14.48 I enabled Large Blocks.
Since then my RAM Util has quadrupled at around 11 GiB (I’ve 8GB available) and I get errors rapidly stating:
“Listen (BEP/tcp): Accepting connection: accept tcp [::]:46953: accept4: too many open files”
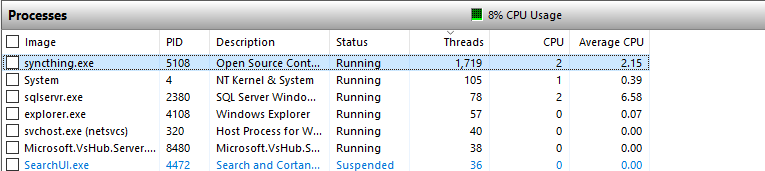
I’ve tried a system reboot followed by disabling syncing, so the scanning could finish in peace, restarting syncthing, letting the startup scan finish and THEN enabling syncing between devices. This solved my RAM problem, now at 3.4 GiB RAM Util, but I’m still not utilising my bandwidth (based on measured upload between clients) and I still get the error stated above. Also, why so many threads? over 9000 threads seems excessive…
Hope there is enough information here to get started
The prime suspect for the too many open files error is the filesystem watcher. Did you also enable that at the same time or did you use that before (was enabled in 0.14.47) without problems? Or even better, can you reproduce the problem with filesystem watcher disabled?
How did you determine the 9000 threads - do you have a stack trace? If yes, share it please. Generally logs from during the high ram phase would help. And 3.4 GiB ram during sync seems like a lot, but it’s possible.
I don’t understand why that helped, it was possibly unrelated, as one folder never scans and syncs at the same time.
Go spawns a thread per blocking io operation, I suspect we somehow are trying to read too much, as someone that is requesting blocks is requesting too many, causing disk thrashing and running out of fd’s. As this happens, can you send a sigquit to the process and capture stdout/err?
Yeah… Check that the pullerMaxPendingKiB advanced folder setting on the other side is reasonable, where reasonable means zero or ~ 32768 - 65536 or thereabout.
I tried it, but the “sigquit” did nothing to the process…
I was running the following strace command found from the web (the number 21284 represents PID):
I noticed a high number of threads too, switched “Large Blocks” on in case that helped, and it didn’t. So the problem isn’t caused by large blocks. I do have “watch for changes” on.
You can send the quit signal to the syncthing process by finding its pid (e.g. ps auxf | grep syncthing and then calling kill -SIGQUIT *pid*. If you are running Syncthing as a systemd service, you will find the output in the journal (i.e. journalctl -u syncthing@*yourUserName* or probably journaclt --user -u syncthing if you are running it as user service (not sure, because I don’t use user services).
We need to know what those threads are to say anything about why they are even they and what will happen with them. No idea how to do that on windows though.
I can see that the Putty history doesn’t go back very far… if information is missing and I need to bump up the history line cap, let me know.
Other observation - Jakob wrote:
I have incremently change one device per 12 hours to observe difference in behaviour. The last machine out of 3 connected devices, which was changed from 1048576 to 0 might have solved my RAM and Too Many Open files problem… RAM without loading WebGUI stays under 1 GiB RAM usage. Loading the webGUI brings up the RAM usage to 4 GiB RAM usage and stays there even after closing the webGUI.
Loading the webGUI (RAM goes up to 4 GIB), and then calling a restart on Syncthing while leaving my webGUI window open holds the RAM usage down at 800 MiB RAM Usage WITH webGUI reconnected open.
Byproduct - slow transfer… changing pullerMaxPendingKiB to 0 has brought transfer speeds down from 92% Upload bandwidth Util to 0.1%
What’s visible in the backtrace is indeed sending of data. The puller max pending KiB is how much data any given device will request from another at a time, for that folder. If you set that to a gigabyte, like in your example, you can expect the sending side to use several gigabytes of RAM to serve those requests - read buffers, serialization buffers, send buffers, garbage collection overhead. The default (that you get when set to zero) is 32 MiB, IIRC.
With one gigabyte max pending and small blocks you get 1 GiB / 128 KiB = 8192 simultaneous data requests. Each of those are likely to consume a thread. I think that is your original issue. With large blocks you get a bit less, 1 GiB / 16 MiB = 64 simultaneous requests. RAM usage is the same though, except less thread overhead.
Maybe there would be an advantage to also adding a limit on number of outstanding pull requests to lower the number of default requests on a large pull: defaultPullerPending / MinBlockSize = 32MiB / 128KiB = 256. This is four times the previous default (64 pullers). I am just writing down something I noticed, I did not think about the implications, maybe more pullers is a good thing and totally unproblematic.