I have a folder that causes Syncthing to run out of memory and crash while scanning. Here are the facts:
Debian 4.4.91.x86_64.1 (Netgear ReadyNAS) 4GB RAM, 4GB swap, Syncthing 0.14.43 official deb from apt repo
Largest file in “Backup” folder is 820 GiB, well under 1.25 TiB limit
Scanning reaches approximately 60%, then runs out of memory and crashes
Other folders on same machines sync OK so I assume all is well with Syncthing installation and config.
Hashers, copiers and pullers are set to 1.
No other applications are running on machine
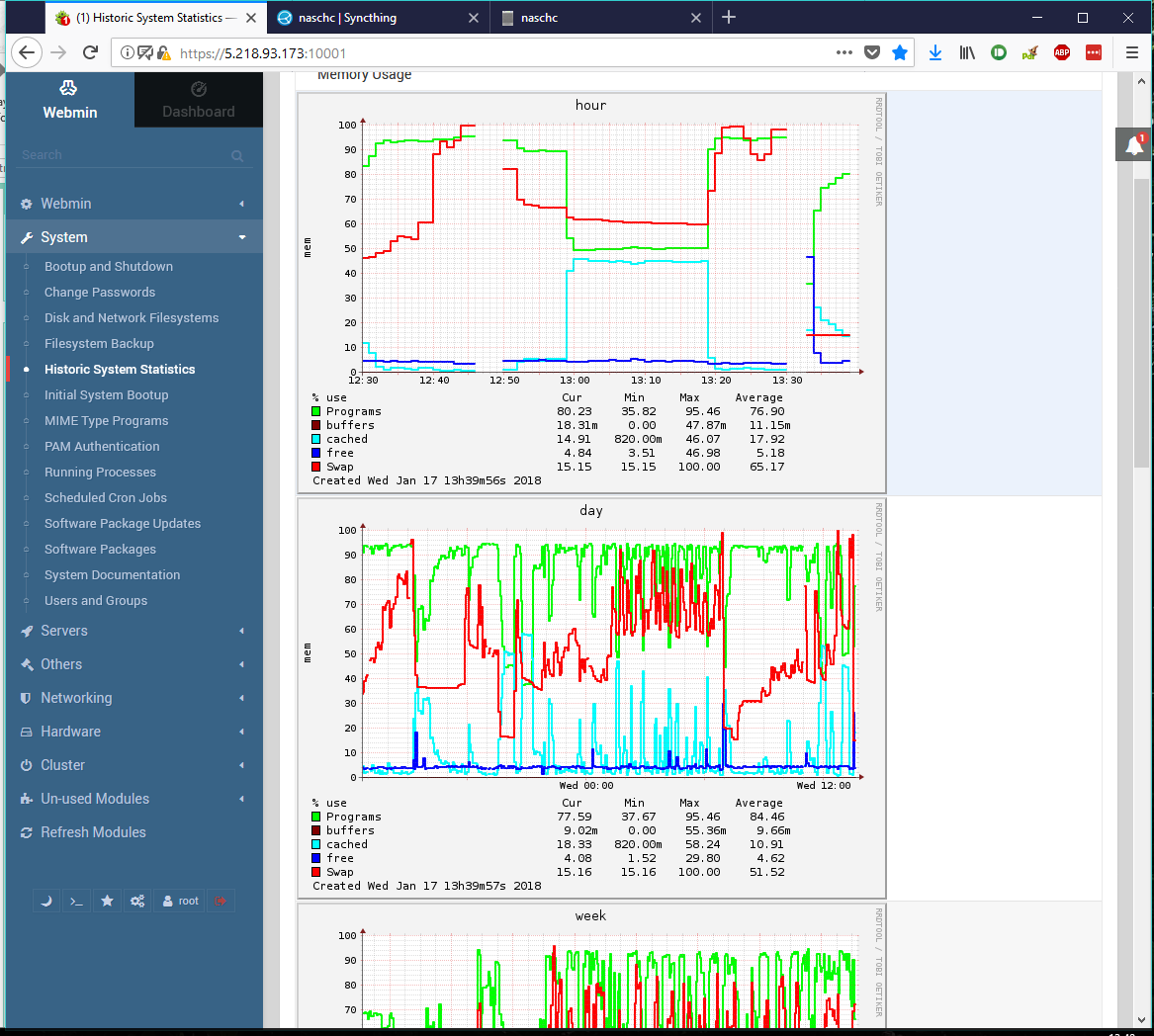
Screenshots below are showing Syncthing console few minutes after the crash, and memory use for hour and day 0 in same point in time. [EDIT - seems new users are allowed only one pic upload. Will post the other one on request]
On the memory graphs, you can clearly see the pint where both green and red lines repeatedly reach 100%. Game over.
Gaps in memory use graphs are caused by machine swapping so heavily that probe that collects memory data timeouts
I check the FAQ and forum, but found no immediately obvious advice. I notice that similar issues where reported on more than few occasions. I have the impression that 4GB of ram would generally be acceptable for this task?
As only significant difference of this folder are the very large single files, my working assumption is that this is the cause of the issue?
What else can I do to troubleshoot/workaround this?
You can try setting scanProgressInterval to -1 but I doubt that will help. You could try setting GOGC env var to like 5, to trigger garbage collection more often. I guess you’d have to get a memory profile just before it crashes to understand where the space is going.
Yes. The minimum thing we need to keep in RAM while scanning is the block list for the file currently being scanned. If the file is large, this can be a lot of memory. There is no workaround for that at the moment.
Only very approximately, unfortunately. For the block list itself in the first instance you can estimate 48 bytes per 128 KiB of file data. But then things happen:
It gets serialized into protobuf format, which is a new copy in a different memory layout
It gets saved to the database, which means it gets copied again into a transaction structure, written and saved etc (not sure what happens in the database layer)
It gets sent over the network, which means wrapping in another structure and protobuf-encoding again, then encrypted which is another copy, etc
Add garbage collection overhead
The devil is in the different copies and stuff. How many of those happen and are allocated at the same time? Not sure. Count on several.
Many thanks for that; So for my 850GiB file, one instance of block list would be about 307 MiB. My guesstimate for “several” would therefore be 1GiB. OK, lets say 2.
I have 6.3 free/available before the scan starts, and ends with OOM crash.
Tried Dropbpox, Mega and Resilio - just the scan part. Resilio had the highest memory footprint, using just above 2GiB. Dropbox took longest time, but memory use was lowest, barely about 100MB. All completed scan successfully.
Compared with 6.3GiB not being enough for Syncthing (how much would be enough? Dont know. Cant add more RAM to the NAS and cant add more swap to BTRFS)
If I buy a new 8GB NAS box, would it work? 16?
More importantly - it seems that what I see is significantly different from what you described as expected. Is there a chance some of the “several” copies of block list is either created in error, or possibly not released appropriately?
Or is there a chance this scan process can be optimized? Perhaps by using file system/database instead of RAM?
I’m guessing that out of those you tested resilio is the only one with a block based approach. Dropbox can have very low memory usage but will probably upload and download the whole file on change, for example.
I don’t know how much memory will be enough. There are other factors like the number of connected devices acting as a multiplier on any if the things I mentioned above.
Optimizing things so that the whole block list for a file isn’t needed in RAM isn’t something that is likely to happen soon or possibly ever, unfortunately
What might happen before then is variable block size, which would solve this by reducing the number of blocks to something reasonable.
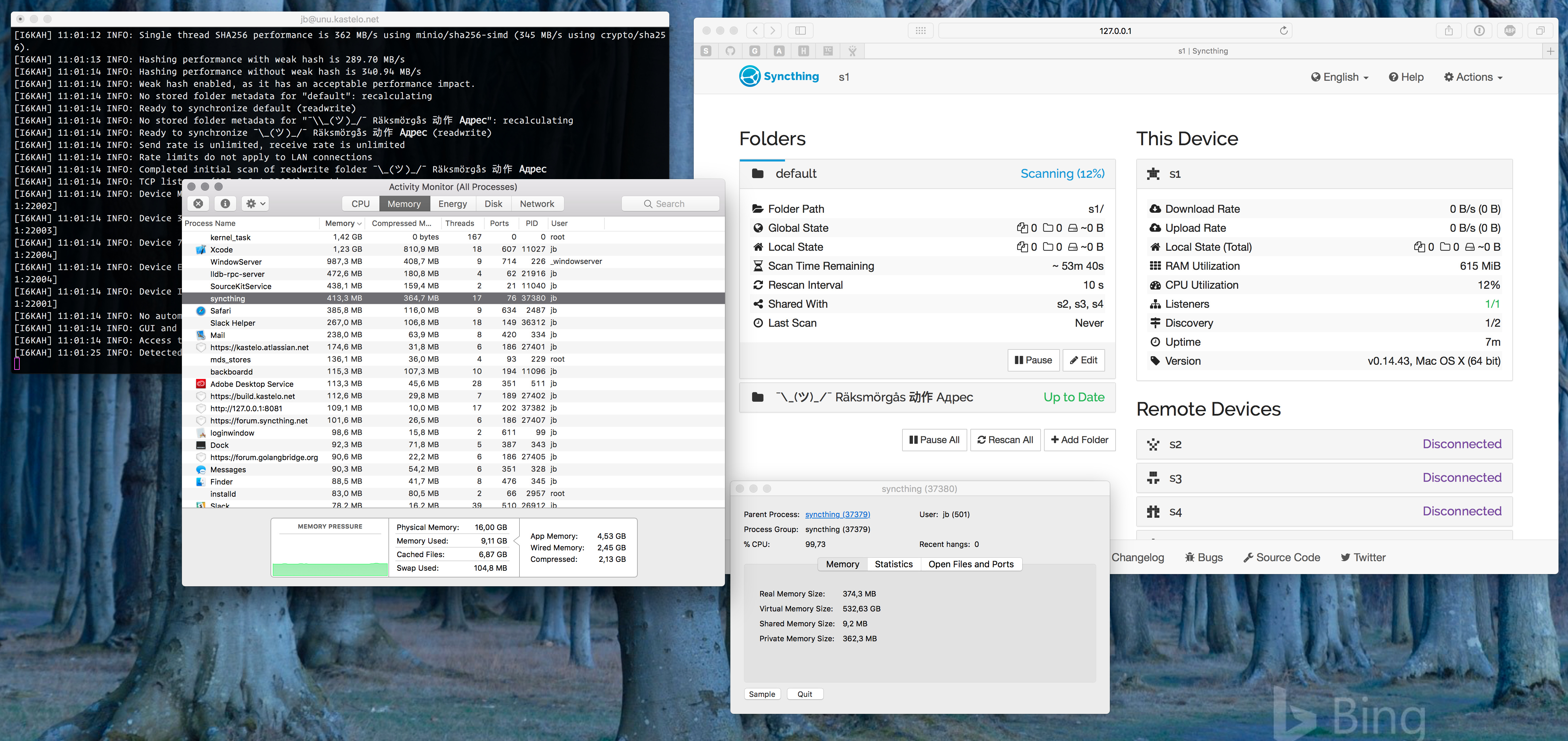
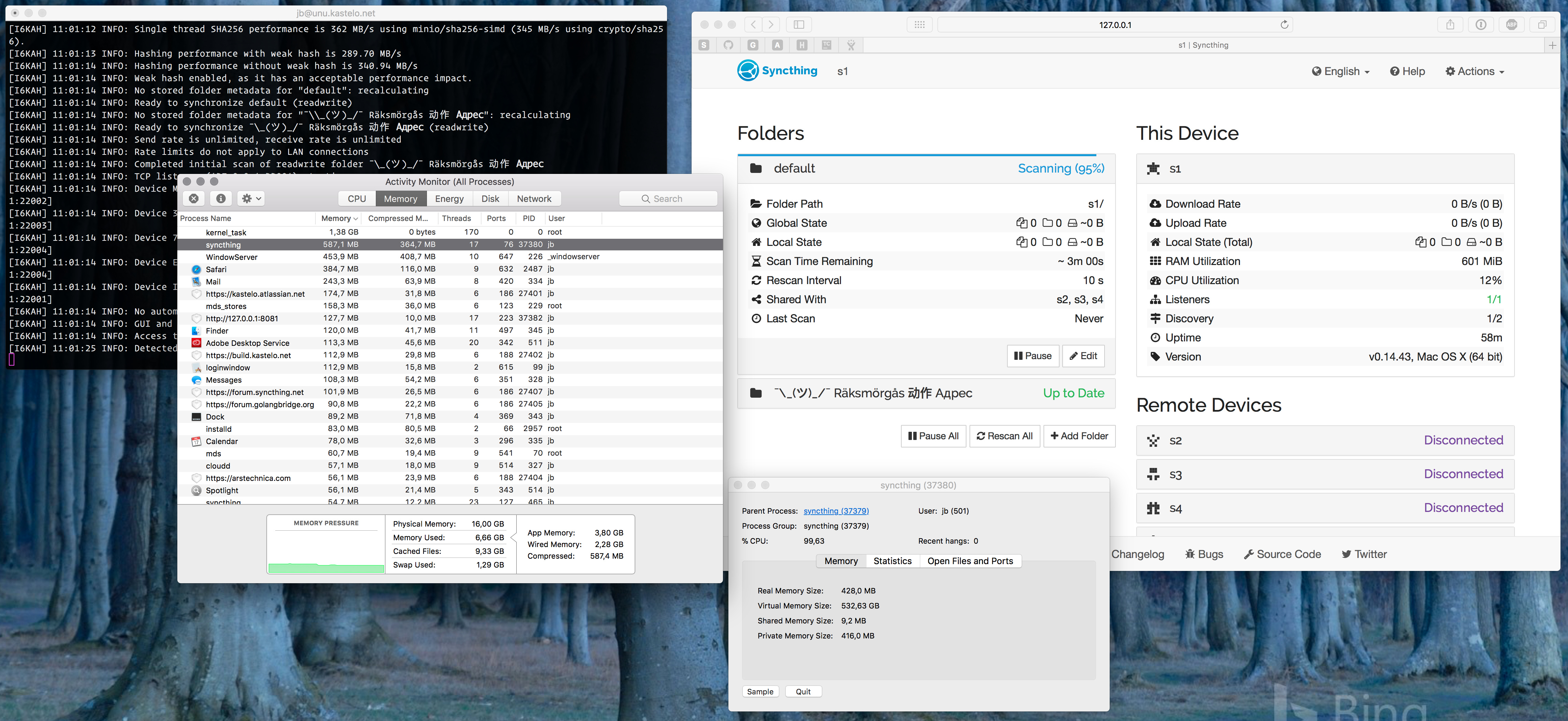
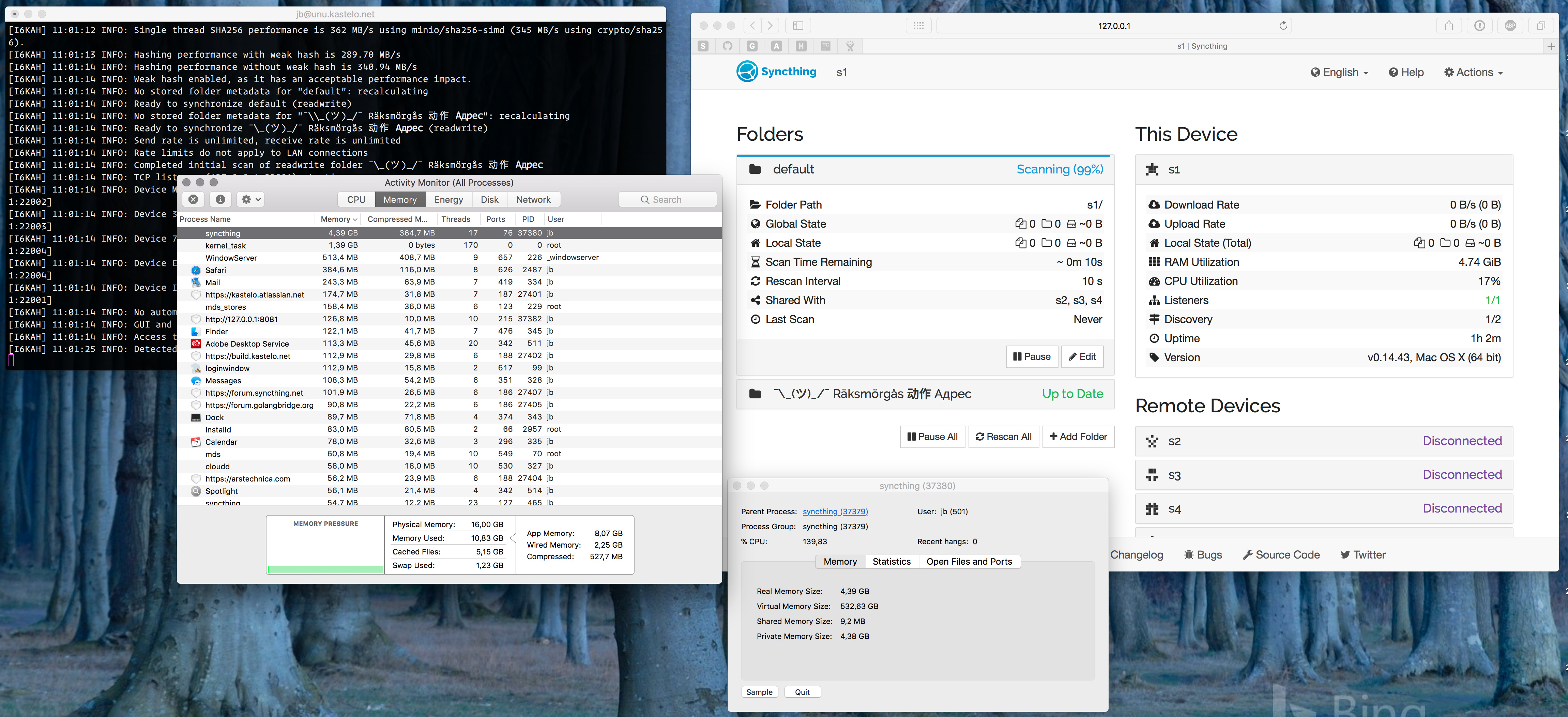
I tested this with a 900 GB file to see what happens. The scanning process itself is consistent with expectations, with Syncthing self reporting a usage of 600 MB and the OS seeing slightly less but increasing during the scan (as memory is actually written to and not just allocated).
I’d say there’s room for improvement in this stage, but without making any promises as I don’t know how much of this happens inside the protobuf and database packages that are third party.
I recently added a PR that made this problem worse. Fixing this I found a lot ofa little headway to improve (two copies), I am writing a PR as I type this (well not literally, but almost ).
If you’re thinking of what I think you’re thinking of, note that copying the file list is shallow so doesn’t copy the block list. But I’m sure we do other things that might be better off with less copies.
Yep. The fileinfo contains the block slice, copying the fileinfo just copies the blocks slice header. The code you show is a problem if you’re juggling a million files, but we don’t do that.
Well, I’ll file the PR anyway, because I also kill some lines
So if you consider it more/equal readable to the existing code, we might as well use it.
But then that sounds like it is really hard to duplicate that stuff in Go and thus it’s unlikely that we (as opposed to dependencies) are responsible for this memory peak.
Yeah while in block list form it’s probably fine, it’s when we serialize (copy), batch (copy), compress (copy), encrypt (copy), send (copy), etc it blows up I think. So in the database and protocol layers.
Variable ? What do you mean ? Hand set by the user or automaticaly computed according the mean size of files handled (and memory available) ? Would that mean dynamicaly adapted ?
Thanks.
Not extremely likely, no. By itself it’s not super tricky, but there are corner cases and it’s a compatibility break with existing versions which is something we need to handle.
Sorry to hear that… it would seem a lot of modestly sized devices frequently used to handle data storage - which are a natural target for Syncthing - are not able to use it with larger files which are only going to become larger as time goes by.
At least this limitation should be visibly stated somewhere on the Syncthing website, so people with Raspbery Pi and home-grade NAS boxes dont waste days trying to make this work in vain.
 ).
).
