I’m really appreciating Syncthing, and I wanted to give something back.
I have a couple of cheap $5/month VPS’s rented, and I get 2TB/month of bandwidth, whether I use it or not. I run low-traffic websites for personal use on these VPS’s, and I hardly use any of that 2TB/month up, every month.
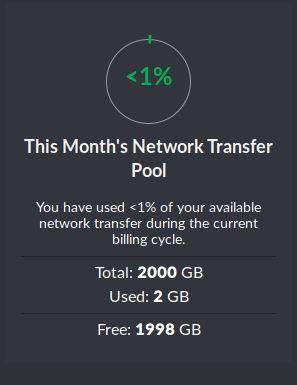
The billing cycle with my hosting provider happens on the 1st of every month, and it occurred to me that I only have a few days left in the month to use or lose all those GB of bandwidth. My hosting provider has a nice dashboard showing how many GB of bandwidth remain:
I wanted to have some fun running that “Network Transfer” dial up to close to 100%. I’ll just Ctrl+C those Open Relays, once they’ve “slurped up” all the bandwidth I’m willing to allow. I figure it’ll take a day or two of running both with a bandwidth limit of 15MB/sec, meaning, I’ll start strelaysrv with “-global-rate=15728640”.
After a couple of hours, the relays are starting to slowly fill with traffic, which I’m checking periodically at https://relays.syncthing.net/
After a few hours, I’ve been only able to give away like 2GB!
It’s harder than I thought to give away these GB. It’s as though they’re afflicted with a disease or something.
One of my VPS’s is much more popular than the other (even though they apparently live in the same datacenter in Frankfurt, Germany). Note that these two VPS’s are only 12ms apart from each other, when I do a traceroute from one to the other.
I’ve jacked up the “-global-rate=” higher on the more popular one…
I don’t think you can expect instant traffic: Relays are chosen on startup, so you only get devices with time. And as you can see on the map on relays.syncthing.net the area around Frankfurt is already well served, so there simply might not be that much traffic to get (that’s pure speculation though).
Also 2GB in a few hours doesn’t sound so bad, that’s TBs in a few weeks, so pretty much what you’re aiming for. I guess the best option would be if you could programmatically get the used bandwidth from your provider to stop the relay server once it’s above a certain threshold with a script.
It turns out it’s easy at my hosting provider to set up a “Notification Threshold” such that I’ll get an automated email when the “Transfer Quota” goes over a certain percentage of my choosing (and I set it to 90%):
When I did this on a linode, I had a little script which periodically checked the API, and disabled relaysrv when I reached 90% of my usage limit (then re-enabled it once the month rolled over).
#!/usr/bin/env ruby
require 'linode'
CUTOFF_PERCENT = 90
UNIT = 'syncthing-relaysrv.service'
API_KEY = "YOUR API KEY"
is_running = `/usr/bin/systemctl is-active #{UNIT}`.chomp == 'active'
l = Linode.new(:api_key => API_KEY)
account_info = l.account.info
used_gb = account_info.transfer_used
total_gb = account_info.transfer_pool
used_percent = used_gb.fdiv(total_gb) * 100.0
if used_percent > CUTOFF_PERCENT
if is_running
puts "Used #{used_gb}GB/#{total_gb}GB (#{used_percent})%"
puts "KILLING"
`/usr/bin/systemctl stop #{UNIT}`
`/usr/bin/systemctl disable #{UNIT}`
end
else
if !is_running
puts "Used #{used_gb}GB/#{total_gb}GB (#{used_percent})%"
puts "STARTING"
`/usr/bin/systemctl start #{UNIT}`
`/usr/bin/systemctl enable #{UNIT}`
end
end
This used the linode gem – gem install linode. That was then set to run hourly in crontab.
Thanks for the script, @canton7. I’ll see about setting it up later.
My VPS’s have been up for just about a day now, and they only relayed about 6GB of traffic.
I agree that picking a low-latency relay is a good idea (to minimise the round-trip times for all the small blocks you send over the network), but if one is located in a part of the world where there is a paucity of relays, wouldn’t it be smart to relax the desire, in that case, to require low-latency, and instead use some of the underused relays in “oversupplied” regions like Germany? That traffic could be internally labelled as “second-class-blocks”, to be gracefully dropped (or handed off somehow) once the relay’s idleness (in the oversupplied region) gets enough local connections (the first-class blocks) to actually saturate the available bandwidth the relay has been permitted?
I guess I’m proposing a sort of 1st class and 2nd-class labelling of relay traffic (1st-class means the relay is low latency, 2nd class is higher latency, continuously sent through an idle relay, on a tentative basis, only while a relay isn’t saturated with 1st-class traffic), to mop up the unused capacity, from relays like mine, that are sitting there twiddling their thumbs, while the few relays in places like Singapore work the hardest, and may give degraded speeds on account of being overloaded.
Let me speak very clearly about my use of the terms “1st class” and “2nd class”. These aren’t labels for people, calling them 1st class or 2nd class, in a derogatory sort of way. This is a instead a distinction for the blocks themselves, distinguishing between low-latency and high-latency-sent-only-when-a-relay-is-unsaturated-with-low-latency traffic.
If there is different labelling besides “1st class” and “2nd class” that would be more appropriate, then, please propose it.
Similar things have been proposed before, as the choice entirely based on latency definitely doesn’t have to be the best choice (e.g. a low latency relay with almost no bandwidth). However relays are only meant as a last measure of connection, so there isn’t much incentive to work on it. Also it’s not an easy problem either. And a process to connect even if both sides are behind NAT hast just been merged, so the need of relays may drop even more soon.
Maybe I’m making a wrong assumption here, and please correct me if I’m wrong. I’m also just a little fuzzy here, as it’s not easy for me to wrap my head around the networking used here. (I do get how firewalls get transcended, and no relay gets used, if either side can open a port, using UPnP if necessary).
Perhaps what’s happening, and I just wouldn’t know any better, is that there is a general oversupply of relays, globally, and there just isn’t enough demand for the bandwidth they’re offering, globally.
In other words, maybe it’s the case that whenever someone wants a relay, they get one, and the bandwidth available (never mind Syncthing’s algorithms internally) gets used as the Internet can actually supply it.
I expect everyone does get a relay connection, and when they need some bandwidth (which may be hours, days or weeks later…) they get some bandwidth and things mostly work. Probably most Syncthing setups are idle >99% of the time so traffic is very bursty and probably unevenly distributed. The limitations are obscure, most transfers are probably not observed by a human, most slowness goes unnoticed.
Before the relay system there were daily support posts to the tune of “why don’t my devices connect”. That pretty much never happens any more. With the merged QUIC support we might indeed see relay traffic significantly reduced. It’s currently about 20% of the total;
Just FYI, in the spirit of the OP, I checked my bandwidth usage, as my billing cycle is just about to end (and I won’t be able to see how much GB I actually used up for the month of May any longer).
In the 3 days I’ve been running my 2 relays, 60GB got used. So if I roughly allow 20GB/day, then in a 30-day month, that’s a mere 600GB, which is well within the 2000GB I’m allowed in a month (1000GB per VPS).
I want to say a huge kudos for making Syncthing so awesome! The relays being under-utilized is actually a good problem to have. It’s a much better problem than not having enough willing participants to provide relays.
I’ll likely still install @canton7’s script none the less, just to be safe, as of course it can get bursty when I least expect it. Germany may have a sudden surge in cat photos that need syncing around.