New panic
syncthing.log (314.1 KB)
Probably related, but one of the remote computers has this
This is due to interactions of locks on lockedWriterAt, sharedPullerState (these first two are actually the same lock), progressEmitter and finally model.pmut…
This goroutine is holding a lock on the lockedWriterAt
goroutine 45054 [syscall, 96 minutes, locked to thread]:
syscall.Syscall6(0x7ff8367b2500, 0x5, 0xad0, 0xc01a800000, 0x1000000, 0xc000eb9ad4, 0xc000eb9af0, 0x0, 0x0, 0x0, ...)
C:/Go/src/runtime/syscall_windows.go:197 +0xed
syscall.WriteFile(0xad0, 0xc01a800000, 0x1000000, 0x1000000, 0xc000eb9ad4, 0xc000eb9af0, 0x20, 0x0)
C:/Go/src/syscall/zsyscall_windows.go:329 +0xd5
internal/poll.(*FD).Pwrite(0xc003cbb900, 0xc01a800000, 0x1000000, 0x1000000, 0xbb0d000000, 0x0, 0x0, 0x0)
C:/Go/src/internal/poll/fd_windows.go:775 +0x25e
os.(*File).pwrite(...)
C:/Go/src/os/file_windows.go:232
os.(*File).WriteAt(0xc000a0fa68, 0xc01a800000, 0x1000000, 0x1000000, 0xbb0d000000, 0x0, 0x0, 0x0)
C:/Go/src/os/file.go:175 +0x10a
github.com/syncthing/syncthing/lib/model.lockedWriterAt.WriteAt(0xc003cbb8d0, 0x9724d20, 0xc0031d65c0, 0xc01a800000, 0x1000000, 0x1000000, 0xbb0d000000, 0x0, 0x0, 0x0)
C:/BuildAgent/work/174e136266f8a219/lib/model/sharedpullerstate.go:75 +0xc0
github.com/syncthing/syncthing/lib/model.(*sendReceiveFolder).pullBlock(0xc003f32300, 0xc003cbb680, 0xbb0d000000, 0x1000000, 0xc00496e4e0, 0x20, 0x20, 0xa13640a6, 0xc0055306c0)
C:/BuildAgent/work/174e136266f8a219/lib/model/folder_sendrecv.go:1483 +0x9f0
github.com/syncthing/syncthing/lib/model.(*sendReceiveFolder).pullerRoutine.func1(0x104f580, 0xc004fac720, 0xc00379c300, 0x1000000, 0xc003f32300, 0xc003cbb680, 0xbb0d000000, 0x1000000, 0xc00496e4e0, 0x20, ...)
C:/BuildAgent/work/174e136266f8a219/lib/model/folder_sendrecv.go:1414 +0xd5
created by github.com/syncthing/syncthing/lib/model.(*sendReceiveFolder).pullerRoutine
C:/BuildAgent/work/174e136266f8a219/lib/model/folder_sendrecv.go:1410 +0x332
Not quite sure what locked to thread means, but @terry is it possible you have very high load (probably on disk IO)? In that case strictly speaking this is a false positive of the deadlock detector, as once that read goes through everything will get unblocked.
Nevertheless, the following chaining of locks is at least not ideal:
Holds lock on progressEmitter, waits on sharedPullerState, as that uses the same lock for the writer above and for it’s members.
return lockedWriterAt{&s.mut, s.fd}, nil
sync.runtime_SemacquireMutex(0xc00778a82c, 0xc002edcc00)
C:/Go/src/runtime/sema.go:71 +0x44
sync.(*RWMutex).RLock(0xc00778a820)
C:/Go/src/sync/rwmutex.go:50 +0x55
github.com/syncthing/syncthing/lib/model.(*sharedPullerState).Updated(0xc003cbb680, 0xc002edcc60, 0xc000293e18, 0x2)
C:/BuildAgent/work/174e136266f8a219/lib/model/sharedpullerstate.go:313 +0x45
github.com/syncthing/syncthing/lib/model.(*ProgressEmitter).serve(0xc000194120, 0xc000308fc0)
C:/BuildAgent/work/174e136266f8a219/lib/model/progressemitter.go:74 +0xb9
github.com/syncthing/syncthing/lib/util.AsService.func1(0xc000308fc0, 0xf49430, 0xc0000f8300)
C:/BuildAgent/work/174e136266f8a219/lib/util/utils.go:182 +0x36
github.com/syncthing/syncthing/lib/util.(*service).Serve(0xc0000f8300)
C:/BuildAgent/work/174e136266f8a219/lib/util/utils.go:233 +0x11a
github.com/thejerf/suture.(*Supervisor).runService.func1(0xc0001c6870, 0xc000000000, 0x1047f00, 0xc000194120)
C:/BuildAgent/work/pkg/mod/github.com/thejerf/suture@v3.0.2+incompatible/supervisor.go:600 +0x4e
created by github.com/thejerf/suture.(*Supervisor).runService
C:/BuildAgent/work/pkg/mod/github.com/thejerf/suture@v3.0.2+incompatible/supervisor.go:588 +0x62
Then e.g. this routine holds pmut (write) and blocks due to the progressEmitter lock above:
goroutine 877 [semacquire, 24 minutes]:
sync.runtime_SemacquireMutex(0xc0001e2194, 0x9011f55fb2c5c500)
C:/Go/src/runtime/sema.go:71 +0x44
sync.(*Mutex).Lock(0xc0001e2190)
C:/Go/src/sync/mutex.go:134 +0x110
github.com/syncthing/syncthing/lib/model.(*ProgressEmitter).temporaryIndexUnsubscribe(0xc000194120, 0x53e5b88, 0xc002b1b950)
C:/BuildAgent/work/174e136266f8a219/lib/model/progressemitter.go:297 +0x3f
github.com/syncthing/syncthing/lib/model.(*model).Closed(0xc00062a420, 0x53e5b88, 0xc002b1b950, 0x103ea00, 0xc0029db920)
C:/BuildAgent/work/174e136266f8a219/lib/model/model.go:1425 +0x17c
github.com/syncthing/syncthing/lib/protocol.(*rawConnection).internalClose.func1()
C:/BuildAgent/work/174e136266f8a219/lib/protocol/protocol.go:912 +0x221
sync.(*Once).Do(0xc00068df90, 0xc003a63ed8)
C:/Go/src/sync/once.go:44 +0xba
github.com/syncthing/syncthing/lib/protocol.(*rawConnection).internalClose(0xc00068dee0, 0x103ea00, 0xc0029db920)
C:/BuildAgent/work/174e136266f8a219/lib/protocol/protocol.go:897 +0x76
github.com/syncthing/syncthing/lib/protocol.(*rawConnection).readerLoop(0xc00068dee0)
C:/BuildAgent/work/174e136266f8a219/lib/protocol/protocol.go:381 +0x119
created by github.com/syncthing/syncthing/lib/protocol.(*rawConnection).Start
C:/BuildAgent/work/174e136266f8a219/lib/protocol/protocol.go:255 +0x4a
My take-away is, that whenever doing something while holding a lock, I need to know the entire code that may be executed while holding a lock - especially in the model package as everything is so intertwined. And as a corollary as that might be too tedious: Don’t hold a lock when calling non-trivial functions.
Anyone knows about a linter that can list all nested lock acquisitions? 
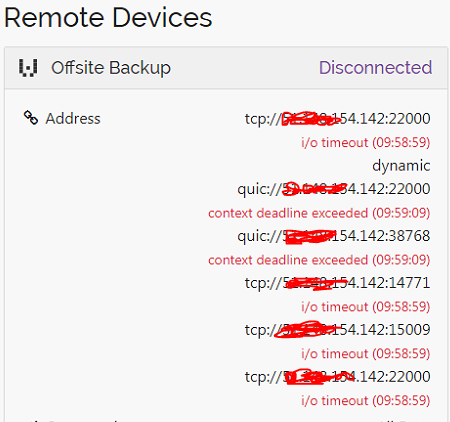
I do have the offsite backup on a USB 3 external hard drive, however it’s receive only and no watchers enabled / scanning disabled so for most of the time it’s running idle. Only time it hits 100% IO is after updates or host restarts, but that’s usually full on for around 6 hours and then calms down.
The panic happened around 08:30 so would have been idling at the time.
As an additional thought, I was unable to kill the Syncthing task and had to restart the host computer. Not sure if it’s relevant.
This panic is because a file write operation blocked for 96mins. I suspect this is some network attached storage that disappeared.
Locked to thread is just telling that this routine has to run on this thread (because io is not async on all platforms and go spawns a thread per io operation, so moving a goroutine which is waiting for io to complete to a different thread makes no sense, as the thread cannot be reused and the routine will not unblock by being moved to a different thread).
The storage is a USB drive which is only a few months old and there’s nothing in the logs to suggest a disk / controller error. As I mentioned previously, I wasn’t able to kill the St instance, not even via sysinternals process explorer. When I tried a restart, it was clear that even windows wasn’t able to shutdown St so I resorted to a hard power off.
Therefore could there has been some sort of crash within St that could have given the same results? So it was functioning (eg logs) yet so hung that it was in some endless loop?
Sometimes OS prevents killing a process if the process is stuck in a syscall. This process was stuck in a syscall writing to your storage.
You can keep pointing your fingers at syncthing, but I’ll keep pointing my fingers at your storage, as that is what the stacktrace is saying.
The fact that the USB drive a few months old doesn’t mean it wasn’t from a vending machine for 1$ made by some shobby vendor, using some shobby firmware and shobby parts. Hanging and not returning would not show up as a controller error, it would simply hang on an IO operation most likely.
I think these sort of hangs should show up in syslog for normal drives, for USB drives, I reckon it goes into enable-NFS-maverick-mode where it ignores all failures and assume it’s just garbage it’s dealing with.
I accept your explanation. No idea what could have caused it then. Maybe the AV kicked in with an update, but it was so soon after rc2 that I thought it was worth mentioning.
This topic was automatically closed 30 days after the last reply. New replies are no longer allowed.