I set up Syncthing a week ago. I have two servers with two folders, one server send-only, the other receive-only. Each folder has several TBs of data. For some reason, whenever I restart Syncthing on the receiving server, one of the two folders does a full high-CPU-usage scan which takes hours to complete. The other folder detects “up to date” after a brief check, as do both folders on the sending server when Syncthing is restarted. No files in either folder were changed on either system between Syncthing restarts. Restarts have been either after system reboot or after updating Syncthing. Why is this one folder on the one server behaving this way, when it should quickly detect no changes as the others do?
There is too little data to work with, really. At the very least, please provide basic information about the environment (hardware, operating system, Syncthing version, etc.). Screenshots showing the Web GUI in full are always welcome as well.
Is there anything special about the folders themselves? Is there any difference in the type of storage where each of them resides or are they both located on the same storage? Do the folders consist of a small number of large files or many small ones? Again, screenshots showing each of the two folders in the GUI will be helpful.
1 Like
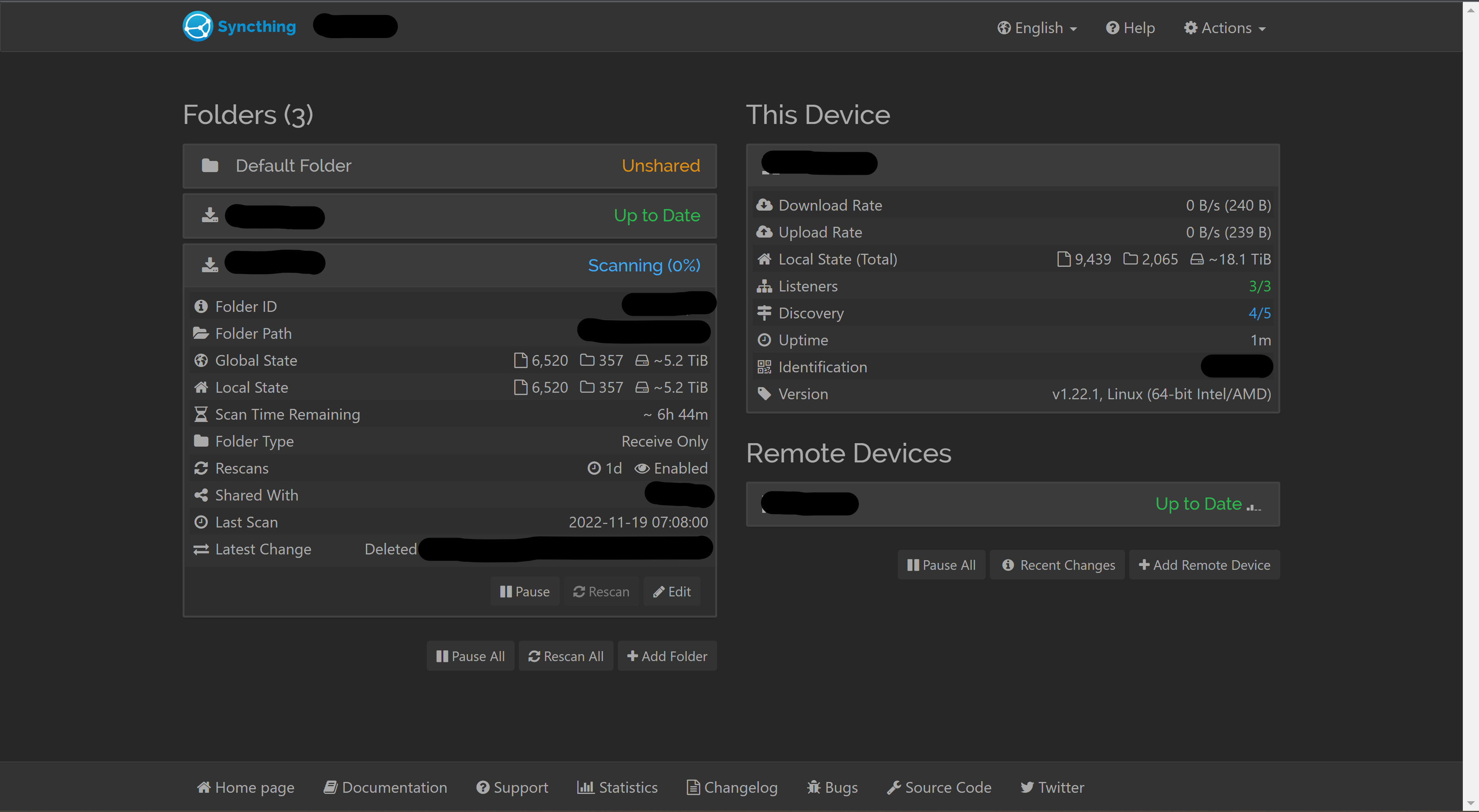
Both servers are NAS arrays running Syncthing as a docker container, v1.22.1, Linux (64-bit Intel/AMD). The receiving server is an Intel Core i3-6300, 8GB RAM. Both folders are located on the same XFS file system storage array with similar content, mostly larger files in the GBs. Here’s a screenshot of the web GUI shortly after restarting the docker container. As you can see, the first folder has already determined that it is up to date, while the second folder has begun a long scan, seemingly rehashing its entire contents, utilizing 60-100% CPU for the 6.5 hour duration.
Try using fswatch to monitor the path for the folder that’s triggering the long scan (it’s available in the default repositories for Ubuntu, Fedora, RHEL/CentOS 8, and many others).
The following command monitors and lists every filesystem event that occurs for the specified directory:
fswatch --timestamp --recursive --event-flags /tmp
Sample output:
Sat 19 Nov 2022 10:34:17 PM /tmp/test.txt Created
Sat 19 Nov 2022 10:34:17 PM /tmp/test.txt PlatformSpecific
Sat 19 Nov 2022 10:34:17 PM /tmp/test.txt AttributeModified
Sat 19 Nov 2022 10:34:17 PM /tmp/test.txt Updated
Sat 19 Nov 2022 10:34:24 PM /tmp IsDir
Sat 19 Nov 2022 10:34:24 PM /tmp PlatformSpecific
Sat 19 Nov 2022 10:34:28 PM /tmp/test.txt Removed
In the sample output above, I issued the command touch test.txt. The file didn’t exist yet, so there was a Created event flag; AttributeModified was when the file metadata was updated; IsDir is when the directory was accessed; and Removed was when I did a rm test.txt.
Syncthing’s filesystem watcher, when enabled, schedules a scan whenever it receives a change event from the OS (on Linux it’s usually the kernel’s inotify subsystem).
Unfortunately the Linux OS is a lightweight Slackware-based distro, which doesn’t include fswatch and would require building from source to install. The system also isn’t configured with a compiler or build tools.
Ah… Slackware… the first Linux distro I used when I got tired of Windows. ![]()
One option would be to install a matching Slackware version in a virtual machine using VirtualBox in order to build the binary. SlackBuilds has a build script for fswatch: http://slackbuilds.org/repository/15.0/system/fswatch/
Alien Bob has select binaries built using SlackBuilds, but unfortunately fswatch isn’t included in his repo: https://slackware.nl/
inotify-tools is included in Slackware’s repo under the “a” directory (assuming you don’t have a really, really old version): https://mirrors.slackware.com/slackware/slackware-15.0/slackware/a/inotify-tools-3.20.11.0-i586-3.txt
inotify-tools isn’t nearly as handy as fswatch, but when there’s nothing but a screwdriver, it also doubles as the pry bar. ![]()
The following command will watch the target directory and all of its subdirectories for 10 seconds, then output a report to the terminal:
inotifywatch -v -e attrib -e create -e delete -e modify -t 10 -r /path/to/folder
To filter out the noise, only attribute / create / delete / modify events are collected by the command above.
With 6,520 files and 357 directories, you won’t need to adjust the kernel settings (the default is 8,192 watches per user).
This is not about watching: A full scan anyway happens on startup. What’s peculiar here is the rehashing, i.e. Syncthing believes that all files have changed based on metadata. Given this happens on one folder but not the other, I’d start by trying to identify any differences between the two (different filesystems, any other programs accessing files in those directory trees, …).
inotifywatch -v -e attrib -e create -e delete -e modify -t 10 -r /path/to/folder
Thanks, I ran the command, even increased monitoring time to 120 seconds and no events occurred. (It only needed 359 watches, so must be able to utilize a single watch per folder.)
Establishing watches...
Setting up watch(es) on /path/to/folder
OK, /path/to/folder is now being watched.
Total of 359 watches.
Finished establishing watches, now collecting statistics.
Will listen for events for 120 seconds.
No events occurred.
What’s peculiar here is the rehashing, i.e. Syncthing believes that all files have changed based on metadata. Given this happens on one folder but not the other, I’d start by trying to identify any differences between the two (different filesystems, any other programs accessing files in those directory trees, …).
This is the odd thing as both folders are pretty similar. As mentioned above, they’re located on the same XFS file system. They’re used by the same programs and contain similar content.
Is there some way to determine (from logs, etc.) what Syncthing is finding to be different with the file metadata that causes it to perform a full rehash for the entire folder tree?
Enabling scanner debug logging will show that.
With scanner debug logging enabled, the problematic “folder 2” logs three statements for each file, all similar to this example (with new lines added for legibility):
[F3MWP] 2022/11/21 11:58:14.046240 walk.go:402: DEBUG: walker/folder2-id@0xabcdef3210 checking: File{
Name:"path/to/file",
Sequence:0,
Permissions:0664,
ModTime:2022-06-24 14:28:34 -0600 MDT,
Version:{[{FYG6N7V 1668391356} {F3MWPHB 1669057094}]},
VersionHash:,
Length:3854713788,
Deleted:false,
Invalid:false,
LocalFlags:0x8,
NoPermissions:false,
BlockSize:2097152,
NumBlocks:0,
BlocksHash:,
Platform:{<nil> <nil> <nil> <nil> <nil> <nil>},
InodeChangeTime:2022-11-15 15:36:27.948634661 -0700 MST
}
[F3MWP] 2022/11/21 11:58:14.046262 walk.go:424: DEBUG: walker/folder2-id@0xabcdef3210 rescan: File{
Name:"path/to/file",
Sequence:8253,
Permissions:0664,
ModTime:2022-06-24 14:28:34 -0600 MDT,
Version:{[{FYG6N7V 1668391356}]},
VersionHash:,
Length:3854713788,
Deleted:false,
Invalid:false,
LocalFlags:0x0,
NoPermissions:false,
BlockSize:2097152,
NumBlocks:1839,
BlocksHash:49b3b6bfb544f23217cf0f7b278e297fd2995349ef7e358432b466bb83b80907,
Platform:{<nil> <nil> <nil> <nil> <nil> <nil>},
InodeChangeTime:2022-11-15 01:32:07.259712036 -0700 MST
}
[F3MWP] 2022/11/21 11:58:14.046281 walk.go:427: DEBUG: walker/folder2-id@0xabcdef3210 to hash: path/to/file File{
Name:"path/to/file",
Sequence:0,
Permissions:0664,
ModTime:2022-06-24 14:28:34 -0600 MDT,
Version:{[{FYG6N7V 1668391356} {F3MWPHB 1669057094}]},
VersionHash:,
Length:3854713788,
Deleted:false,
Invalid:false,
LocalFlags:0x8,
NoPermissions:false,
BlockSize:2097152,
NumBlocks:0,
BlocksHash:,
Platform:{<nil> <nil> <nil> <nil> <nil> <nil>},
InodeChangeTime:2022-11-15 15:36:27.948634661 -0700 MST
}
In comparison, “folder 1” logs two statements per file, similar to this example:
[F3MWP] 2022/11/21 12:31:41.166385 walk.go:402: DEBUG: walker/folder1-id@0xabcdef3450 checking: File{
Name:"path/to/file",
Sequence:0,
Permissions:0777,
ModTime:2021-08-10 03:00:06 -0600 MDT,
Version:{[{FYG6N7V 1668391238} {F3MWPHB 1669059101}]},
VersionHash:,
Length:5558564654,
Deleted:false,
Invalid:false,
LocalFlags:0x8,
NoPermissions:false,
BlockSize:4194304,
NumBlocks:0,
BlocksHash:,
Platform:{<nil> <nil> <nil> <nil> <nil> <nil>},
InodeChangeTime:2022-11-15 15:36:12.96143399 -0700 MST
}
[F3MWP] 2022/11/21 12:31:41.166410 walk.go:413: DEBUG: walker/folder1-id@0xabcdef3450 unchanged: File{
Name:"path/to/file",
Sequence:7453,
Permissions:0777,
ModTime:2021-08-10 03:00:06 -0600 MDT,
Version:{[{FYG6N7V 1668391238}]},
VersionHash:,
Length:5558564654,
Deleted:false,
Invalid:false,
LocalFlags:0x0,
NoPermissions:false,
BlockSize:4194304,
NumBlocks:1326,
BlocksHash:b42e82be600bed8cfaadf333e062c77b7d4d6725f41909d988ea08acb7e61072,
Platform:{<nil> <nil> <nil> <nil> <nil> <nil>},
InodeChangeTime:1969-12-31 17:00:00 -0700 MST
}
In both cases, the ModTime, Length, and Permissions are unchanged. The only meaningful difference I can see between the two is that the InodeChangeTime is a 0 timestamp (1969-12-31 17:00:00 -0700 MST) for folder 1 (working), while it is a time ~14 hours before the file system value for folder 2 (which detects a rehash). I don’t know what InodeChangeTime is, but both are still less than the file system value. Can you glean what the cause could be from these logs?
Inode change time will trigger a rescan, in 1.22.1. In 1.22.2(-rc) this doesn’t happen unless syncing extended attributes is enabled. The inode change time implies something touched something about the file – maybe extended attributes.
Ok, interesting. Why is “folder 1” InodeChangeTime a 0 timestamp (1969-12-31 17:00:00 -0700 MST), while the file system value is 2022-11-15 15:36:12.96143399 -0700 MST? And this doesn’t trigger a rescan?
Also, the last full scan of “folder 2” was completed since 11-15 (11-19 or 11-20). So it is odd that the file system value is 2022-11-15 15:36:27.948634661 -0700 MST and the database value is ~14 hours earlier 2022-11-15 01:32:07.259712036 -0700 MST.
Is there some way I can get “folder 2” in the same state as “folder 1” with 0 timestamp values for InodeChangeTime in the database? I’m not syncing extended attributes. So it seems 1.22.2 should fix this then?
It’s interesting that inotifywatch didn’t report any events (the -e attrib parameter includes changes to extended attributes).
Which version of the Linux kernel is the Slackware-based server running?
Not that it’s necessarily related, but a big difference between ext4 and XFS is that XFS doesn’t have a fixed inode table, i.e. you don’t commit to how many inodes are allowed at the time a filesystem is formatted. XFS uses a bunch of mini tables to hold metadata and the number of tables can be adjusted without reformatting (more tables = less space for files, but a larger number of files allowed).
Because the filesystem is multi-terabyte in size and no file changes are expected during system restarts, I’d run a full system scan to rule out issues at the storage layer.
At my employer, one of the NAS units has a 13TB RAID10 XFS volume with >26 million files and counting. During a regular review I found some damaged files. Filesystem corruption can easily go unnoticed with large volumes.
At home, a couple months ago I noticed some file corruption on my NAS. The affected read-only files were originally written correctly but several blocks no longer matched their hashes (Btrfs logs the hash of every block it writes). Turned out that one of the HDDs was experiencing bad sectors and having trouble with reallocation – I was basically dealing with “bit rot”.
It’s Slackware 15, Linux kernel 5.19.17. I ran xfs_repair on each of the disks in the array and didn’t see any errors.
After letting a full rescan/rehash complete on “folder 2” again, restarting Syncthing and checking the scanner debug logs, it’s showing the same dates for InodeChangeTime, both 11-15, file system ~14 hours ahead of the database. So it seems despite the date not having changed since then, the rescan isn’t actually saving the updated date in the Syncthing database.
Cool. A fairly recent kernel.
It’s great that there weren’t any filesystem errors, but tools like xfs_repair and fsck only verify the consistency of a filesystem and not its contents.
If a timestamp in an inode is changed by flaky media (e.g., changing a “5” into a “50”) or several blocks of an image or video file are corrupted, the filesystem can still be considered consistent, so Btrfs and ZFS checksum both metadata and data.
I think this is one of the bugs fixed fairly recently. Try the 1.22.2 rc.