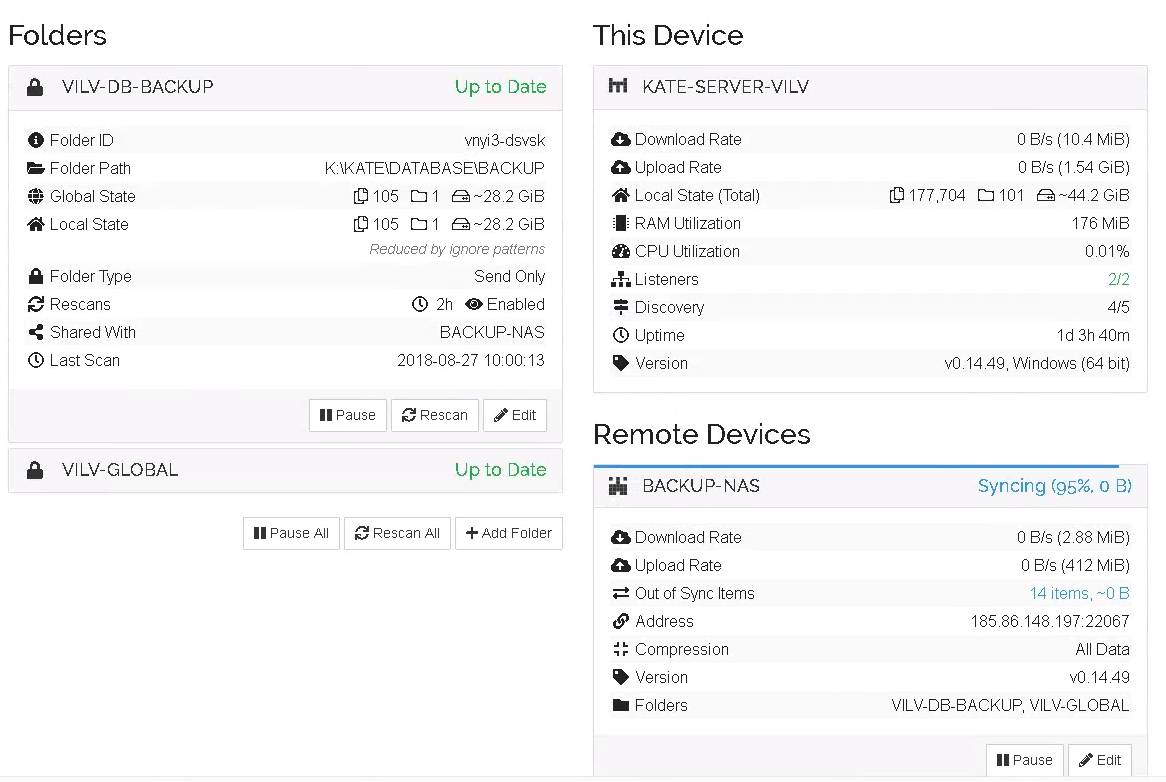
When i look at the filelist, it’s clear that those are files which were deleted on the host.
Checking the remote device, the files are indeed still present instead of having been moved into the versioning folder.
Also, the remote device claims that everything is good and Up to Date :
Interesting, I also have one machine stuck like that: 6 items and also at 95% with 0 Bytes - coincidence?
I noticed that in modal “out of sync items” there a 3 items with “0 B” and 3 items with “” (empty string) as size. Modification times are more than one month ago. Also there is an empty .stignore (created July 25th) on receiving side although no ignores are used. Source is set to send only (possible cause in combination with empty .stignore?) Everything else (add, delete, modify) works fine for other files.
I also have these 0 Byte files in my Syncthing instances.
I believe that these files are created (0 Byte), Syncthing pics them up, then the files are filled with data and deleted again before Syncthing can finish the scan of the file.
I was never able to reliably test it, so I didn’t create a bug report…
I am also interested if that happens. In my fully scripted system I had occurrences of devices being stuck at 95%, but i could not detect exactly which files and what the reason was.
Update from source side:
The folder is “send only” and does not use ignores or file watcher. The files are still there (not deleted) and have more than 0 bytes (all below 100 KB).
Yes, I am using a sendonly folder as well. I cannot tell more about the files, because the sync happens over night and is automatically unshared afterwards.
in my case, it is also a send-only origin.
But the actual issue is that on the original host the files are deleted, and the deletion never propagates to other side of sync.
@calmh: the overnight logging is huge, 300megs, how can i get that to you guys ?
This is a repeating msg regarding one of the files that never gets deleted.
Well, in this case the file is supposed to be moved to .stversions by Staggered Versioning.
That’s an entirely normal thing to be happening. Almost all debug level things are; they just bring developer context to any errors, where the errors should be visible anyhow.
Sure. To find out why that didn’t happen you need to look for errors on JKZ4TOI. The above log line just says that they haven’t sent an update about handling the file, which you already knew.
Look, I’m trying to convey that reading random debug output like tea leaves isn’t useful. The information is dense and hard to interpret.
Assuming there are no errors anywhere JKZ4TOI, that is where you might want to enable model tracing. Or, use the /rest/db/file endpoint to look at what it knows about a file that should be deleted but isn’t. In fact, I’d start there. Lets see what it thinks about one of those things that are not deleted. The config for JKZ4TOI would also be good.