I acknowledge a great job.
It’s working! My nodes online finally! Thank you very much!
A post was split to a new topic: Setting up custom discovery server
How to use this link ? where the setting fir discovery server ?
@calmh How about adding that discovery server into Syncthing by default, if it helps people?
In settings, replace default word with the link.
It’s a server hosted in the US somewhere. If our goal is to assist users in Russia, and this works for the moment while our regular servers in Paris and Amsterdam don’t, this seems a bit random. It’s also a bit of a commitment to take on if we suddenly point ~150k devices at @schnappi’s server, both in terms of resources required there and privacy of our users.
3 Likes
A few things to note. As to where. The discovery server is running in my American office on a 100Mbit symmetrical connection.
As to resources. It runs on a 20 something year old Pentium 2 with Debian. It runs great. Unlike the relay server the discovery server utilizes next to no CPU usage (even with a slight user base now, base this inference on increasing size of the discovery.db). Discovery server also does not utilize many established connections. Established connections are a limitation as only pay for ripoff dedicated 1k fiber, with no connection limitations, in my largest office.
If scales to point where starts using CPU or connections will move to a modern machine or a datacenter; which would be invisible to users since either way would just involve a DNS change. Worst case some people would get errors for 24 hours, but do not see a switch being necessary at this point. Can probably scale a good deal before need to do anything.
As to privacy. While prefer to make money than create a network map for the FSB this is a good point. Whether one utilizes this discovery server or the default ones (or even one you run in a datacenter yourself) an adversary can correlate machines to users with something as simple as iftop. Actually I advocate for my discovery server from a privacy perspective because it is not in a datacenter, which means the only risk is a bad operator (and internet level surveillance). A datacenter discovery server opens privacy risk to the datacenter owner in addition to the server operator (and mass monitoring).
There is no tracking, no Google Anayltics/Motomo, no iftop, the Nginx access and error logs (when put up small webpage briefly saying this) and the discovery server log is sent to /dev/null.
All this being said anyone using an discovery server really doesn’t have much to worry about. Solely correlating machines carries limited risk and can probably be done other/easier ways. Bottom line if using discovery servers, anywhere, just be aware of the risks and decide if the convenience outweighs manually mapping devices.
If demand continues and resource usage scales without issue will run alternative community discovery service properly on the dot com version of the domain. If going to even discuss adding anything officially as an alternative by choice the dot com would be significantly better for many reasons. Syncthing is a great project. Adding anything to do with dot tk officially would just look bad and is below Syncthing.
1 Like
It’s more resource intensive than you’d think. That aside though, I’m personally not enthusiastic about adding discovery servers to the default set as it’s more things to monitor and manage, especially with unclear ownership. The Russian issue is a thing, but it’s a thing that can be handled by affected users taking action.
Agreed. Keep keeping things simple. Users can add if want.
However why didn’t Syncthing go with community discovery servers like the relay servers? Assuming/ think community relay servers were an additional feature to the original relay setup. Is this easy/ feasible for discovery servers or is the idea not desirable?
There are privacy aspects (discovery operator can track and map users), availability aspects (if it goes down, Syncthing goes down), coordination aspects (you must ask the same server someone announced themselves to, or they must cluster and trust), and other things. It’s not clear to me how it would work as a community run thing.
Of course there is still the option of using a DHT for discovery. Not sure how much effort that is, but it might be worth it to fight censorship.
Community relays can also be used to correlate users (to a lesser extent) so would not see community discovery servers as a further privacy risk. Using a community pool of discovery servers could increase privacy since centralized server(s) could not be targeted.
But if community discovery isn’t as feasible as community relay servers its understandable.
The discovery system you’re living with now is the best I can design. I haven’t been able to find a DHT option that would work, and I don’t understand how to build it as a decentralized community thing. If you know how to do that you are more than welcome to do it or propose how in enough detail so that someone else can.
For a DHT that means saying “use this implementation I found that fulfills the requirements”, not “build a new one according to these specs” - unless you have the time, inclination and skill to actually do the latter.
Suggesting a DHT or pool of community run servers is not helpful in the meantime, because I don’t see what that solution would actually look like, technically.
The relay system is actually no more decentralized than the discovery system. The individual relays can be run by anyone, much like Syncthing devices can be run by anyone. But they register with a central service (relays.syncthing.net) and this is how devices find them.
2 Likes
What we could do though is add a third discovery server at a different provider, and wire it into the current cluster.
I’ve added a discovery-3.syncthing.net in Bangalore on DigitalOcean. This should be sufficiently different from our current Paris/Amsterdam Scaleway machines for blocking to not hit both accidentally, I hope. It also gives some closer coverage for Asia which is good.
It’s currently warming up (replicating from the others) so not serving requests yet.
In the meantime, if someone in Russia can prove/disprove the blocking status for the servers that would be cool:
- discovery-1: 51.15.215.88, 2001:bc8:4400:2200::c39
- discovery-2: 51.15.92.95, 2001:bc8:4700:2000::515
- discovery-3: 139.59.85.170, 2400:6180:100:d0::757:7001
4 Likes
Indian server is up and serving requests.
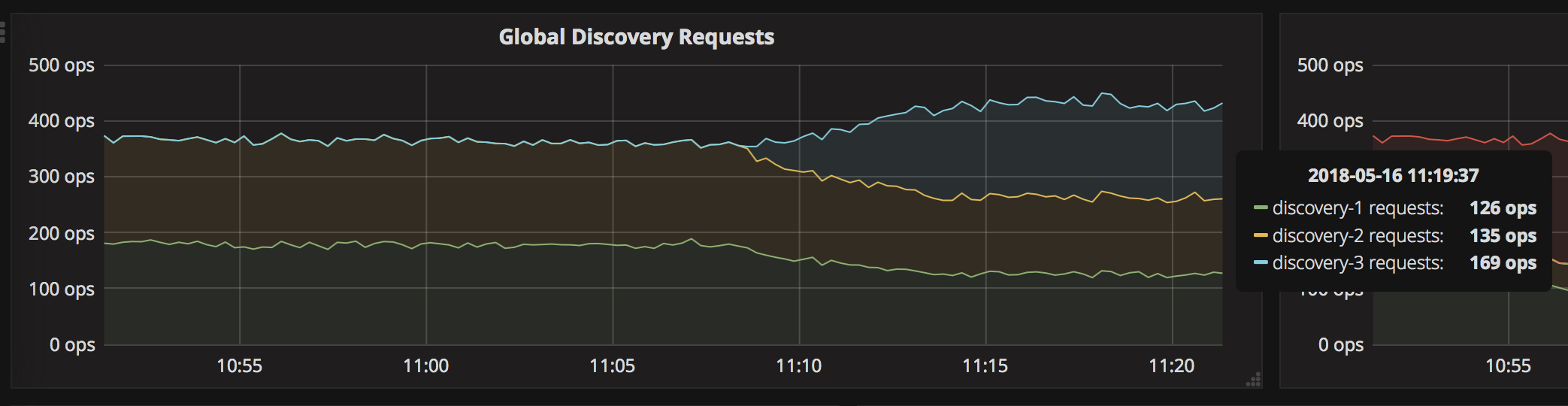
(The increase in total traffic is expected and related to how failed lookups are retried with longer and longer intervals.)
3 Likes
Appreciate the bluntness. Would be frustrating constantly responding to ideas that are not thought out.
After thinking idea through agree community discovery servers will never work.
Community relay servers work because a discovery server maps which relays should be used if necessary.
Even if a pool of trusted connected community discovery servers existed how would one node know which discovery server another was using (obviously another “discovery” server to locate a discovery server makes no sense).
Of course community discovery servers could use replication (functionality already exists) across the pool. While this might solve the blocked IP issue for some it creates a bigger problem, anyone who runs a discovery server gets the entire discovery.db with all device mappings (assuming that “announcements are replicated from the server that receives them to other peer servers” basically means that the discovery.db is replicated.) Community relay servers only see a small subset of devices “assigned” to them, huge difference than seeing the entire discovery database.
Assuming understand replication correctly this obviously isn’t an option and is only way that could see community discovery servers working.
1 Like
I have tested…
discovery-1: doesn’t work
discovery-2: doesn’t work
discovery-3: works normally
Synchronization works fine by default settings since discovery-3 has been added.
2 Likes
139.59.85.170 - timeout 51.15.92.95 - timeout 139.59.85.170 - ok.
1 Like
Will keep alternative discovery server online complimentary to defaults for any who wish to utilize until further notice.
For information: http://discosrv.tk
To use: https://discosrv.tk:8443/?id=554GCWZ-7TSUAIF-UEZPIWY-6AVBFKD-D77HEDC-6MT2QMO-KC542YI-EKUX2AC