My storage is pretty big (~600 000 files, > 200 GiB).
To avoid high workload on NAS side, all directories on NAS side have zero rescan interval. Means scanned on startup only. But that’s not a problem, as normally I do changes on other computers.
Start of Syncthing on NAS is really slow - it automatically scans the storage. It takes time. Anyway, that’s understandable and not a big problem.
The main problem is when it tries to syncronise with desktop - the CPU load is 99% and it takes ages to syncronyse. (Takes hours/days to syncronise what can be directly copied during few minutes)
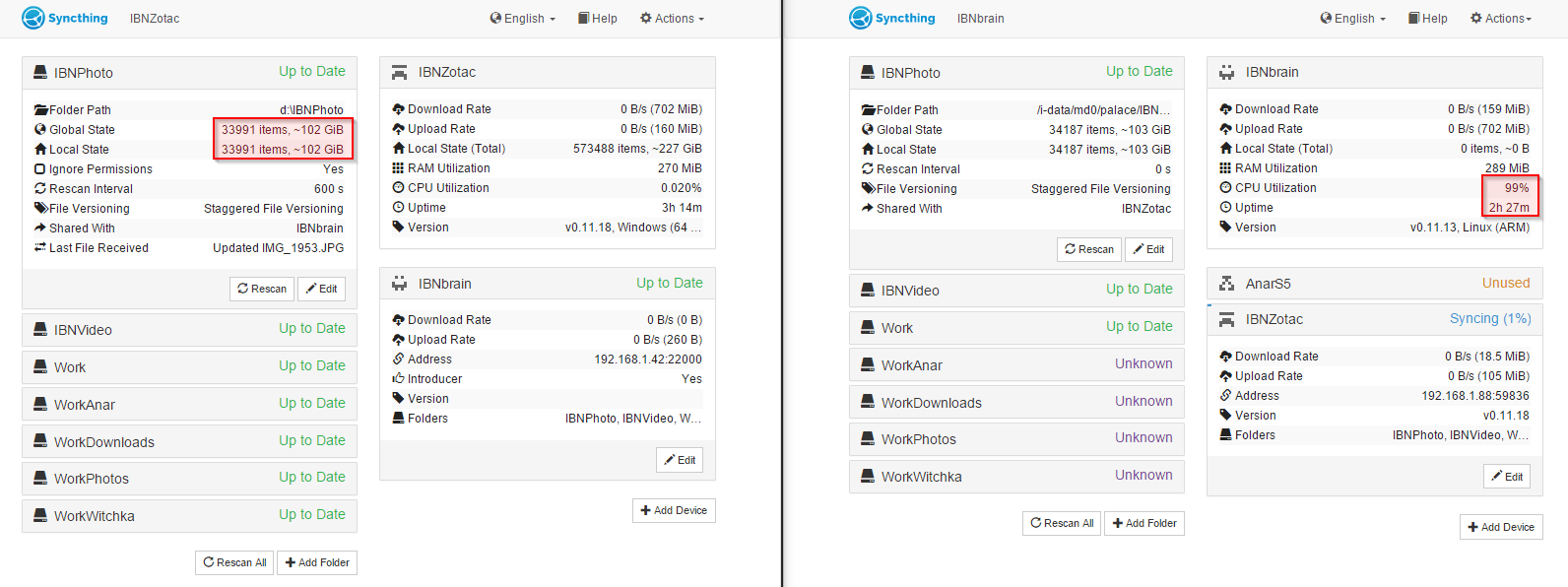
(here is performant intel i7 computer on the left side, and ARM NAS is on the right side)
As you can see, after restart NAS already scanned all directories, and there are ~200 new files in the IBNPhoto directory (total size of new files is ~1GiB).
The intel i7 machine still has old version of the IBNPhoto directory. But NAS has CPU load 99% during last 2.5 hours and transferred only few bits of data. (in fact screenshot was taken more than hour ago, but nothing has changed since then).
Also intel machine shows NAS status as ‘disconnected’ from time to time.
Could anybody advice me if it’s possible to make some advanced tuning of the Syncthing at NAS? (like modify ‘pullers’ value for folders, or adjust some other advanced options)
So its most likely due to hashing, but check -help, run a CPU profile, then post it here + full long version that you are running, so someone could have a look at it.
whoops, as new user I can’t upload files. Here is external link:
Here is what was happening:
updated ARM version from 0.11.13 to the latest 0.11.18
stop all Syncthing instances
start ARM instance only (with STCPUPROFILE=yes)
30 minutes of ARM uptime: all directories got status “Up to Date” and CPU Utilization changed down from 94% to 0.1%
45 minutes of ARM uptime: start intel instance (v0.11.18, Windows 64 bit). In 1 minute all Windows directories are “Up to Date”, and ARM instance changes status to “Syncing” and its CPU Utilization goes up to 99%
55 minutes of ARM uptime: only few ~5 files are transfered (on disk ~20MB). On WebUI I see totaly tranfered ~120MiB
65 minutes of ARM uptime: after 20 minutes of syncronization, totaly ~20 files are tranfered. WebUI says ~220MiB were tranfered (up+down)
(both machines are in local network)
whooops. STCPUPROFILE variable wasn’t exported
final profile log was collected once again with similar sequence (with step 5 executed after several hours of IDLE). After IDLE, on ARM instance RAM utilization was 57Mb, after I satart second instance, it grow up to ~200Mb (with CPU usage to 100%).
Shall I do some more profilings (like STPERFSTATS)?
If necessary, I also can collect profiling with much more sync activities (in the log I’ve posted - there were only 20 minutes of sync, while startup scan was > 30 minutes).
Also I can remove whole 100Gb directory from i7 instance, and then let sync it from ARM instance. AFAIR it takes more than 24h to sync such amount of data.
Something is going really slowly on that box, and it seems not to be coping. The “cannot allocate memory” panic is fairly straight forward - it’s out of memory. “fatal error: fault” is a mystery to me… The deadlock seems to be because a database scan (requested by the GUI, at the same time it’s doing initial scans) is taking long enough to trigger the deadlock detector…
I think the issue is solely that the device is slow and Syncthing (actually, Go) isn’t very well optimized for ARM. Leave it be, and don’t open the GUI, and it should complete the scan and be happy at some point.
I had similar problems with a very old ARM-based NAS. I changed the pingTimeoutS to 300 and the pingIdleTimeS to 600, based on a tip here on the forum. It seems that if a ping do not get answered, a reconnection and a rescan is initiated, which takes a lot of cpu.
With the above changes it works well for me, even with a slow device.