Nothing seemed to fix the issue. I even went as far as stopping syncthing, blowing away the entire config directory and set things back up from scratch.
At the end, various devices would show files out of sync and waiting for some unknown node to come back online to finish syncing. No data was being transferred. I had one instance (apparently unrelated to the original issue) that was refusing to talk with all but one other instance.
The last time I remember it working correctly was right before the config was bumped up to version 31…so I looked in the Debian package history and saw the recent upgrade was from 1.7.0 to 1.8.0.
I stopped syncthing, downgraded every machine to 1.7.0, noticed the config version was still 31, but said “meh” and let things run. Everything is back in sync.
I’m going to pin my boxes to 1.7.0 for the moment…but I think there’s some sort of problem between 1.7.0 and 1.8.0. I just haven’t been able to track it down.
I spoke too soon. The issue occurs with 1.7.0 and 1.8.0.
I left the config file alone, stopped syncthing, rm -rf’d the index-v0.14.0.db folder, and started up syncthing 1.7.0. It always ends with multiple folders being out of sync and pointing to changes non-existent machines.
After that didn’t work, I stopped syncthing, rm -rf’d the index again, then upgraded to 1.8.0 and started it. After a few days a bunch of folders were out of sync again.
If you deleted the indexes where are the unknown devices coming from.
Deleting the index on one machine doesn’t do much, as it just gets the index from a different machine, with the same needed files from devices that are no longer there.
There was also a bug that could lead to missing indexes which was fixed in v1.9.0-rc.5. If you ever made config changes or pause/unpaused a folder while it was scanning, you might be affected by that.
My mistake. I conflated one of my earlier tests where I deleted the config and database and then re-created it and “forgot” one box.
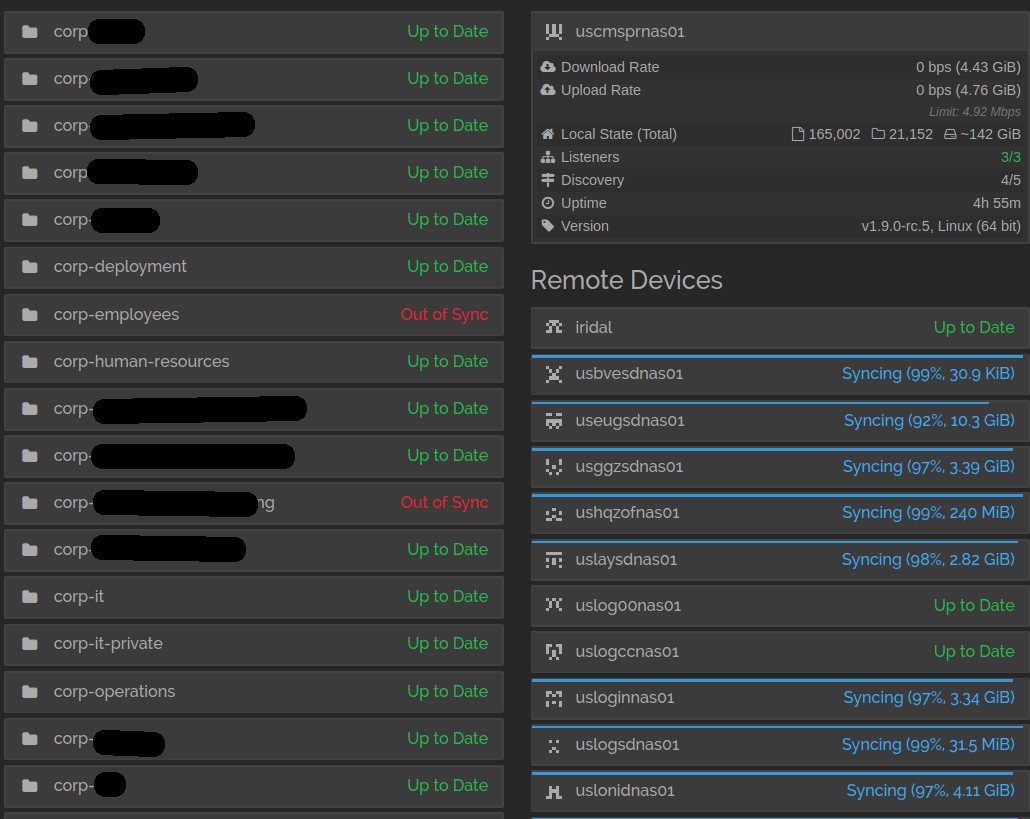
I just went through and hand-checked all 24 boxes. They are no longer showing a mystery device changing files. They are showing one device (based on spot checking every devices “remote devices” section and looking at several pages of out-of-sync files). All the devices point to ‘uslogsdnas01’. Even uslogsdnas01 shows it has a backlog of changes from all the other devices where files were modified by itself.
Deleting the index on one machine doesn’t do much, as it just gets the index from a different machine, with the same needed files from devices that are no longer there.
In my recent test, all instances of syncthing were stopped, then the index on each box was deleted, and then syncthing was restarted. Wouldn’t that be enough to cause each machine to re-index?
There was also a bug that could lead to missing indexes which was fixed in v1.9.0-rc.5. If you ever made config changes or pause/unpaused a folder while it was scanning, you might be affected by that.
That’s definitely a possibility. I’ll see if I can track down a 1.9.0-rc.5 package, delete all the indexes and let it resync.
Ok–I just pushed out an updated sources.list with the syncthing candidate repo. I’ll upgrade all the boxes in the next few minutes and let it work its magic over the next ~6 hours and I’ll let you know.
If that’s the case, I forgot to mention that during one of my resync tests a handful of the machines spit out “Non-increasing sequence detected: Checking and repairing the db…” several times during syncing. I assumed it was related to something else I hosed up during one of my test syncs. After that I stopped syncthing, deleted the databases, and started it again and didn’t see the errors return.
While I’m still only about 20% of the way through the re-sync, it does appear to be working. None of the folders are showing “out of sync” for more than a few seconds while it downloads some data and then it changes back to “syncing” a few seconds later.
All devices are uploading/downloading 0 bps.
The “local state” on all boxes shows right around 165,002 files plus or minus less than 8 files. Some boxes show that every folder is up-to-date, but the remote devices section shows anywhere from a few KB to tens of GB that still need to be synced out.
Some of the devices have one or two folders that are out of sync.
The folders that are out of sync show they have one or two files that need to sync and the total size is always 0 bytes. Clicking the link to see which files still need to sync gives a blank list.
In the “Remote Devices” section, every instance shows that it needs to sync data to partner instances. Clicking on the link to see the files that need to sync shows a lot of files throughout a handful of folders. But every instance shows that the “changed device” was USLOGSDNAS01. Even USLOGSDNAS01.
I’m guessing my next step should be to set STRECHECKDBEVERY=1s and restart Syncthing to see if that cleans it up. Thoughts?
Yes, that’s the issue I meant. It’s a bummer that your problem still occurs on v1.9.0-rc.5. Do you still get any non-increasing sequence lines in the log? Please mention anything else in the logs or about the displayed files that stands out or may be relevant. And if you could again provide the /rest/db/file output for one of the files that is shown in the out-of-sync list on a remote device, queried on both involved devices (e.g. in your latest screenshot on uscmsprnas01 and e.g. usbvesdnas01).
You can try that, it should at least clean up the out-of-sync folders with nothing in the actual list.
Just grepped through syslog on all the boxes. I haven’t seen that since the 30th when I was still running 1.8.0.
I’m not seeing anything that jumps out over the last 24 hours. I did restart syncthing on one box to see if that would “unstick” it from sending/receiving nothing. It did generate a panic on shutdown:
Sep 1 17:40:07 uslogsdnas01 syncthing[22541]: [monitor] INFO: Signal 15 received; exiting
Sep 1 17:40:07 uslogsdnas01 syncthing[22541]: [ACQW3] INFO: QUIC listener ([::]:22000) shutting down
Sep 1 17:40:07 uslogsdnas01 syncthing[22541]: [ACQW3] INFO: Relay listener (dynamic+https://relays.syncthing.net/endpoint) shutting down
Sep 1 17:40:07 uslogsdnas01 syncthing[22541]: [ACQW3] INFO: TCP listener ([::]:22000) shutting down
Sep 1 17:40:14 uslogsdnas01 syncthing[22541]: panic: runtime error: invalid memory address or nil pointer dereference
Sep 1 17:40:14 uslogsdnas01 syncthing[22541]: [monitor] WARNING: Panic detected, writing to "/tank/syncthing/panic-20200901-174014.log"
Sep 1 17:40:14 uslogsdnas01 syncthing[22541]: [monitor] WARNING: Please check for existing issues with similar panic message at https://github.com/syncthing/syncthing/issues/
Sep 1 17:40:14 uslogsdnas01 syncthing[22541]: [monitor] WARNING: If no issue with similar panic message exists, please create a new issue with the panic log attached
Sep 1 17:40:14 uslogsdnas01 syncthing[22541]: [monitor] INFO: Reporting crash found in panic-20200901-174014.log (report ID 80985e81) ...
Sep 1 17:40:15 uslogsdnas01 systemd[1]: syncthing@root.service: Main process exited, code=exited, status=2/INVALIDARGUMENT
Sep 1 17:40:15 uslogsdnas01 systemd[1]: syncthing@root.service: Failed with result 'exit-code'.
These appear to be normal messages for processing through files. I have stuff like this in my logs from well before this issue popped up:
Sep 1 05:31:34 uslogsdnas01 syncthing[10286]: [ACQW3] INFO: Puller (folder "corp-accounting-private" (redac-ted), item "Workpaper Account Analysis/CY 2020/(08) Accounts Payable and Accrued Expenses/Credit Cards/(08) August/Activity Downloads/--redacted-- 08.01.20-08.29.20.sync-conflict-20200901-053134-VMGX7M2.xlsx"): file modified but not rescanned; will try again later
Sep 1 05:31:34 uslogsdnas01 syncthing[10286]: [ACQW3] INFO: "corp-accounting-private" (redac-ted): Failed to sync 1 items
Sep 1 05:31:34 uslogsdnas01 syncthing[10286]: [ACQW3] INFO: Folder "corp-accounting-private" (redac-tede) isn't making sync progress - retrying in 1m0s.
Sep 1 05:31:34 uslogsdnas01 syncthing[10286]: [ACQW3] INFO: "corp-accounting-private" (redac-ted): Failed to sync 1 items
Sep 1 05:31:34 uslogsdnas01 syncthing[10286]: [ACQW3] INFO: Folder "corp-accounting-private" (redac-ted) isn't making sync progress - retrying in 1m0s.
Sep 1 10:12:54 uslogsdnas01 syncthing[10074]: [ACQW3] INFO: Puller (folder "corp-employees" (redac-ted), item "ACTIVE/--redacted-name--/Personnel/Status Change Request.pdf --redacted-name-- 9.1.20.pdf"): syncing: pull: no such file
Sep 1 10:12:54 uslogsdnas01 syncthing[10074]: [ACQW3] INFO: "corp-employees" (redac-ted): Failed to sync 1 items
Sep 1 10:12:54 uslogsdnas01 syncthing[10074]: [ACQW3] INFO: Folder "corp-employees" (redac-ted) isn't making sync progress - retrying in 1m16s.
I’ll grab it as soon as I can. It’s starting to feel like a Monday today…
That panic/nil deref does jump out at me Not that it has to be connected, but it definitely shouldn’t happen. Could you please post the trace part of the mentioned /tank/syncthing/panic-20200901-174014.log
That’s an unclean shutdown because services didn’t terminate fast enough. That “shouldn’t” create db inconsistencies, but if this is the only lead we have then we might have to think about whether that’s actually the case. I’d still be interested in the particular panic from above, as it’s not a db closed panic but a nil deref.
Thanks. Same thing (services didn’t terminate on shutdown before db was closed), just different effect.
After those panics, did you ever see a line like Stored folder metadata for ... is out of date after crash; recalculating and/or Repaired ... sequence entries in database?
To not have too many moving parts: Can you run with STRECHECKDBEVERY=1s on only one device that had such a panic and is shown as syncing on any other device. Does the line Repaired ... sequence entries in database appear then? And is it then shown as up-to-date on other devices?
If the answers to the latter two turn out to be yes, it very much points at unclean shutdowns being problematic. Which is bad, because we take great care to do atomic db operations, such that even on a crash the db should stay consistent. Meaning we messed up or the db implementation is messed up.
 Not that it has to be connected, but it definitely shouldn’t happen. Could you please post the trace part of the mentioned
Not that it has to be connected, but it definitely shouldn’t happen. Could you please post the trace part of the mentioned