Just to help anyone who may want to deploy relay server on a hosting platform
I was able to resolve it by ensuring that the -listen parameter in the syncthing relay was set to the same port number which my deployment platform was exposing.
For e.g. if port exposed in your container is gonna be assigned a url:port by the hosting platform to be externally reachable(in my case when i want to expose port xx of my container, it was reachable at tcp.ey.devfactory.com:10126) , i set -listen option to 10126.
Due to this the syncthing peers started dialing correctly at ip:10126 instead of ip:22067
i believe deploying relay server on a general purpose cloud hosting platform is acceptable for testing/experimenting but perhaps it would be better to run relay servers on high network performance instances on say AWS. (can anyone comment which aws instance type would be recommended for running relay server, m5.large maybe? )
We barely have 1Gbit rate across all relays, so I don’t think having much bandwidth is a prerequisite as either everyone runs on low bandwidth, or the implementation is slow, or people don’t need that much bandwidth as we never fill the pipe. I think most relays are sub 10Mbit, which is probably what sdsl would give you. There is no encryption so it should not use much cpu. I think we have 4Mb buffer per client, so for an average of 1000 active sessions you’d need 4gb of ram, which is still in theory rpi territory.
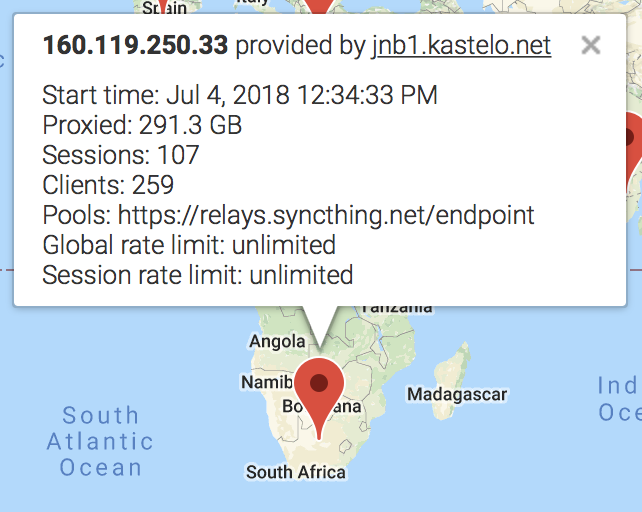
So I set one up in Johannesburg, there was a distinct lack of relays on the African continent and there are at least a few users who could benefit from it. Will use it for testing and to monitor how it behaves under load, if there is enough use to cause load.
One thing I learned about available bandwidth while setting up relay server on AWS VPC is that there are two types of gateway: NAT gateway and internet gateway. While using internet gateway allows you to use full bandwidth capacity of the relay server host, it is very expensive. If you use NAT gateway, all your relay servers will be behind this NAT gateway, which becomes a bottleneck for bandwidth. This is actually 101 for setting up VPC on aws but I was also trying it for the first time.
I setup relay servers behind NAT gateway, and observed little increase in sync speed(~ 100 KiBs) compared to using community provided relay servers. Kudos to the community
The only reason I have to setup own relay server is because at times, during larger sync requirements, the speed drops to few bytes per second. I tried to restart syncthing on both ends but it still got connected to same overloaded relay server. (Can anything be done about it ?)
I could confirm that relay server was bottleneck because I ran rsync between same destination which happened at normal speed.
I was checking in on my little relay and unfortunately the machine rebooted for security updates about two weeks ago - I was aiming for longer uptime. Anyway, at the moment it’s somewhere around a third down the list of relays (sorted by active sessions);