Wow, you had quite a discussion while I’ve been sleeping. Let me add to this by a nice and lengthy post.
Let me try explain better my motivations for the changes I want to introduce. This will hopefully help you better understand the need. Unfortunately, I’m not allowed to tell which company I work for, so I’ll have to dance around the topic a bit.
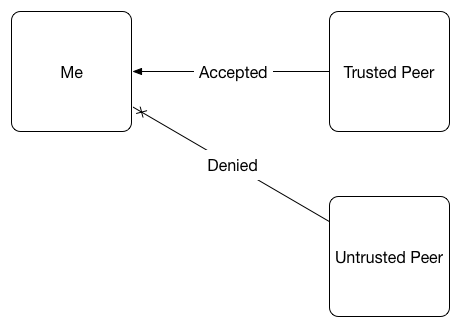
First of all, you keep talking about users. I completely agree that in the scenarios where it’s just a bunch of users sharing “stuff” on their home computers, you have to be a bit more careful. In my case we don’t talk about that. We have a desperate need to synchronize a lot of files across a lot of locations (~1200). Initiall,y these files are going to be yum repos for local server provisioning and patching, application artifacts, and database dumps. All these files will only get pushed “down stream” and we have to ensure that these files are exactly what they’re supposed to be. Yes we will absolutely have file permissions set correctly, but that’s only one piece of the puzzle. We can’t have to risk that an intrusion into one of the locations or simply somebody doing something stupid, gets replicated to every other location.
Due to the large number of devices, we’ll be setting up a tree structure with 3 levels. The top level will be where we are going to maintain the files. That’ll be at least 2 devices, split over at least 2 data centers, with several folders in RW mode. This way we have some load distribution, but more importantly, have high availability and disaster recovery in case one of the data centers has an outage.
The middle layer will be purely for load distribution. We’ll have at least 4 nodes in each data center, all of them connected to both top level nodes (to be able to handle HA and DR on the top layer). This layer already needs the “slave” folder type.
The bottom layer will be our 1200 locations. Here we will also need the wofolder type.
We have to absolutely ensure that the correct files, and only those files, exist in those folders. If something is not right, then we need to be alerted (events) and it needs to automatically correct itself. We have to deal with SOX and many other audit and security requirements. We can’t have anybody deal with this manually. Even initiating the override via API doesn’t make a lot of sense.
For our prototype, we currently use rofolder and rwfolder types on the same underlying directory on the middle layer. This helps us ensure things only get pushed down stream. It’s a clunky solution, doubles the CPU load, and introduces who knows what in weird behaviors. Unfortunately it also doesn’t allow for the automated recovery and alerting if something isn’t right. This is why I decided to spend my personal time to work with you guys and introduce the couple features I’m missing.
We also have the need to sync files back to the corporate data center. For that, we will at a later point in time, introduce the pushing of files “up stream”. We’ll be using dedicated folders for that. This also has to be all automated, since no humans are involved.
For everything we’re looking for, rsync is out of the question.
I was extremely excited when I came across Syncthing. It provides most of what we need already. We just need to get the tool to a point where it supports corporate environments. We will have users controlling it, who actually know what they’re doing. Put the decision power into their hands.
For the end user, he/she is already getting warned for what it means to put a folder into slave mode. You can’t make everything muppet proof. If a sign says “hot surface - do not touch” and somebody touches it anyway, what can you do?
You got a great tool, it just needs a little bit of tweaking from my view point.