Ok, I’ve done the test. This post is going to be rather large with a few screenshots, I apologize. Please trim this post if necessary.
So this is exactly what I’ve done. First thing I upgraded syncthing to v0.11.16, (was on 0.11.13 before) both NAS and PC. Next, I unshared all folder but 20_Outlook. Why? Because I wasn’t syncing for a week due to adding ~500GB of photos and giving NAS time to index. But I kept working on my PC. I sync all of my virtual machines ~250GB and I didn’t want them to start syncing for this test. So I decided to sync only one folder.
After running the test I think this might have contributed a lot to the overall result. For start, the initial index exchange was quick, only ~4MB exchanged, normally it is a lot more.
Now, log files. Synology NAS doesn’t have vmstat so I used dstat, I hope that it will do.
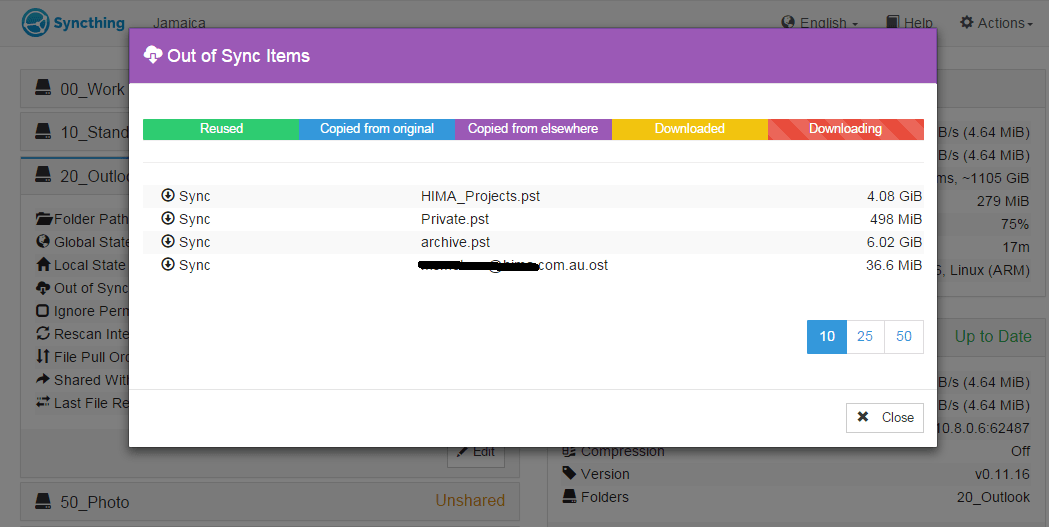
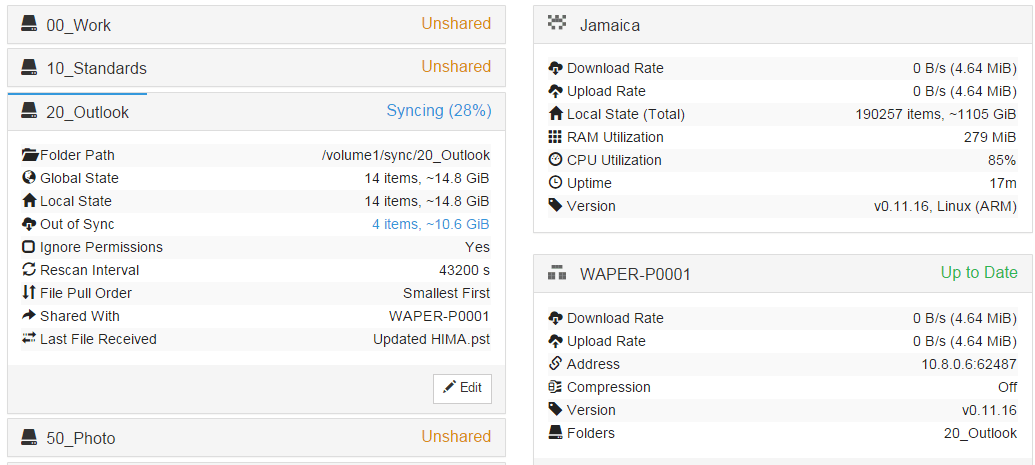
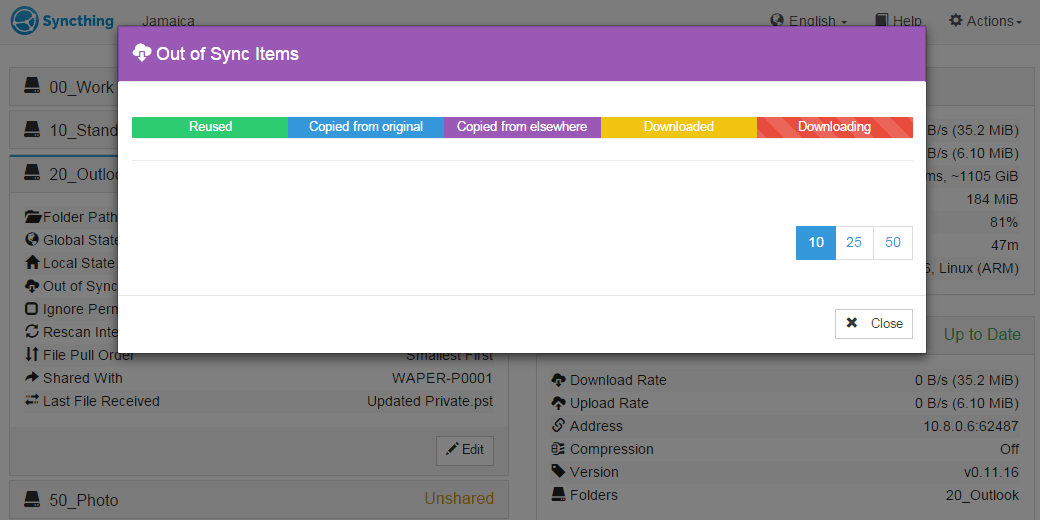
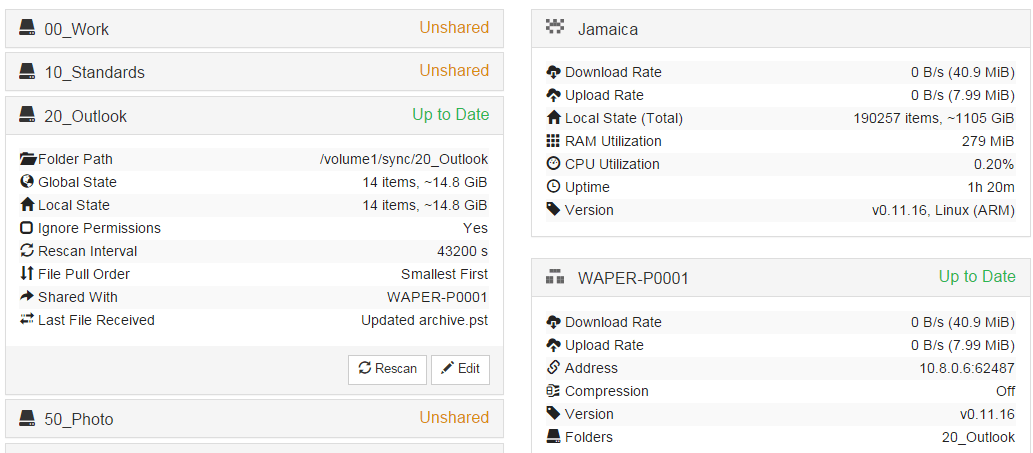
At the beginning of the sync (17mins after restart) the GUI shows 4 items, ~10.6GB not synced, at this time pop-up window shows 4 files but no progress (no colors shown).
Pop-Up:
GUI:
At this time dstat and iostat files were taken.
dstat file:
[http://6b64f54dfd098fb3.paste.se/][1]
iostat file:
[http://fcd05774d464f10a.paste.se/][2]
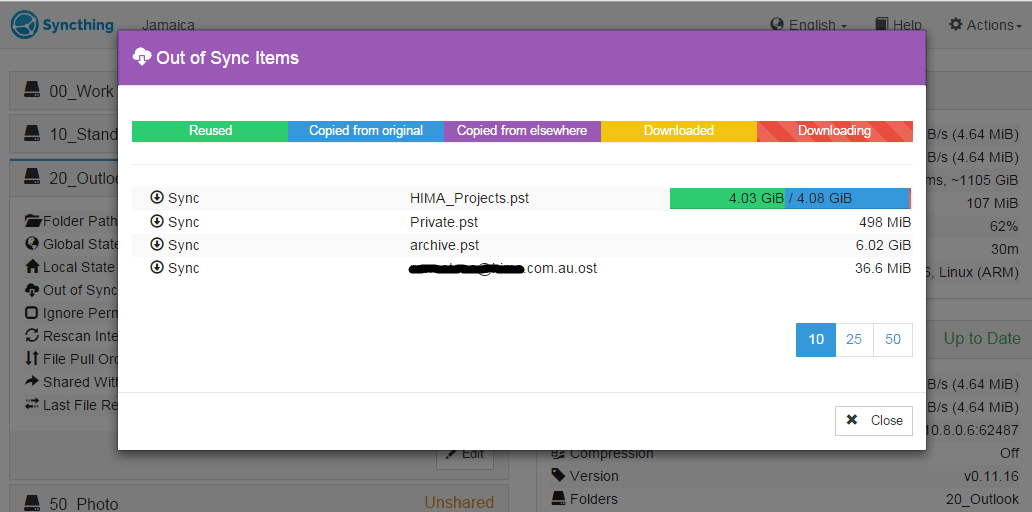
I have to say that this time the progress was reasonably quick, 4GB file synced in 30min. You can see in this screenshot that only 4.64MB were transferred so I’d say pst files are good for incremental sync, i.e. no append in the beginning / middle.
You can also see that RAM usage goes down at some point after restart from 279MB to 107MB.
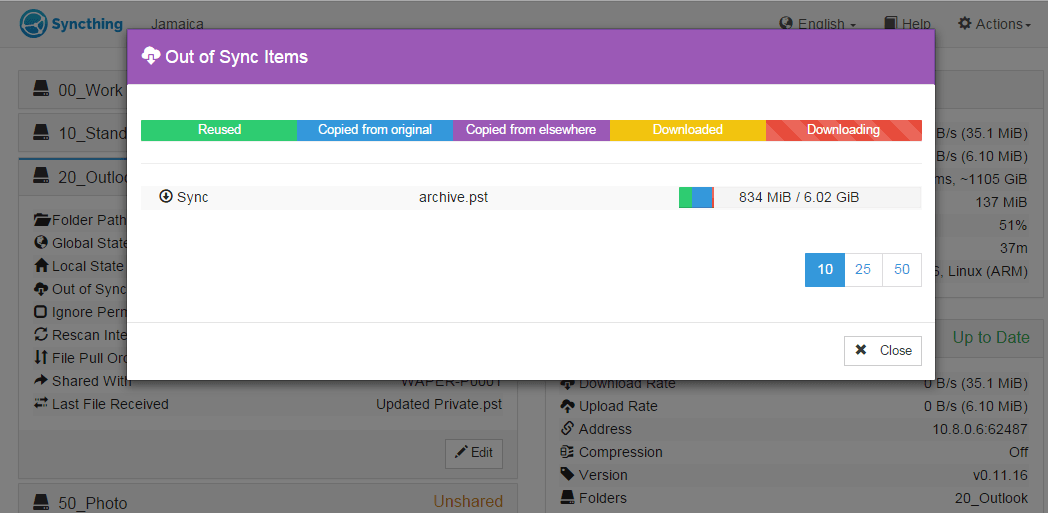
I took another stat files while syncing the last file:
dstat file 02:
[http://0248fdc05fa4a256.paste.se/][3]
iostat file 02:
[http://b9aab00abd99ee89.paste.se/][4]
Then, at some point around 47min I lost the pop-up info. I’m not sure why and if this is of any relevance, but this happens to me quite frequently.
The GUI was then frozen for at least 10mins. How do I know? The uptime was frozen at 47mins. So I closed the GUI and opened again. But by the time all folders were scanned (so that folders wouldn’t show “Unknown” status) the sync has finished.
All in all synced in 10GB synced in 1hr 20min. At this point RAM went again up to 279MB. Now as I write it is down to 60MB, CPU@0.1%.
Still the question remains, why it takes 30min to copy 4GB locally when doing the same command (or is it the same?) on the box takes only 4min? (I just ran the above cp/openssl command on the 4GB HIMA_Projects.pst)
I also assume when I now enable all folders and start syncing 1105GB, the situation will be a bit different. One note though. I use NAS only as a mirror so all scan times on NAS are set to 43200s to take it easy on NAS. I don’t have a lot of files changed during one day. Outlook pst changes daily, virtual machines not really and I add/modify only a handfull of small files a day. So what I’m saying is that except of outlook the system is nearly always in sync.
I will try to do another test once all my folders are sync and then I will run the above with all shares enabled to see if there is a difference but I assume there will be, because that was my experience so far…and now I even added 500GB of photos:)
[1]: http://6b64f54dfd098fb3.paste.se/
[2]: http://fcd05774d464f10a.paste.se/
[3]: http://0248fdc05fa4a256.paste.se/
[4]: http://b9aab00abd99ee89.paste.se/