Well, I did a post on logging a while back and, if I recall correctly, you said the solution is in line with strace or running the program with flags. To the user, it means he has to know those flags and has to spend some time to find the instructions somewhere on forums as to what to do, which is a grand loss of time for nothing.
Also, debug level logging is not qute what I am talking about here and in that post (btw, I can dig it up if you care to look at what was proposed).
Well, ultimately, it is for you to decide. I can only suggest a slightly different angle to look at things if I have some idea.
Well, actually, that is exactly what I did. I removed those files from the file system on the r/o node (win7) and that is probably why I started getting these error (warning) messages. May be it has nothing to do with that disk going flaky. It was just a coincidence.
I am at a loss as to what should I remove and where? These files are fetched by Syncthing to that share. BTSync does not copy those files. Actually, I just removed everything from the .stlversions and restarted Syncthing and am still getting the same exact warning message.
Update 1:
Well, this is funky. I just added these rules to .stignore (on r/o side/Win7):
And after I have restarted syncthing, now I no longer see that warning.
The last message in the command box (stdout) I get is:
Completed initial scan (rw) of folder Folder_name.
So, it seems to be running fine.
So, on the side where syncthing says it isn’t making progress, because it can’t remove the directory that I mentioned above, that’s where you want to delete it yourself instead. If it’s already deleted on the other side, syncthing shouldn’t be trying to fetch anything from there.
In general I have a feeling that ignored files have a few nasty side effects currently that ought to be handled better…
As for logging, I’m sure we could make some improvements there as well. Currently the entire setup is quite Unix-centric in its reliance on stdout and environment variables. And there’s always a trade off between showing unnecessary crap and hiding useful info.
OK, I’ll play with it, except that is what I did (on r/o side).
But see my previous post as to adding the entries to .stignore.
Well, the ignore should work like a tank and behave in precise and predictable way as far as I can see. In huge shares with tons of files this could be a killer if something does not work the way you think it should. And ignore rules should be powerful and flexible enough to accommodate for anything. But hey, these are “bells and whistles” level issue.
That is the problem. I don’t think using stdout for communicating any kind of status/progress messages is such a good idea. Because it will quickly become looking like a pile of useless garbage.
About the only thing it is good for is reporting a fatal errors. Anything else should go into the log files. Because log files could be as big as you want without any problem. And if you do not report every little tini-mii thing in it, but simply report the important things, such as indexing, state of the database and other states, communication establishment (may be), nodes coming and going, file transfers, state of completion, then logs become a treasure.
The way I did it on my last project on which I worked for about 10 years, is the logging is done to a text file and it is created automatically, without any user intervention on per session basis, file name date stamped, so you can look at other history logs and see the previous sessions.
If there IS such a log, then I do not mind to just open it in notepad++. It does not have to LOOK pretty. But it does have to be as informative as possible, so the user has a complete and reliable picture of the progress of things, even if that file is tens of megs big. It does not really matter. You just time stamp things in it and start each log message with easily identifiable string that tells you the level of detail or severity of the issue.
So, what I have is keywords, such as ERROR >>>, or WARNING: >>>>>
The number of right arrows tell you the level of importance or severity. So, you can just look at all the messages with ERROR and four right arrows and you get ALL the severe situations without even scrolling the entire file trying to see what is right and what is wrong.
And, probably the most important aspect is that the process should not just conc out or stop, even if some transfer can not be competed or was aborted for some reason, unless it is a FATAL level situation which broke the whole engine. What I do even in cases where I see some file or record in it is wrong and could not be parsed correctly, I just display all the vital identifying information about it so that it could be found in the source and fixed. But the process does not abort, even if half of your database looks funky. Not sure how much it is applicable to your situation.
Because you may have a huge share and just because of a single funky file you abort the whole thing, while, as far as sync process goes, you might have 99.9999% of the rest of the data in correct and perfect condition. As long as you clearly identify the error condition and provide the exact locations of things, including full paths (because there might be several files with the same name but belonging to different shares and located in different locations), and, the exact problem why the thing did not work.
Also, I find the status of completion is important. For example, you have started to send file /path/file_name to node so and so. But it got stuck for whatever reason, or, possibly, have aborted or timed out. So, would not you like to know that?
Or, file transfer started then … and the “completed OK”. Except this could be tricky to display on a single line since you could have multiple transfers to multiple nodes. But at least you know that you have started or attempted to start the transfer, and once it completed, you just log another message “…completed OK”, or “aborted, and a reason”, such as “network connection lost” or “file not available” or “file looks damaged” or whatever the complete and full description of the situation is.
I have not idea what makes sense to you, but what I did for my project I have never had regrets for and I have never seen the case, error or not, where I could not figure out what is going on at ANY given junction or with any given operation, major or minor.
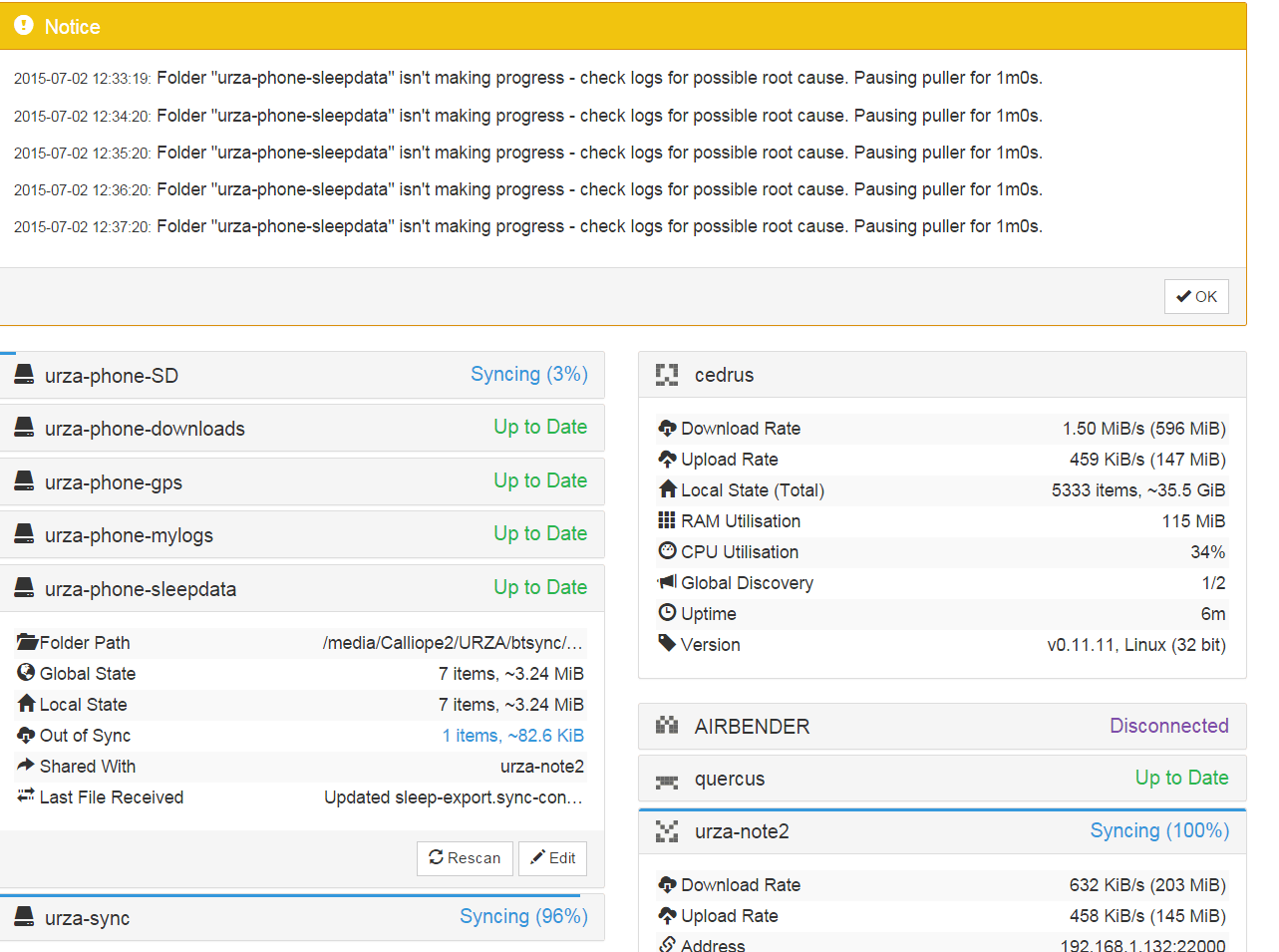
I have the same problem syncing folder from android to PC
on the PC side is says “Folder “xxx” isn’t making progress - check logs for possible root cause. Pausing puller for 1m0s.”…
When I click on the link of “unsynced files” in the web GUI for that folder… it shows buch of files, one .csv, one .db and many .jpeg files… what should I do?
It turned out I was facing the same issue, it all boiled down to a single file on my linux box that was owned by root, while syncthing was running as a user that wasn’t allowed to make changes to the file.
But as far as I can tell, that is not always the only cause. I experience some of these problems (linux <-> android syncs) but the culprit are not files owned by root.
This is the most frustrating part with ST. It throws errors and stop syncing. I have like 12 nodes and how would I know which one is really causing the problem. I think that ST should report it but it should sync as much as rather than being pissed and stop synching.
One folder is on android and it is synced to server. On the server nothing was manually changed, the files are always modified on android (it is kind of my backup)