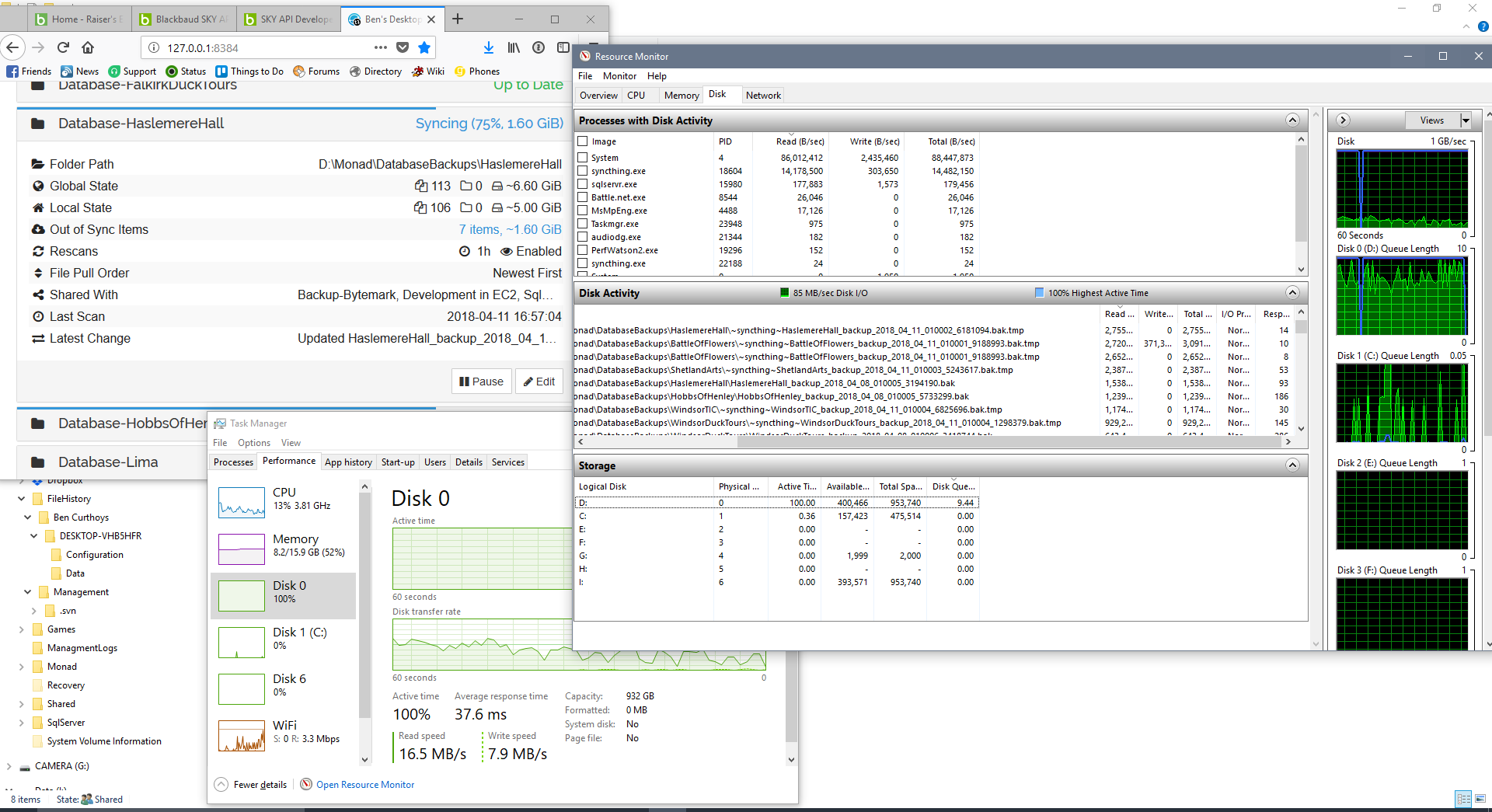
By the time we’ve got this far - a partial download of a big file - I can see how it’s saturating the disk bandwidth checking what we’ve downloaded already. I’m not 100% sure that’s the only problem though, or it wouldn’t be an issue when I turn my machine on in the morning, because at that point I’ve got gigabytes of files waiting on servers to be downloaded, but nothing locally that needs scanning before the download can start.
Anyway. I can live with it. I can’t speak Go so I’m not going to fix it myself. I would have hoped that forcing it to scan one folder at a time would not require heavy lifting like a scan queue - just a mutex (or equivalent) on an object that says “I’m busy scanning a folder don’t start a new one” and all the other folder processes just wait and retry at random until they’re all done. I don’t care what order folders are scanned in, I just don’t want all 20 to kick off at once and kill performance for the next 6 hours when they could be done in 1/10 then time running one at at time. But not knowing the code base such hopes are worth less than nothing.
If help reproducing the problem is help worth having then I gladly offer that though.
There is nothing to reproduce here, someone just needs to implement something.
In an ideal world, we’d check the device on which the folder lives.
Benchmark throughput for the device (with 1, 2, 4 parallel reads), and then have semaphore per block device with that many takers, and get folder scanners to acquire the semaphore for that device.
I’d skip the benchmark and just make it configurable for those who care. While keeping in mind that some scans need to proceed anyway (those we do by necessity while syncing) and that being blocked on a scheduled scan probably shouldn’t block syncing, and a few things like that.
I was thinking about implementing it in a way that just limits concurrent hashers globally (or by block device/partition if possible) - i.e. still all scan request go trough, nothing is blocked, just limited in concurrency. But then I started reading up a bit on fast disk access and all the talk was about sequential programming. Concurrent access was considered unproblematic, as the underlying systems (fs, hardware) do optimize disk access. So I’d think more parallel request means more optimization and restricting parallel scanners should make things worse. However that’s contrary to observations and discussion we have. Therefore I either got something wrong or the problem isn’t with disk access, but within the Syncthing code in case of multiple parallel scans. Can someone englighten me?
But then I started reading up a bit on fast disk access and all the talk was about sequential programming. Concurrent access was considered unproblematic, as the underlying systems (fs, hardware) do optimize disk access.
Just a reminder - it might just be my hardware. I’ve got a new hard drive on order, so let me make sure that swapping that out doesn’t sort it before we start headscratching too hard =)
Sequential read access is much faster than random, on spinning disks. Some filesystems optimize with efficient readahead to limit the damage, but still.
But this is expected. Syncthing is trying to reconstruct a large file. It does that by reading and writing. The disk is trying to provide reads and writes as fast as it can. That means 100%. You would see the same just by copying a large file. What are we debugging here?
If you have 1 folder with 10 large files, SyncThing scans and hashes and syncs them one at a time, using all the available disk bandwidth but making progress.
If you have 10 folders with 1 large file each, SyncThing scans and hashes and syncs them all at once, thrashing the disk read head around from one file to the next, using all the available disk bandwidth but also causing a long disk queue and not making progress.
That is also my observation when Syncthing scans 20 folders at the same time (e.g. during startup). Later during normal operation it is not that significant because my folders don’t have so many (big) changes like @Ben_Curthoys or they don’t happen at the same time.
Yeah, but not just a bit slower. At least 2 orders of magnitude slower in my experience.
Manually limiting it to just one folder at a time by pausing everything else means it takes ~30 seconds to get the first folder syncing (and once it’s syncing, the disk is no longer the bottleneck - it’s the internet bandwidth, which is what you’d expect). When it’s all the folders at once, it can take hours before the sync even starts making progress.
The thing is, that even if the folders were on separate physical drives and there was no disk bottleneck on how many we wanted to scan at once, once they’re all scanned and actually start syncing, the chances are that the network will be the limit anyway*. And once all the folders are ready to sync, I’d still rather they synced one at a time: it’s always going to be more useful to have one file complete and one not started, than two files half finished.
This is obviously how it already works within folders. It would be great if could work this way between folders.
/ * Except where I have unlimited bandwidth and I’m downloading each folder from a different host each of which has limited bandwidth. I guess if you were running a syncthing server in the cloud with 20 folders, each folder shared between the server and 1 machine out there on the internet, you’d want the server to do them all at once. But that’s a very on/off scenario.