Sorry for thread hijacking, just wanted to chime in that I encountered similar things on upgrade to 1.6.0-RC.1 and RC.2.
Initially, after upgrading to 1.6.0-RC.1 (on a single Windows device) I also got the message “Non-increasing sequence detected: Checking and repairing the db…”. As everything looked okay, I did not take any further actions.
A while later I looked at the GUI of the Windows device and it showed a single remote device out of sync, with about 3 files apparently not synced. The remote device on the other hand claimed to be up to date, which seemed to be correct.
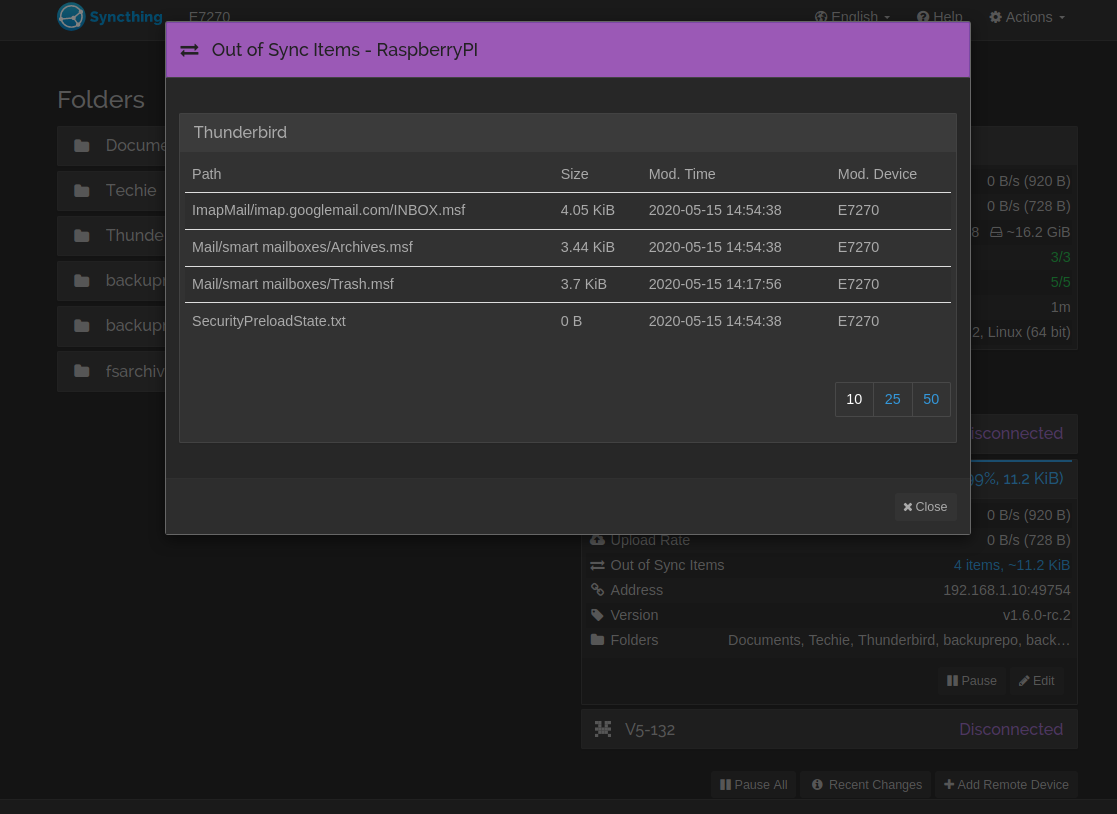
After upgrading to 1.6.0-RC.2 I got the message again (I think - at least I remember clicking the yellow warning box again), and again the Windows device showed 5 files out of sync for a remote device - which again, seems to be just a visual thing, I believe everything is synced just fine. The “apparently” not in sync files were different from those shown on RC.1, but from the same (syncthing-) folder.
However, after a couple of reboots, it seems that the out of sync items have changed again: Now the remote devices dialog claims that 2 items are out of sync, for a single remote device. When I click on the out of sync list, it just shows a single item - from the same folder as above.
Just for fun, I ran stindex -mode idxck on the Windows machine and it printed ~hundreds of lines like this (it only outputted such lines, completed with a final line concerning GC):
Missing need entry for needed file "Eclipse_Oxygen/features/org.eclipse.egit.mylyn_4.9.2.201712150930-r/META-INF/ECLIPSE_.RSA", folder "hxbhn-gsktf"
I did random samples on the mentioned files and every tested file was actually non-existent on the local device - the printed files all seem to be old files that have been deleted long ago. They’re from at least five different folders.
As stuff seems to work okay from my perspective I haven’t touched anything expect running stindex just now. If you want to debug something out of this setup I’m fine with that, otherwise I will just leave it as-is and check if it blows up at some point.