My laptop with the ~111,000-file Maildir directory has a dual-core CPU (circa mid-2013) – calling it “fast” would be generous. ![]()
(And the file server at work that had the 1.8 million file Maildir directory has a quad-core CPU.)
My laptop with the ~111,000-file Maildir directory has a dual-core CPU (circa mid-2013) – calling it “fast” would be generous. ![]()
(And the file server at work that had the 1.8 million file Maildir directory has a quad-core CPU.)
good idea, testing it right now as ‘phase 5’.
FYI phase 4 (cryptsetup && COW OFF for DB) shown no improvement in Scanning phase (105 min), and no or small improvement in Syncthing. It might be that Syncthing is 50% faster (manual observation on webgui), but it still being slow ( below 100KB/s for sure) ![]()
bingo @bt90
enabling case sensitivity, which on my case sensitive FS is fine solved problem.
Scanning: 3 minutes (was 105) Syncing: around 15MB/s and moving fast.
I stopped it manually to have some files for experiments tomorrow, with slowly moving back to defaults all settings from today.
thank you @bt90 for being persistent with my problem, I appreciate it!
I never thought that the case-insensitive handling would add that much overhead ![]()
Would you mind capturing a CPU profile with the case-sensitive option still disabled?
https://docs.syncthing.net/users/profiling.html#capture-a-cpu-profile
so, here are some results && initial conclusions, probably some of you can add more.
enabling caseSensitiveFS (which is not default in syncthing), reduced Scanning time from 105 minutes to 3 minutes, and Syncing was more/less very fast.
after it, syncthing is still cpu constrained during Scanning, but time needed to complet Scaning (and later Syncing) is not only acceptable, but I would say fast, in regards to amount of data (380k files with long filenames (sic!) i.e. maildir) being processed.
syncthing still is using only one core (per folder) during Scanning, and my guess is that with caseSensitiveFS=true, now the os.readdir is main culprit. It may be, or may not be, due to the logic further optimized in syncthing, nevertheless: 3min is fast so I would say: not worth it.
some of configuration changes were good in general (setLowPriority=false, databaseTuning=large, Changes, copyRangeMethod), which helped to speed up Scanning from initial 160min to 105min. I’m keeping them.
the biggest single winner of course is caseSensitiveFS=true
I reverted to default disableFsync (being false). While it would provide some speedup (during Syncing) it’s not worth the risk.
many settings I tried had no effect (or to small to notice) on my machine, due to constraint being on CPU, not IO or due to the fact that only 1 core was used or due to the specific makeup of my data (maildir). I reverted them to defaults: disableTempIndexes=false copiers=0 hashers=0 maxConcurrentWrites=2 SendReceive fsWatcherEnabled=true
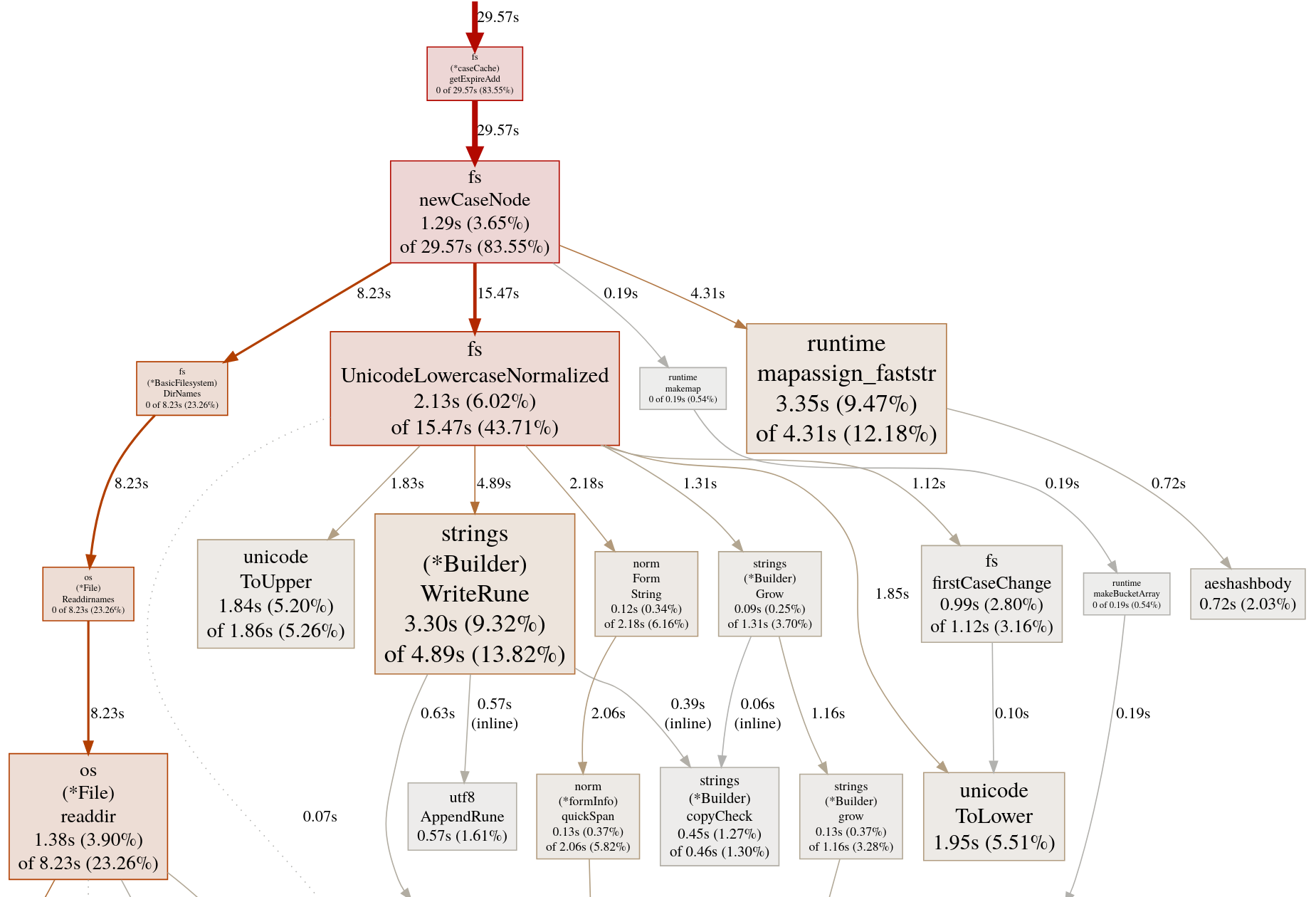
Attaching pprof file for the caseSensitiveFS=false scenario, here is quick peek for the impatient ones
syncthing-cpu-linux-arm64-v1.27.2-180504.pprof (23.7 KB)
![]()
(pprof) top
Showing nodes accounting for 24.80s, 69.66% of 35.60s total
Dropped 262 nodes (cum <= 0.18s)
Showing top 10 nodes out of 73
flat flat% sum% cum cum%
4.74s 13.31% 13.31% 4.74s 13.31% runtime/internal/syscall.Syscall6
3.41s 9.58% 22.89% 5.17s 14.52% strings.(*Builder).WriteRune
3.29s 9.24% 32.13% 4.29s 12.05% runtime.mapassign_faststr
2.95s 8.29% 40.42% 3.46s 9.72% runtime.findObject
2.15s 6.04% 46.46% 15.69s 44.07% github.com/syncthing/syncthing/lib/fs.UnicodeLowercaseNormalized
2.02s 5.67% 52.13% 2.02s 5.67% golang.org/x/text/unicode/norm.(*input).skipASCII (inline)
1.85s 5.20% 57.33% 1.85s 5.20% unicode.ToLower
1.79s 5.03% 62.36% 1.79s 5.03% unicode.ToUpper
1.30s 3.65% 66.01% 29.61s 83.17% github.com/syncthing/syncthing/lib/fs.newCaseNode
1.30s 3.65% 69.66% 8.03s 22.56% os.(*File).readdir
@rdslw thanks for the pprof and your detailed summary. Feel free to open a Github issue as there might be room for improvement (105min vs 3min!).
@rdslw one last thing: could you also gather a heap profile?
https://docs.syncthing.net/users/profiling.html#capture-a-heap-profile
I’m fairly sure that the problem with case insensitivity is not the CPU or RAM used for the checks, but the repeated recursive listdir:s to figure out proper casing. Especially for large directories listdir can take a really long time (in computer terms). We could potentially do more aggressive (=longer) caching of the results.
We could also add a fast path for ASCII only filenames which are quite common.
nfc(lower(upper(filename))) is equivalent to lower(filename) for them.
Quick draft: lib/fs: Add ASCII fastpath for normalization by bt90 · Pull Request #9365 · syncthing/syncthing · GitHub
I am really glad having found this thread, because it saved my weekend after hours of debuging. ![]()
My setup is similiar: syncthing running in a docker container on an unraid server with all the performance overhead caused by btrfs on luks (plus unraid’s shfs on top). Also the CPU is rather old.
The Maildir is 4 GB with 142526 files in 234 directories. Synchronisation takes forever (“days”). With caseSensitiveFS=true speed is also slow compared to other folders, but synchronization finishes in about 30 minutes at least.
My pprof shows a similar behaviour as the one @rdslw provided. I never thought that it could be related to string comparison. Thanks for sharing the workaround. You do a great job with syncthing!
Here are the pprof files for CPU and heap in case that it is interesting:
pprof.zip (685.7 KB)
The files in the folder “scanning” is taken during scanning phase, the files in the folder “synchronization” in the syncing phase. folders with a “2” contain the pprof with the setting caseSensitiveFS=true.
Out of curiosity: It seems that it is not only related to the performance impact of the string comparison logic in syncthing. Does the case-insensitive string comparison also trigger additional I/O?
I guess with a faster setup (CPU, disks, etc.) I would have not noticed anything.
Already pointed out by @calmh
Your profile is actually quite a bit more in line with expectations: The majority of time is taken up by syscalls, the actual string comparison/mangling isn’t taking up much time. Incidentally most time is spent stat-ing files outside of the case-sensitivity machinery. Maybe the profile just got (un)lucky timing with lots of cache hits? @rdslw 's profile is quite astounding in that respect, as most time is spent in string manipulation. And a big amount of that with memory management, including GC.
What might help with everything is different caching as mentined by calmh. Would be nice to add some (optional/debugging) metrics to measure how often we hit the cache or not for the same path. Worst case we are already doing a good job, and there are no cache misses on the same paths, but maybe there are and improving the cache retention mechanism (or simply extending lifetime) could help.
Few things to add.
My system is musl based, so this my be the reason for slow string comparison if golang is using some sort of non-optimal multiple calls to musl lib ctypes/isupper/islower etc, while musl is slower in this regards to glibc.
Also: maildir filenames are typical 78 chars long (longer than typical filename), and are quite similar which may create a lot of collisions if hashmap/hashing/caching of them is used while not prepared for high degree of similarity with huge number.
Nevertheless I wouldn’t dismiss os.readdir/listdir calls by syncthing. How loop/algo uses them now might be a place for some optimization (cache etc) as there were a lot of them (too many?).
This specific directory of mine, if scanned now (with proper settings) takes:
yes, there is a difference, but not so big.